tensorflow-如何防止过拟合
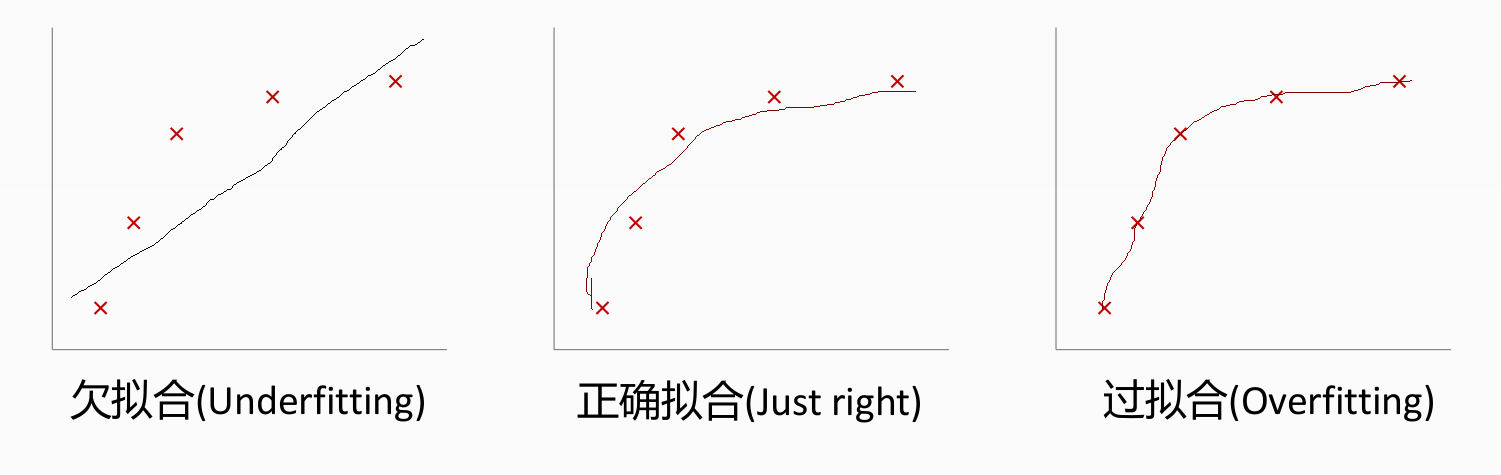
回归:过拟合情况
/
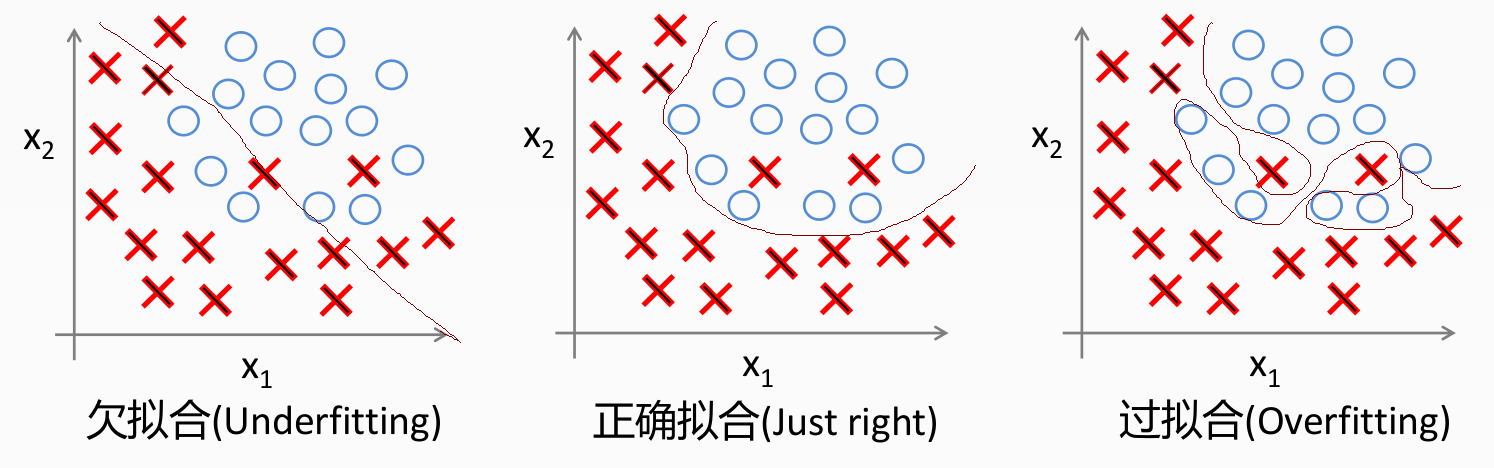
分类过拟合
防止过拟合的方法有三种:
1 增加数据集
2 添加正则项
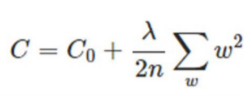
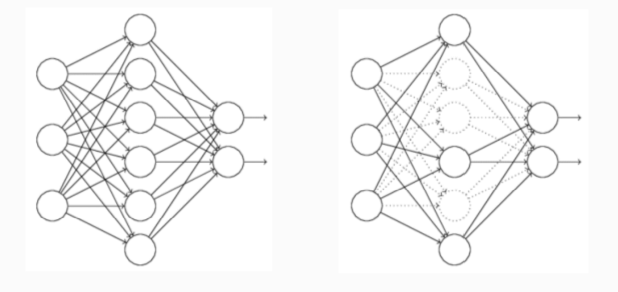
3 Dropout,意思就是训练的时候隐层神经元每次随机抽取部分参与训练。部分不参与
最后对之前普通神经网络分类mnist数据集的代码进行优化,初始化权重参数的时候采用截断正态分布,偏置项加常数,采用dropout防止过拟合,加4层隐层神经元,最后的准确率达到97%以上。代码如下

# coding: utf-8 # 微信公众号:深度学习与神经网络
# Github:https://github.com/Qinbf
# 优酷频道:http://i.youku.com/sdxxqbf import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data #载入数据集
mnist = input_data.read_data_sets("MNIST_data",one_hot=True) #每个批次的大小
batch_size = 100
#计算一共有多少个批次
n_batch = mnist.train.num_examples // batch_size #定义两个placeholder
x = tf.placeholder(tf.float32,[None,784])
y = tf.placeholder(tf.float32,[None,10])
keep_prob=tf.placeholder(tf.float32) #创建一个简单的神经网络
W1 = tf.Variable(tf.truncated_normal([784,2000],stddev=0.1))
b1 = tf.Variable(tf.zeros([2000])+0.1)
L1 = tf.nn.tanh(tf.matmul(x,W1)+b1)
L1_drop = tf.nn.dropout(L1,keep_prob) W2 = tf.Variable(tf.truncated_normal([2000,2000],stddev=0.1))
b2 = tf.Variable(tf.zeros([2000])+0.1)
L2 = tf.nn.tanh(tf.matmul(L1_drop,W2)+b2)
L2_drop = tf.nn.dropout(L2,keep_prob) W3 = tf.Variable(tf.truncated_normal([2000,1000],stddev=0.1))
b3 = tf.Variable(tf.zeros([1000])+0.1)
L3 = tf.nn.tanh(tf.matmul(L2_drop,W3)+b3)
L3_drop = tf.nn.dropout(L3,keep_prob) W4 = tf.Variable(tf.truncated_normal([1000,10],stddev=0.1))
b4 = tf.Variable(tf.zeros([10])+0.1)
prediction = tf.nn.softmax(tf.matmul(L3_drop,W4)+b4) #二次代价函数
# loss = tf.reduce_mean(tf.square(y-prediction))
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=prediction))
#使用梯度下降法
train_step = tf.train.GradientDescentOptimizer(0.2).minimize(loss) #初始化变量
init = tf.global_variables_initializer() #结果存放在一个布尔型列表中
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))#argmax返回一维张量中最大的值所在的位置
#求准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32)) with tf.Session() as sess:
sess.run(init)
for epoch in range(31):
for batch in range(n_batch):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys,keep_prob:0.7}) test_acc = sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels,keep_prob:1.0})
