R语言-选择样本数量
功效分析:可以帮助在给定置信度的情况下,判断检测到给定效应值时所需的样本量,也可以在给定置信水平的情况下,计算某样本量内可以检测到的给定效应值的概率
1.t检验
案例:使用手机和司机反应时间的实验
library(pwr)
# n表示样本大小
# d表示标准化均值之差
# sig.level表示显著性水平
# power为功效水平
# type指的是检验类型
# alternative指的是双侧检验还是单侧检验
pwr.t.test(d=.8,sig.level = .05,power = .9,type = 'two.sample',alternative = 'two.sided')

结论:每组需要34个样本(68)人才能保证有90%的把握检测到0.8效应值,并且最多5%会存在误差
2.方差分析
案例:对5组数据做方差分析,达到0.8的功效,效应值为0.25,选择0.5的显著水平.计算总体样本的大小
# k表示组的个数
# f表示效应值
pwr.anova.test(k=5,f=.25,sig.level = .05,power = .8)

结论:需要39*5,195受试者参与实验才能得出以上结果
3.相关性
案例:抑郁症和孤独的关系,零假设和研究假设为
H0:p<=0.25和H1:p>0.25
设定显著水平为0.05,耳光拒绝零假设,希望有90%的信息拒绝H0,需要多少测试者
# r表示效应值
pwr.r.test(r=.25,sig.level = .05,power = .90,alternative = 'greater')

结论:需要134名受试者参与实验
4.线性模型
案例:老板的领导风格对员工满意度的影响,薪水和小费能解释30%员工满意度方差,领导风格能解释35%的方差,
要达到90%置信度下,显著水平为0.05,需要多少受试者才能达到方差贡献率
f2 = (0.35-0.3)/(1-0.35)=0.0769
# u表示分子自由度
# v表示分母自由度
# f2表示效应值
pwr.f2.test(u=3,f2=0.0769,sig.level = .05,power = .90)

结论:v=总体样本-预测变量-1,所以N=v+7+1=187+7+1=193
5.比例检验
案例:某种药物有60%的治愈率,新药有65%的治愈率,现在有多少受试者才能体会到两种药物的差异
pwr.2p.test(h=ES.h(.65,.6),sig.level = .05,power = .9,alternative = 'greater')

结论:本案例中使用单边检验,得出需要1605名受试者才能得出两种药品的区别
6.卡方检验
卡方检验用来评价两个变量之间的关系,零假设是变量之间独立,拒绝零假设是变量不独立
案例:研究晋升和种族的关系:样本中70%是白人,10%黑人,20%西班牙裔,相比20%的黑人和50%的西班牙裔,60%的白人更容易获得晋升
prob <- matrix(c(.42,.28,.03,.07,.10,.10),byrow = T,nrow = 3)
# 计算双因素列连表中的备择假设的效应值
ES.w2(prob)
# w是效应值,
# df是自由度
pwr.chisq.test(w=0.1853198,df=2,sig.level = .05,power = .90)

