Java Set集合(HashSet、TreeSet)
什么是HashSet?操作过程是怎么样的?
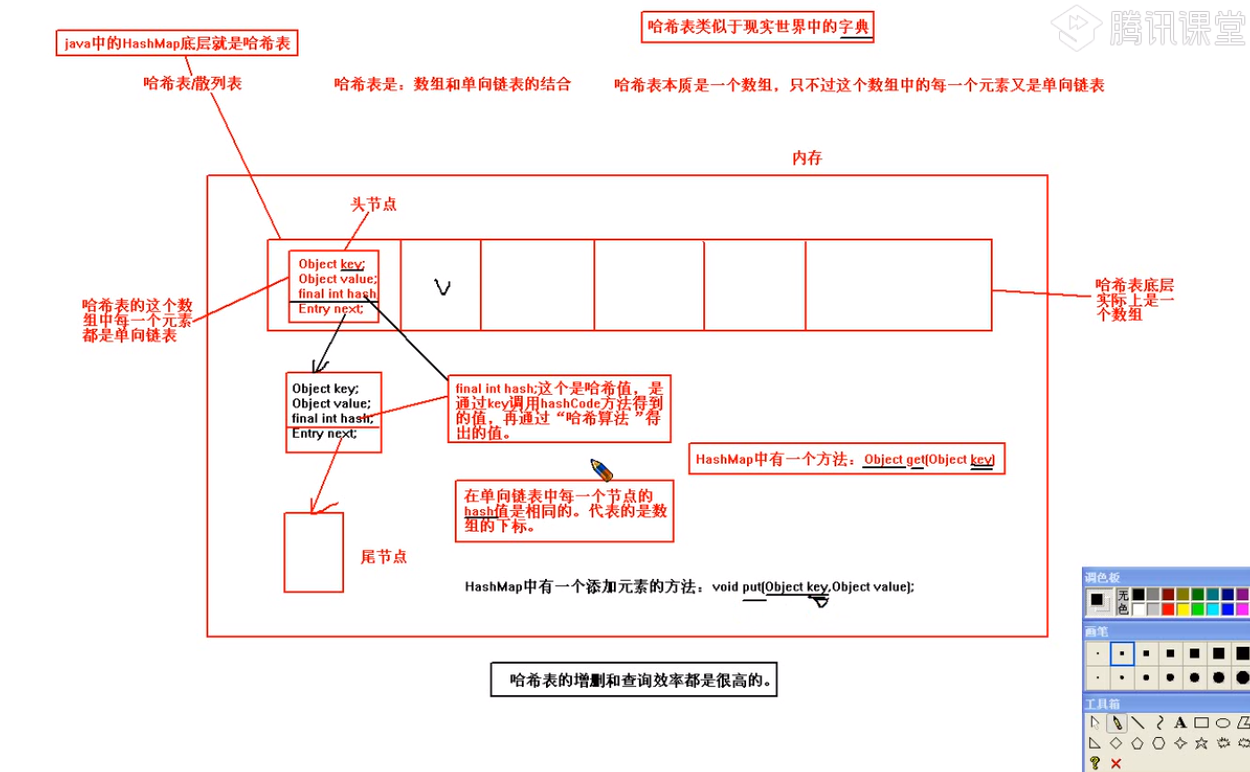
1、HashSet底层实际上是一个HashMap,HashMap底层采用了哈希表数据结构
2、哈希表又叫做散列表,哈希表底层是一个数组,这个数组中每一个元素是一个单向链表,每个单向链表都有一个独一无二的hash值,代表数组的下标。在某个单向链表中的每一个节点上的hash值是相同的。hash值实际上是key调用hashCode方法,再通过"hash function"转换成的值
3、如何向哈希表中添加元素?
