【机器学习】--LDA初始和应用
一、前述
LDA是一种 非监督机器学习 技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于 Dirichlet分布随机向量各分量间的弱相关性(之所以还有点“相关”,是因为各分量之和必须为1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了LDA的又一个遗留问题。
二、具体过程
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
三、案例
假设文章1开始有以下单词:
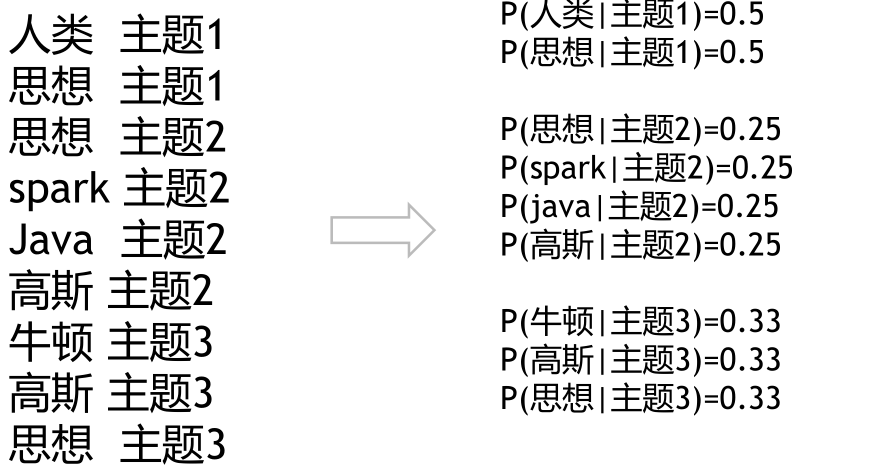
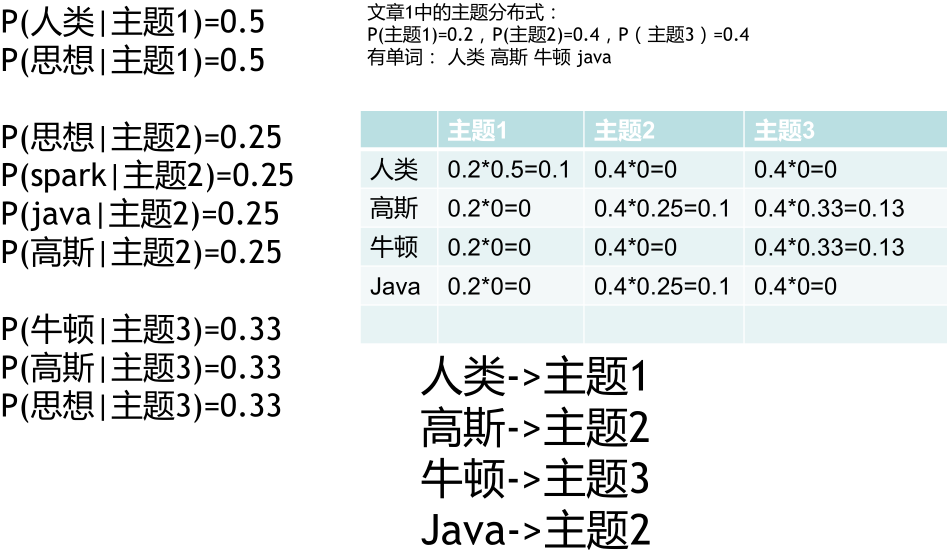
高斯分为主题二,是因为有一定的概率。

如此反复,当各个概率分布不再发生变化时,即完成了收敛和训练过程
训练思想仍然是EM算法(摁住一个,去计算另一个)
对比K-means
实际工程过程中:
每一个主题对每一个词都有一个基本出现次数(人工设定)
每一篇文章在各个主题上都有一个基本出现词数
步骤:
新来一片文章,需要确定它的主题分布:
先随机化主题分布
1.根据主题分布和主题-单词模型,找寻每个
单词所对应的主题
2.根据单词主题重新确定主题分布
1,2反复,直到主题分布稳定 最终得到两个模型:
1.每篇文章的主题分布
2.每个主题产生词的概率
用途:
1.根据文章的主题分布,计算文章之间的相似性
2.计算各个词语之间的相似度
四、代码
# -*- coding: utf-8 -*- import jieba
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation for i in range(4):
with open('./data/nlp_test%d.txt' % i, encoding='UTF-8') as f:
document = f.read() document_cut = jieba.cut(document)
result = ' '.join(document_cut)
print(result)
with open('./data/nlp_test%d.txt' % (i+10), 'w', encoding='UTF-8') as f2:
f2.write(result)
f.close()
f2.close() # 从文件导入停用词表
stpwrdpath = "./data/stop_words.txt"
stpwrd_dic = open(stpwrdpath, 'r', encoding='UTF-8')
stpwrd_content = stpwrd_dic.read()
# 将停用词表转换为list
stpwrdlst = stpwrd_content.splitlines()
stpwrd_dic.close()
print(stpwrdlst) # 向量化 不需要tf_idf
corpus = []
for i in range(4):
with open('./data/nlp_test%d.txt' % (i+10), 'r', encoding='UTF-8') as f:
res = f.read()
corpus.append(res)
print(res) cntVector = CountVectorizer(stop_words=stpwrdlst)
cntTf = cntVector.fit_transform(corpus)
print(cntTf) # 打印输出对应关系
# 获取词袋模型中的所有词
wordlist = cntVector.get_feature_names()
# 元素a[i][j]表示j词在i类文本中的权重
weightlist = cntTf.toarray()
# 打印每类文本的词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for i in range(len(weightlist)):
print("-------第", i, "段文本的词语权重------")
for j in range(len(wordlist)):
print(wordlist[j], weightlist[i][j]) lda = LatentDirichletAllocation(n_components=3,#3个话题
learning_method='batch',
random_state=0)
docres = lda.fit_transform(cntTf) print("文章的主题分布如下:")
print(docres)
print("主题的词分布如下:")
print(lda.components_)
【机器学习】--LDA初始和应用的更多相关文章
- 机器学习-LDA主题模型笔记
LDA常见的应用方向: 信息提取和搜索(语义分析):文档分类/聚类.文章摘要.社区挖掘:基于内容的图像聚类.目标识别(以及其他计算机视觉应用):生物信息数据的应用; 对于朴素贝叶斯模型来说,可以胜任许 ...
