Oracle树查询,start with connect by prior 递归查询用法(转载)
本人觉得这个写的真不错,实用性强,就转载过来了
这个子句主要是用于B树结构类型的数据递归查询,给出B树结构类型中的任意一个结点,遍历其最终父结点或者子结点。
先看原始数据:

1 create table a_test
2 ( parentid varchar2(10),
3 subid varchar2(10));
4
5 insert into a_test values ( '1', '2' );
6 insert into a_test values ( '1', '3' );
7 insert into a_test values ( '2', '4' );
8 insert into a_test values ( '2', '5' );
9 insert into a_test values ( '3', '6' );
10 insert into a_test values ( '3', '7' );
11 insert into a_test values ( '5', '8' );
12 insert into a_test values ( '5', '9' );
13 insert into a_test values ( '7', '10' );
14 insert into a_test values ( '7', '11' );
15 insert into a_test values ( '10', '12' );
16 insert into a_test values ( '10', '13' );
17
18 commit;
19
20 select * from a_test;
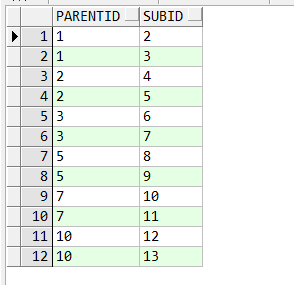
对应B树结构为:

接下来看一个示例:
要求给出其中一个结点值,求其最终父结点。以7为例,看一下代码
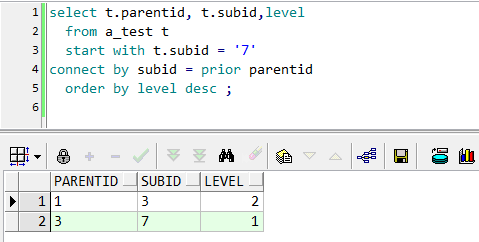
start with 子句:遍历起始条件,有个小技巧,如果要查父结点,这里可以用子结点的列,反之亦然。
connect by 子句:连接条件。关键词prior,prior跟父节点列parentid放在一起,就是往父结点方向遍历;prior跟子结点列subid放在一起,则往叶子结点方向遍历,
parentid、subid两列谁放在“=”前都无所谓,关键是prior跟谁在一起。
order by 子句:排序,不用多说。
--------------------------------------------------
下面看看往叶子结点遍历的例子:
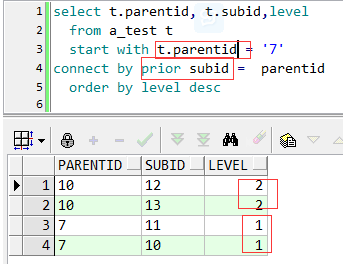
这里start with 子句用了parentid列,具体区别后面举例说明。
connect by 子句中,prior跟subid在同一边,就是往叶子结点方向遍历去了。因为7有两个子结点,所以第一级中有两个结果(10和11),10有两个子结点(12,13),11无,所以第二级也有两个结果(12,13)。即12,13就是叶子结点。
下面看下start with子句中选择不同的列的区别:
以查询叶子结点(往下遍历)为例
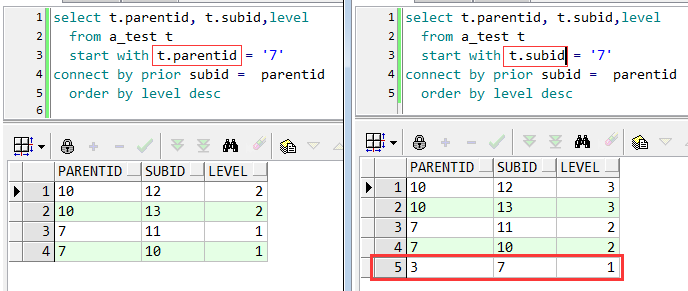
结果很明显,原意是要以7为父结点,遍历其子结点,左图取的是父结点列的值,结果符合原意;右图取的是子结点列的值,结果多余的显示了7 的父结点3.
---------------------------------------
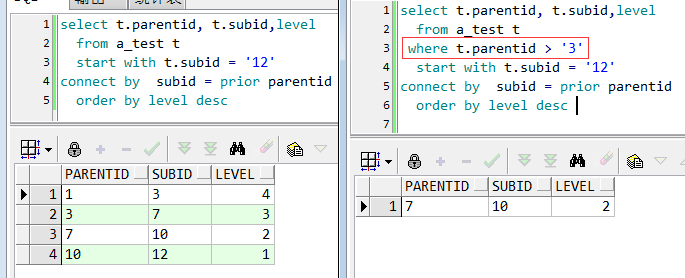
关于where条件的语句,以后验证后再记录。先留个疑问
Oracle树查询,start with connect by prior 递归查询用法(转载)的更多相关文章
- oracle start with connect by prior 递归查询用法
start with 子句:遍历起始条件,有个小技巧,如果要查父结点,这里可以用子结点的列,反之亦然. connect by 子句:连接条件.关键词prior,prior跟父节点列parentid放在 ...