train_acc = sess.run(accuracy,feed_dict={x:mnist.train.images,y:mnist.train.labels,keep_prob:1.0})
print("Iter " + str(epoch) + ",Testing Accuracy " + str(test_acc) +",Training Accuracy " + str(train_acc))
结果如下
Iter 0,Testing Accuracy 0.913,Training Accuracy 0.909146
Iter 1,Testing Accuracy 0.9318,Training Accuracy 0.927218
Iter 2,Testing Accuracy 0.9397,Training Accuracy 0.9362
Iter 3,Testing Accuracy 0.943,Training Accuracy 0.940637
Iter 4,Testing Accuracy 0.9449,Training Accuracy 0.945746
Iter 5,Testing Accuracy 0.9489,Training Accuracy 0.949491
Iter 6,Testing Accuracy 0.9505,Training Accuracy 0.9522
Iter 7,Testing Accuracy 0.9542,Training Accuracy 0.956
Iter 8,Testing Accuracy 0.9543,Training Accuracy 0.957782
Iter 9,Testing Accuracy 0.954,Training Accuracy 0.959
Iter 10,Testing Accuracy 0.9558,Training Accuracy 0.959582
Iter 11,Testing Accuracy 0.9594,Training Accuracy 0.963146
Iter 12,Testing Accuracy 0.959,Training Accuracy 0.963746
Iter 13,Testing Accuracy 0.961,Training Accuracy 0.964764
Iter 14,Testing Accuracy 0.9605,Training Accuracy 0.9658
Iter 15,Testing Accuracy 0.9635,Training Accuracy 0.967528
Iter 16,Testing Accuracy 0.9639,Training Accuracy 0.968582
Iter 17,Testing Accuracy 0.9644,Training Accuracy 0.969309
Iter 18,Testing Accuracy 0.9651,Training Accuracy 0.969564
Iter 19,Testing Accuracy 0.9664,Training Accuracy 0.971073
Iter 20,Testing Accuracy 0.9654,Training Accuracy 0.971746
Iter 21,Testing Accuracy 0.9664,Training Accuracy 0.971764
Iter 22,Testing Accuracy 0.9682,Training Accuracy 0.973128
Iter 23,Testing Accuracy 0.9679,Training Accuracy 0.973346
Iter 24,Testing Accuracy 0.9681,Training Accuracy 0.975164
Iter 25,Testing Accuracy 0.969,Training Accuracy 0.9754
Iter 26,Testing Accuracy 0.9706,Training Accuracy 0.975764
Iter 27,Testing Accuracy 0.9694,Training Accuracy 0.975837
Iter 28,Testing Accuracy 0.9703,Training Accuracy 0.977109
Iter 29,Testing Accuracy 0.97,Training Accuracy 0.976946
Iter 30,Testing Accuracy 0.9715,Training Accuracy 0.977491
Testing Accuracy和Training Accuracy之间的差距为0.005991
dropout值设置为1的时候,