- Spark MLlib LDA 基于GraphX实现原理及源代码分析
LDA背景 LDA(隐含狄利克雷分布)是一个主题聚类模型,是当前主题聚类领域最火.最有力的模型之中的一个,它能通过多轮迭代把特征向量集合按主题分类.眼下,广泛运用在文本主题聚类中. LDA的开源实现有 ...
- 如何用Python从海量文本抽取主题?
摘自https://www.jianshu.com/p/fdde9fc03f94 你在工作.学习中是否曾因信息过载叫苦不迭?有一种方法能够替你读海量文章,并将不同的主题和对应的关键词抽取出来,让你谈笑 ...
- Spark机器学习(8):LDA主题模型算法
1. LDA基础知识 LDA(Latent Dirichlet Allocation)是一种主题模型.LDA一个三层贝叶斯概率模型,包含词.主题和文档三层结构. LDA是一个生成模型,可以用来生成一篇 ...
- 【机器学习】主题模型(二):pLSA和LDA
-----pLSA概率潜在语义分析.LDA潜在狄瑞雷克模型 一.pLSA(概率潜在语义分析) pLSA: -------有过拟合问题,就是求D, Z, W pLSA由LSA发展过来,而早期L ...
- 四大机器学习降维算法:PCA、LDA、LLE、Laplacian Eigenmaps
四大机器学习降维算法:PCA.LDA.LLE.Laplacian Eigenmaps 机器学习领域中所谓的降维就是指采用某种映射方法,将原高维空间中的数据点映射到低维度的空间中.降维的本质是学习一个映 ...
- 机器学习中的数学-线性判别分析(LDA), 主成分分析(PCA)
转:http://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html 版权声明: 本文由L ...
- 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 机器学习 —— 基础整理(四)特征提取之线性方法:主成分分析PCA、独立成分分析ICA、线性判别分析LDA
本文简单整理了以下内容: (一)维数灾难 (二)特征提取--线性方法 1. 主成分分析PCA 2. 独立成分分析ICA 3. 线性判别分析LDA (一)维数灾难(Curse of dimensiona ...
随机推荐
- junit+mock+spring-test构建后台单元测试
from:从0开始,构建前后端分离应用 1. 一些基本概念 1.1 为什么要进行单元测试?我自己的理解是 1.能够快速发现问题.避免衍生BUG的出现 在对一些现有代码进行修改时,或者修改现有B ...
- QM1_Time value of Money
总体框架 Time Value Interest Rate rf: 无风险收益率 (CFA中一般认为是美国短期国债T-bill的收益率) Nominal risk-free rate: 名义无风险税 ...
- 电脑开机出现“致命错误C0000034。。。”--该怎么办?
win7或win8系统的电脑在开机时出现了 "致命错误C0000034 正在更新操作236,共156764个0000000000000000.cdf-ms "的提示并不能正常启动系 ...
- main.go
package main import ( "flag" "fmt" "log" "os" ...
- 【BZOJ 4016】 [FJOI2014]最短路径树问题
题目链接: TP 题解: 我就是个智障.明明是道大水题,硬是拖了6h. 关于这道题我唯一想说的就是,记得更新拆分后的子树大小!!!我就是ZZ恒(QwQ. 代码: #define Troy 10/26 ...
- BZOJ_4756_[Usaco2017 Jan]Promotion Counting_树状数组
BZOJ_4756_[Usaco2017 Jan]Promotion Counting_树状数组 Description n只奶牛构成了一个树形的公司,每个奶牛有一个能力值pi,1号奶牛为树根. 问对 ...
- 全文检索选择-------- Elasticsearch与Solr
Elasticsearch简介* Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据. 它可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三 ...
- java爬虫,爬取当当网数据
背景:女票快毕业了(没错!我是有女票的!!!),写论文,主题是儿童性教育,查看儿童性教育绘本数据死活找不到,没办法,就去当当网查询下数据,但是数据怎么弄下来呢,首先想到用Python,但是不会!!百 ...
- linux服务器 jboss-7安装
jBoss简介 JBoss是一个运行EJB的J2EE应用服务器.它是开放源代码的项目,遵循最新的J2EE规范.从JBoss项目开始至今,它已经从一个EJB容器发展成为一个基于的J2EE的一个web 操 ...
- ASP.NET Core的实时库: SignalR -- 预备知识
大纲 本系列会分为2-3篇文章. 第一篇介绍SignalR的预备知识和原理 然后会介绍SignalR和如何在ASP.NET Core里使用SignalR. 本文的目录如下: 实时Web简述 Long ...