结论:该实验需要369名测试者才能证明晋升和种族存在关联
7.在新的情况下选择合适的效应值
7.1单因素
es <- seq(.1,.5,.01)
nes <- length(es)
samsize <- NULL
for(i in 1:nes){
result <- pwr.anova.test(k=5,f=es[i],sig.level = .05,power = .90)
samsize[i] <- ceiling(result$n)
}
plot(samsize,es,type='l',lwd='',col='red',
ylab = 'Effect Size',
xlab = 'Sample Szie',
main = 'One way Anova with power=.90 and alpha=.05')
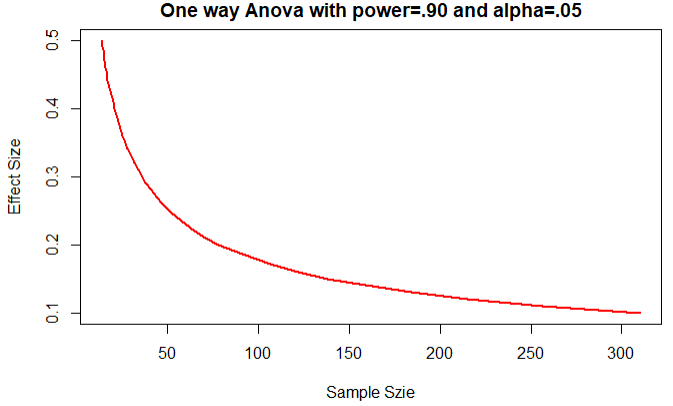
结论:赝本数量高于200时,在增加样本是效果不明显
7.2 绘制功效分析图
# 1.生成一系列相关系数和功效值
r <- seq(.1,.5,.01)
nr <- length(r) p <- seq(.4,.9,.1)
np <- length(p) # 2.获取样本大小
samsize <- array(numeric(nr*np),dim = c(nr,np)) for(i in 1:np){
for(j in 1:nr){
result <- pwr.r.test(n=NULL,r=r[j],sig.level = .05,power = p[i],alternative = 'two.sided')
samsize[j,i] <- ceiling(result$n)
}
} # 3.创建图形
xrange <- range(r)
yrange <- round(range(samsize))
colors <- rainbow(length(p))
plot(xrange,yrange,type='n',
xlab = 'Corrlation Coefficient',
ylab = 'Sample Size')
# 4.添加功效曲线
for(i in 1:np){
lines(r,samsize[,i],type='l',lwd=2,col=colors[i])
}
# 5.网格线
abline(v=0,h=seq(0,yrange[2],50),lty=2,col='grey89')
abline(h=0,v=seq(xrange[1],xrange[2],.02),lty=2,col='grey89')
# 6.标题和注释
title('Sample Size Estimation for Corrlation\nSig=0.05')
legend('topright',title = 'Power',as.character(p),fill=colors)
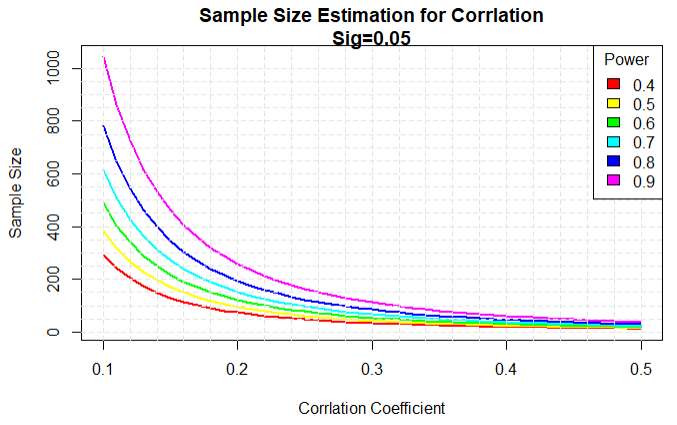
结论:在40%的置信度下,要检测到0.2的相关性需要约75个样本,在90%的置信度下,要检测到相同的相关性需要大约260个样本
R语言-选择样本数量的更多相关文章
- R语言中样本平衡的几种方法
R语言中样本平衡的几种方法 在对不平衡的分类数据集进行建模时,机器学习算法可能并不稳定,其预测结果甚至可能是有偏的,而预测精度此时也变得带有误导性.在不平衡的数据中,任一算法都没法从样本量少的类中获取 ...
- R语言︱文件读入、读出一些方法罗列(批量xlsx文件、数据库、文本txt、文件夹)
笔者寄语:小规模的读取数据的方法较为简单并且多样,但是,批量读取目前看到有以下几种方法:xlsx包.RODBC包.批量转化成csv后读入. R语言中还有一些其他较为普遍的读入,比如代码包,R文件,工作 ...
- R语言统计分析技术研究 特征值选择技术要点
特征值选择技术要点 作者:王立敏 文章来源: 网络 1.特征值 特征值是线性代数中的一个重要概念.在数学,物理学,化学,计算机等领域有着广泛的应用. ...
- R语言实战实现基于用户的简单的推荐系统(数量较少)
R语言实战实现基于用户的简单的推荐系统(数量较少) a<-c(1,1,1,1,2,2,2,2,3,3,3,4,4,4,5,5,5,5,6,6,7,7) b<-c(1,2,3,4,2,3,4 ...
