C#采用vony.Html.AIO插件批量爬MM网站图片
一、创建项目
1.创建一个.netframework的控制台项目命名为Crawler
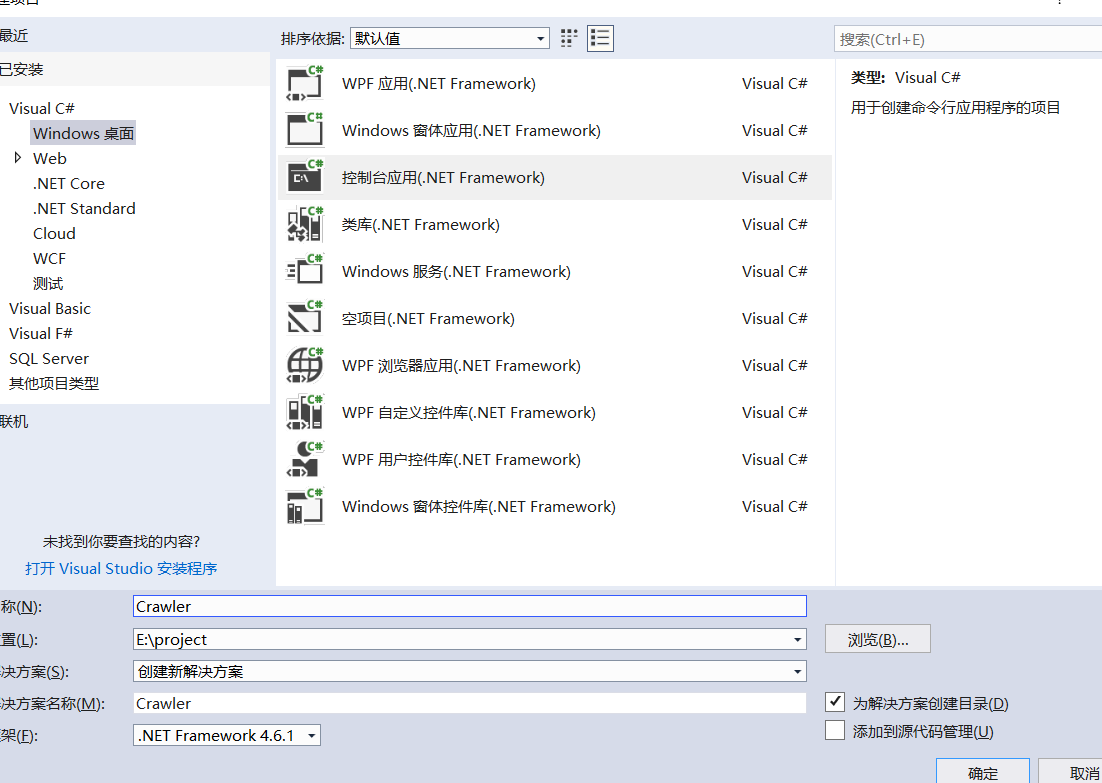
2.安装nuget包搜索名称Ivony.Html.AIO,使用该类库什么方便类似jqury的选择器可以根据类名或者元素类型来匹配元素,无需要写正则表达式。
3.创建一个图片类Image

一、抓取页面图片
1.拿到所有图片页面的地址
本次爬取的网站为https://www.mntup.com/,打开页面进入二级目录https://www.mntup.com/SiWa.html,并查页面看源代码,如下图:

图片页都在class=“dana”的div下面,我们要拿去div中超链接的href,如下格式:
<div class="dana"><a href=/Rosimm/liantiyimeizi_4f4d781d.html title=[Rosi写真]NO.2637_红色吊带高叉连体衣妹子床上狗爬式秀浑圆翘臀撩人诱惑写真38P target=_blank>
[Rosi写真]NO.2637_红色吊带高叉连体衣妹子床上狗爬式秀浑圆翘臀撩人诱惑写真38P <b> <font color=ff0000>2019-02-26</b></font>
</a></div>
首先考虑要拿到所有图片页面的超链接,c#代码下:
//需要定义一个list用来存放所有的页面链接
static List<string> categoryUrl = new List<string>();
//加载url到文档
IHtmlDocument source = new JumonyParser().LoadDocument("https://www.mntup.com/XiuRen.html", System.Text.Encoding.GetEncoding("utf-8"));
//获取所有class=dana的的a标签
var divLinks = source.Find(".dana a");
foreach (var aLink in divLinks)
{
var categoryName = aLink.Attribute("href").Value(); //获取a中的链接
categoryUrl.Add(categoryName);
}
2.打开图片页,发现是带有分页的,那就要获取所有的分页的链接了。分页的地址都在页面当中,所以我们直接匹配就好。
由于每个图片页都有分页地址,所以直接匹配分页地址,C#代码如下:
foreach (var url in categoryUrl)
{
//获取图片也的的文档
IHtmlDocument html = new JumonyParser().LoadDocument($"{address}{url}", System.Text.Encoding.GetEncoding("utf-8"));
//获取每个分页面并下载
var pageLink = html.Find(".page a");
foreach (var alingk in pageLink)
{
string href = alingk.Attribute("href").Value();
Console.WriteLine($"获取分页地址{href}");
}
}
3.所有分页都获取到了,接下来就是要获取页面中的每张图片了,打开页面查看源代码:

观察发现,所有的图片都在class=img的div下面,那就可以从每个分页中直接下载所有的图片了,代码如下:
//获取每一个分页的文档模型
IHtmlDocument htm2 = new JumonyParser().LoadDocument($"{address}{href}", System.Text.Encoding.GetEncoding("utf-8"));
