ES索引
Elasticsearch索引别名、Filtered索引别名、Template
在使用elasticsearch的时候,经常会遇到需要淘汰掉历史数据的场景。
为了方便数据淘汰,并使得数据管理更加灵活,我们经常会以时间为粒度建立索引,例如:
- 每个月建立一个索引:monthly-201709、monthly-201710、monthly-201711
- 每天建立一个索引:daily-20171015、daily-20171016、daily-20171017、daily-20171018
当不需要再继续使用历史数据的时候,我们就可以将索引删除,释放资源。
为了很好的支撑这个场景,需要使用到Elasticsearch里的两个东西,索引别名和Template。
- 索引别名:建立索引对外的统一视图
例如,如果建立了上述类似的索引时间序列,在查询的时候以wildcards的方式指定索引,例如index=monthly-*,或者index=daily-201710*。当然也可以使用索引别名index=monthly。
- Template:修改建立索引的默认配置
例如,你不想承担定期去维护索引的风险和工作量,可以在插入数据时自动创建索引,Template可以提供自动创建索引时候的默认配置。
下面详细解释一下。
1、索引别名
一个索引别名就好比一个快捷方式(Shortcut)或一个符号链接(Symbolic Link),索引别名可以指向一个或者多个索引,可以在任何需要索引名的API中使用。使用别名可以给我们非常多的灵活性。它能够让我们:
- 在一个运行的集群中透明地从一个索引切换到另一个索引
- 让多个索引形成一个组,比如
last_three_months - 为一个索引中的一部分文档创建一个视图(View)
如何创建索引别名呢?
1)创建索引
我这里创建audit-201710、audit-201711两个索引
curl -XPOST "http://10.93.21.21:8049/kangaroo-201710?pretty"
curl -XPOST "http://10.93.21.21:8049/kangaroo-201711?pretty"
如果安装了head,你可以在可视化页面看到
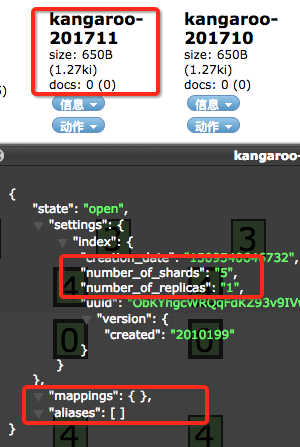
从索引信息可以看到,我们没有配置mapping和alias,shards和replicas也使用的默认值。
2)建立索引别名

curl -XPOST 'http://10.93.21.21:8049/_aliases' -d '
{
"actions": [
{"add": {"index": "kangaroo-201710", "alias": "kangaroo"}},
{"add": {"index": "kangaroo-201711", "alias": "kangaroo"}}
]
}'
这样就对kangaroo-201710和kangaroo-201711建立了索引别名kangaroo,再看head可视化
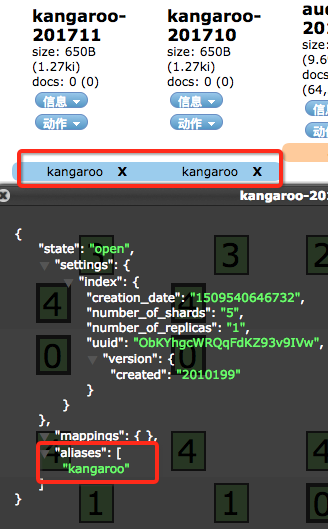
可以看到索引别名已经建立。
3)注意
写:不能直接对索引别名进行写入。所以在写数据的时候,要直接使用普通索引。
读:查询,对索引别名进行查询,查询会透明的下发到别名下挂的所有索引执行,设置的路由也会随之下发。
2、带filtered的索引别名
对于同一个索引,例如zoo,我们如何给不同人看到不同的数据,即,所谓的多租户。
假设索引zoo的数据有个字段是group,group字段记录了该数据是那个“租户”的。多租户之间的数据应该是不可见的。
我们模拟一下这个场景
1)创建索引zoo
curl -XPOST "http://10.93.21.21:8049/zoo?pretty"
2)设置mappings
curl -XPOST "http://10.93.21.21:8049/zoo/animal/_mapping?pretty" -d '
{
"animal": {
"properties": {