Iter 0,Testing Accuracy 0.9471,Training Accuracy 0.955037
Iter 1,Testing Accuracy 0.9597,Training Accuracy 0.9738
Iter 2,Testing Accuracy 0.9616,Training Accuracy 0.980928
Iter 3,Testing Accuracy 0.9661,Training Accuracy 0.985091
Iter 4,Testing Accuracy 0.9674,Training Accuracy 0.987709
Iter 5,Testing Accuracy 0.9692,Training Accuracy 0.989255
Iter 6,Testing Accuracy 0.9692,Training Accuracy 0.990146
Iter 7,Testing Accuracy 0.9708,Training Accuracy 0.991182
Iter 8,Testing Accuracy 0.9711,Training Accuracy 0.991982
Iter 9,Testing Accuracy 0.9712,Training Accuracy 0.9924
Iter 10,Testing Accuracy 0.971,Training Accuracy 0.992691
Iter 11,Testing Accuracy 0.9706,Training Accuracy 0.993055
Iter 12,Testing Accuracy 0.971,Training Accuracy 0.993309
Iter 13,Testing Accuracy 0.9717,Training Accuracy 0.993528
Iter 14,Testing Accuracy 0.9719,Training Accuracy 0.993764
Iter 15,Testing Accuracy 0.9715,Training Accuracy 0.993927
Iter 16,Testing Accuracy 0.9715,Training Accuracy 0.994091
Iter 17,Testing Accuracy 0.9714,Training Accuracy 0.994291
Iter 18,Testing Accuracy 0.9719,Training Accuracy 0.9944
Iter 19,Testing Accuracy 0.9719,Training Accuracy 0.994564
Iter 20,Testing Accuracy 0.9722,Training Accuracy 0.994673
Iter 21,Testing Accuracy 0.9725,Training Accuracy 0.994855
Iter 22,Testing Accuracy 0.9731,Training Accuracy 0.994891
Iter 23,Testing Accuracy 0.9721,Training Accuracy 0.994928
Iter 24,Testing Accuracy 0.9722,Training Accuracy 0.995018
Iter 25,Testing Accuracy 0.9725,Training Accuracy 0.995109
Iter 26,Testing Accuracy 0.9729,Training Accuracy 0.9952
Iter 27,Testing Accuracy 0.9726,Training Accuracy 0.995255
Iter 28,Testing Accuracy 0.9725,Training Accuracy 0.995327
Iter 29,Testing Accuracy 0.9725,Training Accuracy 0.995364
Iter 30,Testing Accuracy 0.9722,Training Accuracy 0.995437
Testing Accuracy和Training Accuracy之间的差距为0.23237,本次实验中只有60000个样本,当样本量到达几百万的时候,这个差距值会更大,也就是训练出的模型在训练数据集中效果非常好,几乎满足了任意一个样本,但是在测试数据集中效果却很差,此时就是典型的过拟合现象。
所以一般稍微复杂的网络中都会加入dropout,防止过拟合。
tensorflow-如何防止过拟合的更多相关文章
- Tensorflow学习教程------过拟合
Tensorflow学习教程------过拟合 回归:过拟合情况 / 分类过拟合 防止过拟合的方法有三种: 1 增加数据集 2 添加正则项 3 Dropout,意思就是训练的时候隐层神经元每次随机 ...