//获取class=img的div下的img标签
var aLink = htm2.Find(".img img");
foreach (var link in aLink)
{
var imgsrc = link.Attribute("src").Value();
Console.WriteLine("获取到图片路径" + imgsrc);
Console.WriteLine($"开始下载图片{imgsrc}>>>>>>>");
DownLoadImg(new Image { Address = address + imgsrc, Title = url });
}
}
图片下载方法如下,为防止下载的时候阻塞主进程,下载采用异步:
/// <summary>
/// 异不下载图片
/// </summary>
/// <param name="image"></param>
async static void DownLoadImg(Image image)
{
using (WebClient client = new WebClient())
{
try
{
int start = image.Address.LastIndexOf("/") + 1;
string fileName = image.Address.Substring(start, image.Address.Length - start);
//图片目录采用页面地址作为文件名
string directory = "c:/images/" + image.Title.Replace("/", "-").Replace("html", "") + "/";
if (!Directory.Exists(directory))
{
Directory.CreateDirectory(directory);
}
await client.DownloadFileTaskAsync(new Uri(image.Address), directory + fileName);
}
catch (Exception)
{
Console.WriteLine($"{image.Address}下载失败");
File.AppendText(@"c:/log.txt");
}
Console.WriteLine($"{image.Address}下载成功");
}
}
三、抓取图片
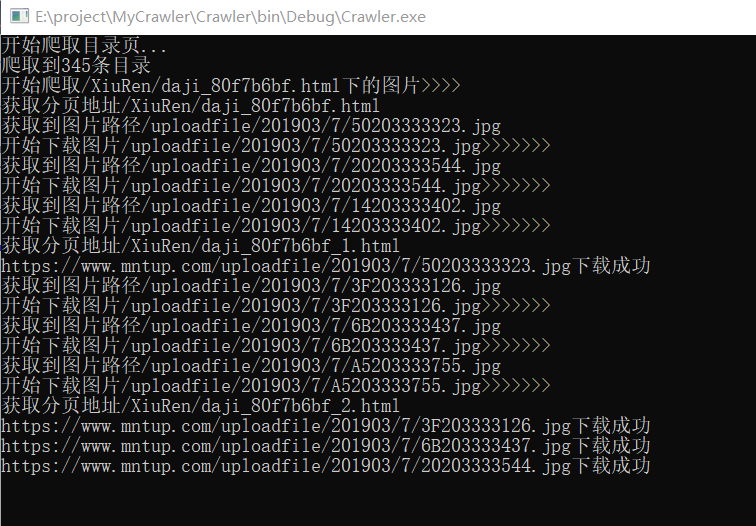
由于编码格式的问题,无法获取到中文标题,所有就采取了页面链接作为目录名称,下面是一张我抓取图片的截图:
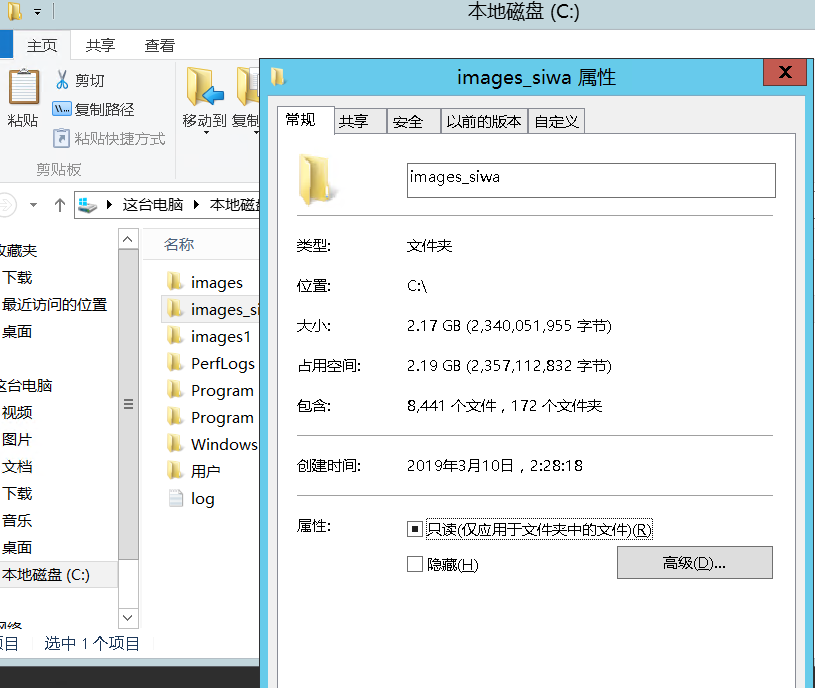
最后的战果:
最后奉上代码如下:https://github.com/peijianmin/MyCrawler.git
C#采用vony.Html.AIO插件批量爬MM网站图片的更多相关文章
- 【Python】批量爬取网站URL测试Struts2-045漏洞
1.概述都懒得写了.... 就是批量测试用的,什么工具里扣出来的POC,然后根据自己的理解写了个爬网站首页URL的代码... #!/usr/bin/env python # -*- coding: u ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- Python3批量爬取网页图片
所谓爬取其实就是获取链接的内容保存到本地.所以爬之前需要先知道要爬的链接是什么. 要爬取的页面是这个:http://findicons.com/pack/2787/beautiful_flat_ico ...