"name": {"type": "string", index: "not_analyzed"},
"group": {"type": "string", index: "not_analyzed"}
}
}
}'
3)设置带filter的别名
curl -XPOST "http://10.93.21.21:8049/_aliases?pretty" -d '
{
"actions": [
{
"add": {
"index": "zoo",
"alias": "zoo_animal_vegetarian",
"filter":{
"term":{
"group":"vegetarian"
}
}
}
},
{
"add": {
"index": "zoo",
"alias": "zoo_animal_carnivorous",
"filter":{
"term":{
"group":"carnivorous"
}
}
}
}
]
}'
通过head看一下
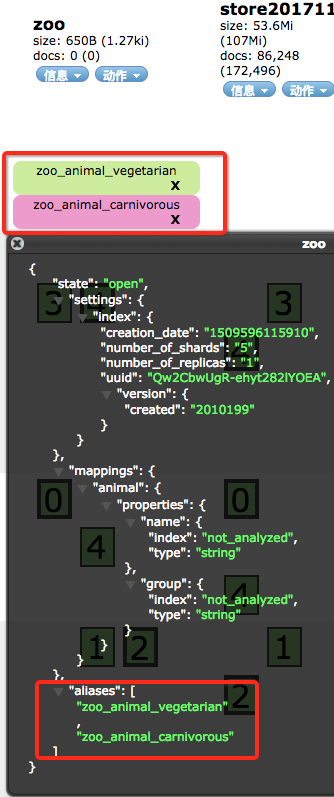
我们索引两条数据进去
老虎-肉食
curl -XPUT 'http://10.93.21.21:8049/zoo/animal/1' -d '{
"name" : "tiger",
"group" : "carnivorous"
}'
兔子-素食
curl -XPUT 'http://10.93.21.21:8049/zoo/animal/2' -d '{
"name" : "rabbit",
"group" : "vegetarian"
}'
使用带filter的索引查一下
素食的只有兔子
curl -XGET "http://10.93.21.21:8049/zoo_animal_vegetarian/_search?pretty"
{
"took" : 32,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [ {
"_index" : "zoo",
"_type" : "animal",
"_id" : "2",
"_score" : 1.0,
"_source":{
"name" : "rabbit",
"group" : "vegetarian"
}
} ]
}
}
肉食的只有老虎
curl -XGET "http://10.93.21.21:8049/zoo_animal_carnivorous/_search?pretty"
{
"took" : 33,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [ {
"_index" : "zoo",
"_type" : "animal",
"_id" : "1",
"_score" : 1.0,
"_source":{
"name" : "tiger",
"group" : "carnivorous"
}
} ]
}
}
当你建立索引时间序列的时候,遇到的问题是,需要不断的建立新索引,例如到了11月份,你可以需要新建kangaroo-201711这个索引。
当然,如果不创建索引,直接写入数据的话,ES会为你分析你写入的document的字段类型,并使用默认配置建立索引。
但是默认配置可能并不是你想要的。例如ES对string类型默认是分析的,即,对string类型会进行分词,但是你的数据中可能有一些string类型的字段不希望被分析。
那么怎么修改默认配置呢?可以创建一个template。
3、Template
template可以修改索引的默认配置。我们以下面这个template为例说明一下。
1)我们建立了一个template名称为kangaroo_template
2)"template": "kangaroo*",表示对于所有以kangaroo*开头的索引,默认配置使用template中的配置。
3)"settings","mappings","aliases",可以修改这些类型的默认配置
4)禁用了_source,对name字段设置string类型且不分析,索引别名设置为kangaroo