先调用被存储的key的hashCode方法,经过某个算法得出hash值,如果在这个哈希表中不存在这个hash值,则直接加入元素。如果该hash值已经存在,继续 调用Key之间的equals方法,如果equals方法返回false,则将该元素添加。如果equals方法返回true,则放弃添加该元素
HashMap和HashSet初始化容量是16,默认加载因子是0.75
HashSet的数据结构
献上我看视频截的图
代码举例
public class Test{
public static void main(String[] args) {
Set set = new HashSet();
Student stu1 = new Student("1", "JACK");
Student stu2 = new Student("2", "TOM");
Student stu3 = new Student("3", "JIM");
set.add(stu1);
set.add(stu2);
set.add(stu3);
System.out.println("size :" + set.size());
}
}
class Student{
String no;
String name;
Student(String no, String name){
this.no = no;
this.name = name;
}
}
这个的输出结果显而易见是3,因为我们添加了三个元素,但是如果改一下
Student stu1 = new Student("1", "JACK");
Student stu2 = new Student("1", "JACK");
Student stu3 = new Student("3", "JIM");
System.out.println(stu1.hashCode());
System.out.println(stu2.hashCode());
可以运行试一下,stu1和stu2的hashCode是不一样的,为什么呢?因为这两个对象是New出来的,引用地址不一样。我们不希望出现这样的情况,那就要重写hashCode和equals方法
class Student{
String no;
String name;
Student(String no, String name){
this.no = no;
this.name = name;
}
public boolean equals(Object o){
if(this == o) return true;
if(o instanceof Student){
Student student = (Student) o;
if(student.no.equals(this.no) && student.name.equals(this.name)) return true;
}
return false;
}
public int hashCode(){
return no.hashCode();
}
}
再次运行,插入两个数据一样的对象,就不会重复了
TreeSet
treeset实现了sortedset接口,有个很重要的特点是里面的元素都是有序的
public class Test{
public static void main(String[] args) {
SortedSet set = new TreeSet();
set.add(1);
set.add(100);
set.add(50);
System.out.println(set);
}
}
输出结果:[1, 50, 100]
那如果我们自定义类可以进行比较吗?
public class Test{
public static void main(String[] args) {
SortedSet set = new TreeSet();
Student stu1 = new Student(22);
Student stu2 = new Student(11);
Student stu3 = new Student(100);
set.add(stu1);
set.add(stu2);
set.add(stu3);
System.out.println(set);
}
}
class Student{
int age;
Student(int age){
this.age = age;
}
}
这样运行会出现一个问题,报ClassCastException,这就需要来看看源码了,底层到底是怎么实现的,为什么自定义类就先不行呢?
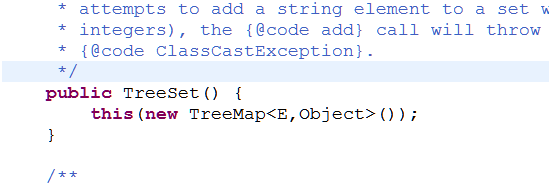
这里可以看到,当我们在创建一个TreeSet的时候,实际上是new了一个TreeMap

add的时候调用了TreeMap的put方法,来看看TreeMap中的put方法

可以看到第三个红框那里,会对key进行一个强制类型转换,我们上面的代码肯定是就是在这里装换不成功,Comparable是什么?来看看API

是一个接口,从翻译就可以看出,只要实现了这个接口,就是可以比较的,下面是实现了这个接口的类

随便框了几个,上面就有Integer,这个类实现了comparable接口,因此第一个代码是正确的,现在我们是不是只要实现这个接口就好了呢!
class Student implements Comparable{
int age;
Student(int age){
this.age = age;
}
//重写接口中的方法
//要重写比较规则
@Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
int age1 = this.age;
int age2 = ((Student)o).age;
return age2 - age1;
}
}
这样OK了,再来看看上面有红框的源码,cmp<0,cmp>0,left,right都是什么东西,二叉树!所以底层是通过二叉树来排序的
如果是自定义类中的String呢,那就return String的compareTo方法就好了
Java Set集合(HashSet、TreeSet)的更多相关文章
- Set集合[HashSet,TreeSet,LinkedHashSet],Map集合[HashMap,HashTable,TreeMap]
------------ Set ------------------- 有序: 根据添加元素顺序判定, 如果输出的结果和添加元素顺序是一样 无序: 根据添加元素顺序判定,如果输出的结果和添加元素的顺 ...
- Java容器---Set: HashSet & TreeSet & LinkedHashSet
1.Set接口概述 Set 不保存重复的元素(如何判断元素相同呢?).如果你试图将相同对象的多个实例添加到Set中,那么它就会阻止这种重复现象. Set中最常被使用的是测试归属性,你可以 ...