- 使用Python批量爬取美女图片
运行截图 实列代码: from bs4 import BeautifulSoup import requests,re,os headers = { 'User-Agent': 'Mozilla/5. ...
- 使用ajax爬取网站图片()
以下内容转载自:https://www.makcyun.top/web_scraping_withpython4.html 文章关于网站使用Ajaxj技术加载页面数据,进行爬取讲的很详细 大致步骤如下 ...
- Day11 (黑客成长日记) 爬取网站图片
#导入第三方库# coding:utf-8import requests,re #找到需要爬取的网站'http://www.qqjia.com/sucai/sucai1210.htm' #1>获 ...
- 使用python来批量抓取网站图片
今天"无意"看美女无意溜达到一个网站,发现妹子多多,但是可恨一个page只显示一张或两张图片,家里WiFi也难用,于是发挥"程序猿"的本色,写个小脚本,把图片扒 ...
- webmagic 二次开发爬虫 爬取网站图片
webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫. webmagic介绍 编写一个简单的爬虫 webmagic的使用文档:http://w ...
- 使用Jsoup爬取网站图片
package com.test.pic.crawler; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
随机推荐
- Linux 下 Redis 安装与配置
1.Redis 的安装 在 Ubuntu 系统安装 redis 可以使用以下命令: $ sudo apt-get update $ sudo apt-get install redis-server ...
- js万年历,麻雀虽小五脏俱全,由原生js编写
对于前端来说,我们可能见到最多的就是各种各样的框架,各种各样的插件了,有各种各样的功能,比如轮播啊,日历啊,给我们提供了很大的方便,但是呢?我们在用别人这些写好的插件,框架的时候,有没有试着问一问自己 ...
- 微信企业向用户银行卡付款API开发详解(PHP)
最近在实现微信企业向用户银行卡付款时遇到了一些问题,发现官方文档说的太笼统,走了不少弯路,想要在此记录,希望可以帮到大家. 案例:企业付款到银行卡 微信接口链接:https://api.mch. ...
- Jmeter 测试工具
Jmeter的基本概念 百度百科: Apache JMeter是Apache组织开发的基于Java的压力测试工具.用于对软件做压力测试,它最初被设计用于Web应用测试,但后来扩展到其他测试领域. 它可 ...
- Redis之实战篇(与Mybatis整合)
摘要: 现在市面流行的java框架,一个是ssh(spring.struts2.hibernate),另一个是ssm(spring.springmvc.mybatis),由于之前已经有整合过ssm框架 ...
- SSM-MyBatis-02:Mybatis最基础的增删改查(查全部和查单独一个)
------------吾亦无他,唯手熟尔,谦卑若愚,好学若饥------------- 继续上次的开始,这次记录的是增删改查,上次重复过的代码不做过多解释 首先先创建mysql的表和实体类Book ...
- sql server 高可用性技术总结
一. 复制Replication(快照.事务.合并) 应用场景: 负载均衡.提供副本读,写操作. 分区将历史数据复制到其它表中. 授权,将数据提供它人使用. 数据合并. 故障转移. 优点: 实现简单 ...
- PuTTY/终端使用复制、粘贴
Putty鼠标按钮选项 通过鼠标按钮选项可以控制鼠标来进行复制.粘贴操作,选项包括: 1.Windows选项: 2.混合模式(系统默认选项): 3.Xterm模式. 以上是三种模式选项的简单介绍,下面 ...
- adb常用操作命令
1.adb简介: adb,即 Android Debug Bridge.通过这个工具和android进行交互操作 2.adb命令格式: adb [-d|-e|-s <serialNu ...
- ScalaPB(5):用akka-stream实现reactive-gRPC
在前面几篇讨论里我们介绍了scala-gRPC的基本功能和使用方法,我们基本确定了选择gRPC作为一种有效的内部系统集成工具,主要因为下面gRPC支持的几种服务模式: .Unary-Call:独立 ...