curl -XPUT "http://10.93.21.21:8049/_template/kangaroo_template?pretty" -d '{
"template": "kangaroo*",
"settings": {
"number_of_shards": 10
},
"mappings": {
"data": {
"_source": {
"enabled": false
},
"properties": {
"name": {
"type": "string",
"index": "not_analyzed"
},
"id": {
"type": "long"
}
}
}
},
"aliases": {"kangaroo":{}}
}'
执行生效后,看一下template生效的内容,这里注意有一个"order"字段,该字段跟多template合并有关,后面我们会讲。
curl -XGET "http://10.93.21.21:8049/_template/kangaroo_template?pretty"
{
"kangaroo_template" : {
"order" : 0,
"template" : "kangaroo*",
"settings" : {
"index" : {
"number_of_shards" : "10"
}
},
"mappings" : {
"data" : {
"_source" : {
"enabled" : false
},
"properties" : {
"name" : {
"index" : "not_analyzed",
"type" : "string"
},
"id" : {
"type" : "long"
}
}
}
},
"aliases" : {
"kangaroo" : { }
}
}
}
我们可以向一个不存在的索引写入数据,这个操作会使用默认配置,如果索引名称命中template中的规则,就会使用template的配置创建索引。
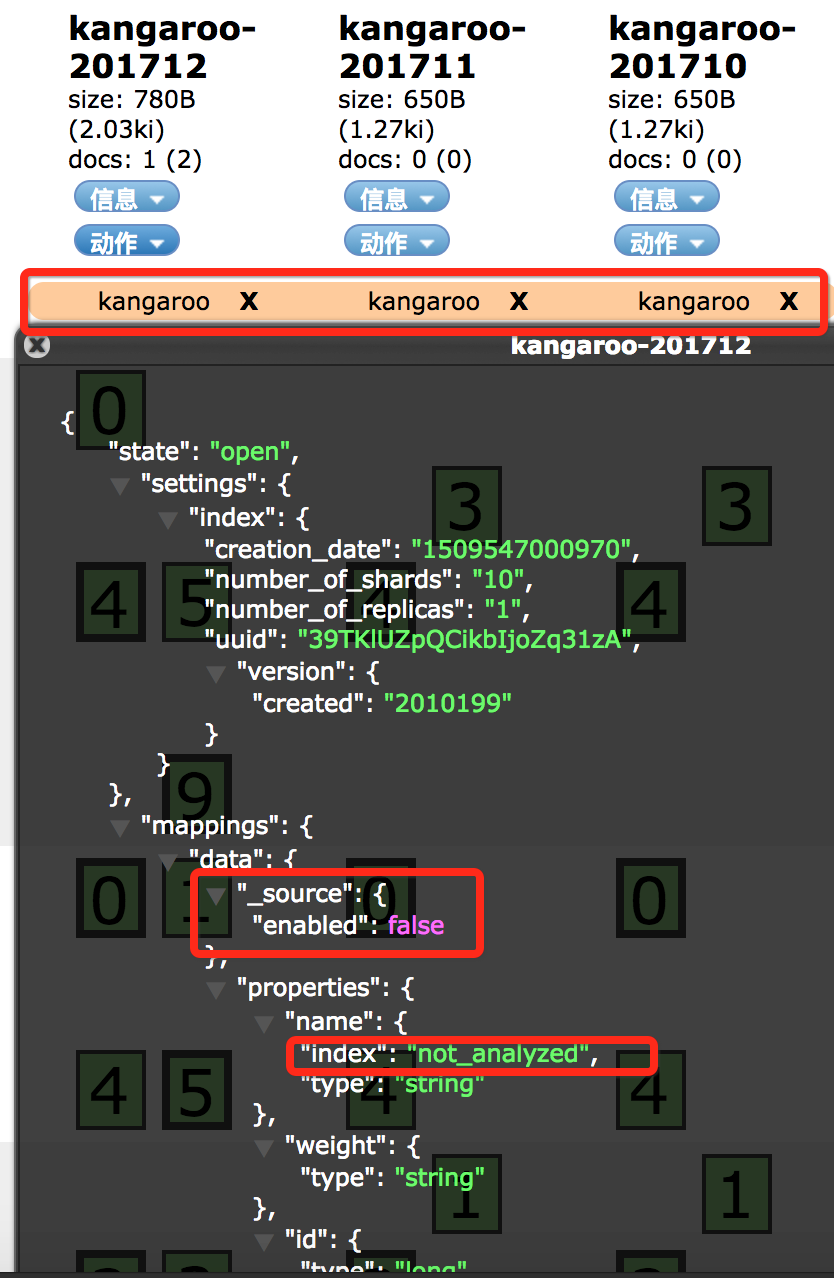
这里我们向kangaroo-201712写入数据,会命中之前创建的kangaroo_template。
curl -XPUT 'http://10.93.21.21:8049/kangaroo-201712/data/1' -d '{
"name" : "yang",
"id" : "1001",
"weight" : "70 kg"
}'
通过head看一下,可以看到,索引别名已经建立,分片数=10,source禁用生效,name不分析。这就是我们想要的结果。
多个template配置的合并
这个场景是这样的,一个索引命中了多个template配置,例如:有两个template配置分别为:a*, ab*,那么如果有一个索引名字是abc,就会命中了两个template,这时候会怎么样呢?
配置会merge,merge的法则可以参见官方文档,简单来说,就是跟order值有关,较小order值的配置会先生效,较大order值的配置会继而覆盖。
ES索引的更多相关文章
- 数据源、数据集、同步任务、数据仓库、元数据、数据目录、主题、来源系统、标签、增量识别字段、修改同步、ES索引、HBase列族、元数据同步、
数据源.数据集.同步任务.数据仓库.元数据.数据目录.主题.来源系统.标签. 增量识别字段.修改同步.ES索引.HBase列族.元数据同步.DS.ODS.DW.DM.zk集群地址 == 数据源 数据源 ...
- kibana添加ES索引403错误解决
kibana添加ES索引时发现kibana添加索引不生效,没有创建成功只是一闪而过 查看控制台发现报错403 解决办法: curl -XPUT -H "Content-Type: appli ...
- 使用es索引遇到的问题记录
1设置es索引的运行内存: 直接在启动文件里面改就好,启动命令是elasticsearch.bat,用notepad++编辑这个文件,里面添加这样的一行:SET ES_HEAP_SIZE=10g即可 ...