- Java基础---集合框架---迭代器、ListIterator、Vector中枚举、LinkedList、ArrayList、HashSet、TreeSet、二叉树、Comparator
为什么出现集合类? 面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式. 数组和集合类同是容器,有何不同? 数组虽然也可以存储对 ...
- Java集合之TreeSet
TreeSet是一个有序的集合,它的作用是提供有序的Set集合.它继承了AbstractSet抽象类,实现了NavigableSet<E>,Cloneable,Serializable接口 ...
- Java集合 HashSet的原理及常用方法
目录 一. HashSet概述 二. HashSet构造 三. add方法 四. remove方法 五. 遍历 六. 合计合计 先看一下LinkedHashSet 在看一下TreeSet 七. 总结 ...
- java数据结构之HashSet和TreeSet以及LinkedHashSet
一.HashSet源码注释 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cl ...
- 集合框架的详解,List(ArrayList,LinkedList,Vector),Set(HashSet,TreeSet)-(14)
集合详解: /* Collection |--List:元素是有序的,元素可以重复.因为该集合体系有索引. |--ArrayList:底层的数据结构使用的是数组结构.特点:查询速度很快.但是增删稍慢. ...
- Set集合——HashSet、TreeSet、LinkedHashSet(2015年07月06日)
一.Set集合不同于List的是: Set不允许重复 Set是无序集合 Set没有下标索引,所以对Set的遍历要通过迭代器Iterator 二.HashSet 1.HashSet由一个哈希表支持,内部 ...
- Java基础知识强化之集合框架笔记47:Set集合之TreeSet保证元素唯一性和比较器排序的原理及代码实现(比较器排序:Comparator)
1. 比较器排序(定制排序) 前面我们说到的TreeSet的自然排序是根据集合元素的大小,TreeSet将它们以升序排列. 但是如果需要实现定制排序,比如实现降序排序,则要通过比较器排序(定制排序)实 ...
随机推荐
- div可编辑框,去除粘贴文字样式😄
上个月做了个聊天的需求(网页版的).说到聊天都想到输入框,说到输入框都会想到input,但是input标签是不支持插入图片的(包括areatext标签).查阅了一些资料就看到div标签有一个属性con ...
- 【洛谷P3959】[NOIP2017] 宝藏
宝藏 题目链接 首先,打了一个prim,得了45分 #include<iostream> #include<cstring> #include<cstdio> #i ...
- google为什么将爬虫从python移植到C++
这是好几年前Quora上的一个问题,有点过时,但看了之后感觉不错,就总结了一下 原文链接:http://www.quora.com/Why-did-Google-move-from-Python-to ...
- wordpress二次开发第一个jquery对比
$(document).ready(function(){ $("input").focus(function(){ $("input").css(" ...
- ng-repeat 指令(带有对象)
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- iOS | 实现拖拽CollectionViewCell排序
现在很多项目都会用到类似拖动的效果,比如今日头条和网易新闻之类的资讯类产品,都有用该技术设置模块顺序的操作. 在iOS9.0之后,苹果提供相关的方法,非常方便. 设定三个私有属性 @property( ...
- Python实现trim函数
Python中其实也有类似Java的trim函数的,叫做strip,举例: #!/usr/bin/python # -*- coding: UTF-8 -*- str = "0000000h ...
- Mac系统配置php环境
[写在前面——叨叨叨] -_-#急着配环境的同志们可以绕道.最近学校的实验室里接了一个小项目——考勤刷卡系统,利用RFID在硬件层获取学生卡的ID,通过wifi传输至服务器,进行考勤信息存储,手机端获 ...
- 设置Vim编辑器里Tab的长度,行号
使用Vim编辑器写脚本时,经常会遇到多重循环语句,习惯上会用tab键来补齐.这时设置tab键占用的长度,可以调节界面的松紧度,使其达到令人满意的效果. 在针对个别用户和所有用户来设置时,与编辑SSH相 ...
- C#中给WebClient添加代理Proxy
效果图: using System; using System.Collections.Generic; using System.ComponentModel; using System.Data; ...