- start with connect by prior 递归查询用法
这个子句主要是用于B树结构类型的数据递归查询,给出B树结构类型中的任意一个结点,遍历其最终父结点或者子结点. 先看原始数据: create table a_test ( parentid ), sub ...
- start with connect by prior 递归查询用法,很实用
当开发过程需要查询上下级机构类似的树形机构,还有就是查询当前等级下的所有所属节点 这个子句主要是用于B树结构类型的数据递归查询,给出B树结构类型中的任意一个结点,遍历其最终父结点或者子结点. 先看原始 ...
- oracle递归层级查询 start with connect by prior
递归层级查询:start with connect by prior 以部门表作为解析 表结构:dept{id:'主键',name:'部门名称',parent_id:'父亲id'} select * ...
- SQL基础-->层次化查询(START BY ... CONNECT BY PRIOR)[转]
--====================================================== --SQL基础-->层次化查询(START BY ... CONNECT BY ...
- Oracle树查询及相关函数
Oracle树查询的最重要的就是select...start with... connect by ...prior 语法了.依托于该语法,我们可以将一个表形结构的中以树的顺序列出来.在下面列述了Or ...
- oracle中 connect by prior 递归查询
Oracle中start with...connect by prior子句用法 connect by 是结构化查询中用到的,其基本语法是: select ... from tablename sta ...
- Oracle树查询总结
最近在做公司的项目中遇到一个问题,多级级联导航菜单,虽然只有三级目录,但<li>中嵌套<ul>,数据库表结构如下: CREATE TABLE FLFL ( ID NUMBER ...
- SQL基础-->层次化查询(START BY ... CONNECT BY PRIOR)
--====================================================== --SQL基础-->层次化查询(START BY ... CONNECT BY ...
随机推荐
- .net 系列化与反序列化(转载)
.net序列化及反序列化 转载自:http://www.cnblogs.com/Tim_Liu/archive/2010/11/09/1872587.html 序列化是指一个对象的实例可以被保存,保存 ...
- 记一次诡异的网络故障排除 - tpc_tw_recycle参数引起的网络故障
一.故障现象 我们团队访问腾讯云上部署的测试环境中的Web系统A时,偶尔会出现类似于网络闪断的情况,浏览器卡很久没有反应,最终报Connection Timeout. 不过奇怪的是,当团队中的某个人无 ...
- bzoj 4472 salesman
Written with StackEdit. Description 某售货员小\(T\) 要到若干城镇去推销商品,由于该地区是交通不便的山区,任意两个城镇 之间都只有唯一的可能经过其它城镇的路线. ...
- 微软SaaS多租户解决方案
微软SaaS多租户解决方案 docs.microsoft.com/en-us/azure/sql-database/saas-tenancy-app-design-patterns https://d ...
- 启动tomcat7w.exe提示"指定的服务未安装"
说下本人的情况:因为重装系统,安装在C盘的tomcat的失去作用.想要启动tomcat7w.exe(这是管理服务的)出现“指定服务未安装,无法打开tomcat7服务”的提示.原因是重装系统也导致之前安 ...
- c#模拟键盘输入
System.Windows.Forms.SendKeys.SendWait("j");
- 解决Maven报Plugin execution not covered by lifecycle configuration问题
问题: 在eclipse neon 中引入maven项目时,弹出两个错误,一个是jacco-maven-plugin,一个是项目中的插件ota-schema-plugin 如果忽略这两个错误,点击fi ...
- Python学习系列(五)(文件操作及其字典)
Python学习系列(五)(文件操作及其字典) Python学习系列(四)(列表及其函数) 一.文件操作 1,读文件 在以'r'读模式打开文件以后可以调用read函数一次性将文件内容全部读出 ...
- php中 curl模拟post发送json并接收json(转)
本地模拟请求服务器数据,请求数据格式为json,服务器返回数据也是json. 由于需求特殊性, 如同步客户端的批量数据至云端, 提交至服务器的数据可能是多维数组数据了. 这时需要将此数据以一定的数据 ...
- Ubuntu apt-get卸载小记
过sudo apt-get install xxxx 安装软件后,总是无法卸载干净,这里以Apache 为例,提供方法:首先sudo apt-get remove apache2再sudo apt-g ...