- 创建es索引{"acknowledged"=>true, "shards_acknowledged"=>false}
创建es索引{"acknowledged"=>true, "shards_acknowledged"=>false} [2018-05-19T13: ...
- How to reduce Index size on disk?减少ES索引大小的一些小手段
ES索引文件瘦身总结如下: 原始数据:(1)学习splunk,原始data存big string(2)原始文件还可以再度压缩倒排索引:(1)去掉不必要的倒排索引信息:例如文件位置倒排._source和 ...
- 创建es索引-格式化和非格式化
创建es索引-格式化和非格式化 学习了:https://www.imooc.com/video/15768 索引有结构化和非结构化的区分: 1, 先创建索引,然后POST修改mapping 首先创建索 ...
- Elasticsearch之重要核心概念(cluster(集群)、shards(分配)、replicas(索引副本)、recovery(据恢复或叫数据重新分布)、gateway(es索引的持久化存储方式)、discovery.zen(es的自动发现节点机制机制)、Transport(内部节点或集群与客户端的交互方式)、settings(修改索引库默认配置)和mappings)
Elasticsearch之重要核心概念如下: 1.cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的.es的一个概念就是 ...
- Kibana自动关联ES索引
原因: Kibana中关联ES索引需要手动操作,如果ES中索引较多(如每天生成),则工作量会比较大. 方法: 考虑使用Linux的cron定时器自动关联ES索引,原理是调用Kibana API接口自动 ...
- Elasticsearch ES索引
ES是一个基于RESTful web接口并且构建在Apache Lucene之上的开源分布式搜索引擎. 同时ES还是一个分布式文档数据库,其中每个字段均可被索引,而且每个字段的数据均可被搜索,能够横向 ...
- es笔记---新建es索引
es对索引的一堆操作都是用restful api去进行的,参数时一堆json,一年前边查边写搞过一次,这回搞迁移,发现es都到6.0版本了,也变化了很多,写个小笔记记录一下. 创建一个es索引很简单, ...
随机推荐
- 爬虫——json模块与jsonpath模块
JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与后 ...
- hibernate中配置单向多对一关联,和双向一对多,双向多对多
什么是一对多,多对一? 一对多,比如你去找一个父亲的所有孩子,孩子可能有两个,三个甚至四个孩子. 这就是一对多 父亲是1 孩子是多 多对一,比如你到了两个孩子,它们都是有一个共同的父亲. 此时孩子就是 ...
- nginx 只允许域名访问,禁止IP访问
在nginx中为了防止,通过ip地址或者没有备案的域名代理到nginx上,可以在nginx中配置来阻止这一操作 #只可以用域名访问(此处的server是新增,并不是在原有的server基础上修改),默 ...
- 批处理,%~d0 cd %~dp0 代表什么意思
批处理,%~d0 cd %~dp0 代表什么意思 ~dp0 “d”为Drive的缩写,即为驱动器,磁盘.“p”为Path缩写,即为路径,目录cd是转到这个目录,不过我觉得cd /d %~dp0 还 ...
- JavaScript : CORS和Ajax请求
CORS(Cross-Origin Resource Sharing, 跨源资源共享)是W3C出的一个标准,其思想是使用自定义的HTTP头部让浏览器与服务器进行沟通,从而决定请求或响应是应该成功,还是 ...
- Java应用:经纬度匹配(geohash加密)
本文采用http://gc.ditu.aliyun.com地址进行经纬度匹配,无数量限制 如果给定经纬度进行geohash加密操作,先解密得到相应gps坐标,具体程序如下所示: import java ...
- Linux命令备忘录:quota显示磁盘已使用的空间与限制
quota命令用于显示用户或者工作组的磁盘配额信息.输出信息包括磁盘使用和配额限制. 语法 quota(选项)(参数) 选项 -g:列出群组的磁盘空间限制: -q:简明列表,只列出超过限制的部分: - ...
- 自定义vim配置文件vimrc,用于c/c++编程
vim作为Linux下广受赞誉的代码编辑器,其独特的纯命令行操作模式可以很大程度上方便编程工作,通过自定义vim配置文件可以实现对vim功能的个性化设置. vim配置文件一般有两份,属于root的/e ...
- R语言绘图:ggplot2绘制ROC
使用ggplot2包绘制ROC曲线 rocplot<- function(pred, truth, ...){ predob<- prediction(pred, truth) #打印AU ...
- Windows下使用PHP Xdebug
首先下载Xdebug的dll:http://xdebug.org/download.php 将dll文件放到php目录下的ext目录里面: 修改php.ini,根据自己的需要增加信息: [Xdebug ...