- [转]概率基础和R语言
概率基础和R语言 R的极客理想系列文章,涵盖了R的思想,使用,工具,创新等的一系列要点,以我个人的学习和体验去诠释R的强大. R语言作为统计学一门语言,一直在小众领域闪耀着光芒.直到大数据的爆发,R语 ...
- 机器学习与R语言
此书网上有英文电子版:Machine Learning with R - Second Edition [eBook].pdf(附带源码) 评价本书:入门级的好书,介绍了多种机器学习方法,全部用R相关 ...
- 第五篇:R语言数据可视化之散点图
散点图简介 散点图通常是用来表述两个连续变量之间的关系,图中的每个点表示目标数据集中的每个样本. 同时散点图中常常还会拟合一些直线,以用来表示某些模型. 绘制基本散点图 本例选用如下测试数据集: 绘制 ...
- 数据分析与R语言
数据结构 创建向量和矩阵 函数c(), length(), mode(), rbind(), cbind() 求平均值,和,连乘,最值,方差,标准差 函数mean(), sum(), min(), m ...
- 【R】正态检验与R语言
正态检验与R语言 1.Kolmogorov–Smirnov test 统计学里, Kolmogorov–Smirnov 检验(亦称:K–S 检验)是用来检验数据是否符合某种分布的一种非参数检验,通过比 ...
随机推荐
- SSM框架原理,作用及使用方法
---恢复内容开始--- 尊重原创:http://m.blog.csdn.net/dennis_wu_/article/details/73437097 作用: SSM框架是spring MVC ,s ...
- sha1() 函数
sha1() 函数计算字符串的 SHA-1 散列. sha1() 函数使用美国 Secure Hash 算法 1. 来自 RFC 3174 的解释 - 美国 Secure Hash 算法 1:SHA- ...
- 如何在vue里面访问php?
如果你选择前端使用vue框架,后端用PHP开发,服务器就不用node了,用Apache就好了 开发中,看你是否想进行前后端的分离.如果你不想进行前后端的分离,可以将vue的项目build之后放到php ...
- (实用篇)使用PHP生成PDF文档
http://mp.weixin.qq.com/s?__biz=MzIxMDA0OTcxNA==&mid=2654254929&idx=1&sn=8715d008d19af70 ...
- php的底层原理
PHP说简单,但是要精通也不是一件简单的事.我们除了会使用之外,还得知道它底层的工作原理. PHP是一种适用于web开发的动态语言.具体点说,就是一个用C语言实现包含大量组件的软件框架.更狭义点看,可 ...
- 【编程技巧】EXTJS中Ext.grid.GridPanel配置项autoExpandColumn的使用方法
autoExpandColumn的作用是自动伸展,占满剩余区域.一般使用在列比较少,并且大多数列都比较窄,有一列比较宽的情况下,当然什么时候使用,还是得按照实际情况确定. 使用的时候主要有三点要注意的 ...
- 怎样用PS对照片进行美白?
摘录自:http://product.pconline.com.cn/itbk/software/ps/1408/5336118.html 步骤1.打开需要美白肤色的照片.本教程为防止侵犯他人肖像权, ...
- 解决eclipse出现This Android SDK requires Andro...date ADT to the latest version.问题
更新完android SDK之后,eclipse出现了“This Android SDK requires Andro...date ADT to the latest version.”问题,这是因 ...
- 简单的线性规划-scipy
根据描述,我们用线性规划带约束来求解问题 # coding=utf-8 from scipy.optimize import linprog import numpy as np def maxGai ...
- synchronized内存可见性理解
一.背景 最近在看<Java并发编程实战>这本书,看到共享变量的可见性,其中说到"加锁的含义不仅仅局限于互斥行为,还包括内存可见性". 我对于内存可见性第一反应是vol ...