- tensorflow学习2-线性拟合和神经网路拟合
线性拟合的思路: 线性拟合代码: import tensorflow as tf import numpy as np import matplotlib.pyplot as plt #%%图形绘制 ...
- 深度学习原理与框架-Tensorflow基本操作-实现线性拟合
代码:使用tensorflow进行数据点的线性拟合操作 第一步:使用np.random.normal生成正态分布的数据 第二步:将数据分为X_data 和 y_data 第三步:对参数W和b, 使用t ...
- 芝麻HTTP:TensorFlow基础入门
本篇内容基于 Python3 TensorFlow 1.4 版本. 本节内容 本节通过最简单的示例 -- 平面拟合来说明 TensorFlow 的基本用法. 构造数据 TensorFlow 的引入方式 ...
- TensorFlow拟合线性函数
TensorFlow拟合线性函数 简单的TensorFlow图构造 以单个神经元为例 x_data数据为20个随机 [0, 1) 的32位浮点数按照 shape=[20] 组成的张量 y_data为 ...
- TensorFlow从1到2(八)过拟合和欠拟合的优化
<从锅炉工到AI专家(6)>一文中,我们把神经网络模型降维,简单的在二维空间中介绍了过拟合和欠拟合的现象和解决方法.但是因为条件所限,在该文中我们只介绍了理论,并没有实际观察现象和应对. ...
- AI - TensorFlow - 过拟合(Overfitting)
过拟合 过拟合(overfitting,过度学习,过度拟合): 过度准确地拟合了历史数据(精确的区分了所有的训练数据),而对新数据适应性较差,预测时会有很大误差. 过拟合是机器学习中常见的问题,解决方 ...
- tensorflow学习之(八)使用dropout解决overfitting(过拟合)问题
#使用dropout解决overfitting(过拟合)问题 #如果有dropout,在feed_dict的参数中一定要加入dropout的值 import tensorflow as tf from ...
- 06 使用Tensorflow拟合x与y之间的关系
看代码: import tensorflow as tf import numpy as np #构造输入数据(我们用神经网络拟合x_data和y_data之间的关系) x_data = np.lin ...
- 蛙蛙推荐: TensorFlow Hello World 之平面拟合
tensorflow 已经发布了 2.0 alpha 版本,所以是时候学一波 tf 了.官方教程有个平面拟合的类似Hello World的例子,但没什么解释,新手理解起来比较困难. 所以本文对这个案例 ...
随机推荐
- Docker学习笔记_创建和使用Centos容器
实验:创建和使用Centos容器 步骤: 1.搜索 sudo docker search cen ...
- 28. LAST() 函数
LAST() 函数 LAST() 函数返回指定的字段中最后一个记录的值. 提示:可使用 ORDER BY 语句对记录进行排序. SQL LAST() 语法 SELECT LAST(column_nam ...
- 487C Prefix Product Sequence
传送门 题目大意 分析 因为n为质数所以i-1的逆元唯一 因此ai唯一 代码 #include<iostream> #include<cstdio> #include<c ...
- Ubuntu 12.04 LTS 中文输入法的安装 (转载)
第一步:安装语言包 进入 “System Settings” 找到 “Language Support” 那一项,点击进入 选择 “Install/Remove Languages” 找到 “Chin ...
- Laravel Gate 授权方式的使用指南
参考链接:An Introduction to Laravel Authorization Gates 本文使用 Laravel 的 Gate 授权方式 实现一个基于用户角色的博客发布系统. 在系统包 ...
- Python基础入门-函数实战登录功能
''' 函数实战: .加法计算器 .过滤器 .登录功能实战 ''' def add(a,b): return a+b def login_order(): return 'asdfasdfdasfad ...
- HDU 3362 Fix (状压DP)
题意:题目给出n(n <= 18)个点的二维坐标,并说明某些点是被固定了的,其余则没固定,要求添加一些边,使得还没被固定的点变成固定的, 要求总长度最短. 析:由于这个 n 最大才是18,比较小 ...
- HTTP文件上传插件开发文档-JSP
版权所有 2009-2016 荆门泽优软件有限公司 保留所有权利 官方网站:http://www.ncmem.com/ 产品首页:http://www.ncmem.com/webplug/http-u ...
- 状态压缩DP----HDU2809
状态压缩DP的一道较不错的入门题,第二次做这类问题,感觉不是很顺手,故记录下来. 题目的意思就是吕布战群雄,先给你6个数,分别是吕布的攻击值,防御值,生命值,升级后此三值各自的增量,然后是对手的个数n ...
- POJ - 2965 The Pilots Brothers' refrigerator(压位+bfs)
The game “The Pilots Brothers: following the stripy elephant” has a quest where a player needs to op ...