Lucene入门案例一
1. 配置开发环境
官方网站:http://lucene.apache.org/
Jdk要求:1.7以上
创建索引库必须的jar包(lucene-core-4.10.3.jar,lucene-analyzers-common-4.10.3.jar)
其他jar包(commons-io-2.4.jar , junit-4.9.jar)
2. 创建索引库
第一步:创建一个java工程,并导入jar包。
第二步:创建一个indexwriter对象。
1)指定索引库的存放位置Directory对象
2)指定一个分析器,对文档内容进行分析。
第二步:创建document对象。
第三步:创建field对象,将field添加到document对象中。
第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。
第五步:关闭IndexWriter对象。
/*
* 创建索引库
*/
@Test
public void createIndex() throws Exception {
//1.指定索引库存放的位置,可以存放在内存中,也可以存放在硬盘中
// Directory directory = new RAMDirectory();//将索引保存在内存中
Directory directory = FSDirectory.open(new File("E:\\temp\\index"));
Analyzer analyzer = new StandardAnalyzer();
//indexwriterconfig中,第一个参数代表Lucene版本号, 第二个参数代表分析器
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LATEST, analyzer );
//2.创建IndexWriter对象, 需要在此之前创建一个分析器(分词)
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
//3.获取文件,使用io流读取文件
File file = new File("E:\\temp\\source_folder");
for (File f : file.listFiles()) {
//获取文件名称
String fileName = f.getName();
//获取文件大小
long fileSize = FileUtils.sizeOf(f);
//获取文件内容
String fileContent = FileUtils.readFileToString(f);
//获取文件路径
String filePath = f.getPath();
//4.创建文档对象
Document document = new Document();
//5.创建域对象,并添加到文档中
//5.1保存文件名 , 需要分析, 需要索引, 需要保存
StringField nameField = new StringField("name", fileName, Store.YES);
//5.2保存文件内容, 需要分析, 需要索引, 不需要保存
TextField contentField = new TextField("content", fileContent, Store.NO);
//5.3保存文件路径, 不分析, 不索引, 要保存
StoredField pathField = new StoredField("path", filePath);
//5.4 保存文件长度,不索引,不分析,要保存
LongField sizeField = new LongField("size", fileSize, Store.YES);
document.add(nameField);
document.add(contentField);
document.add(pathField);
document.add(sizeField);
//6.把文档对象写入索引库
indexWriter.addDocument(document);
}
//7.释放资源
indexWriter.close();
}
3. 查询索引
步骤:
第一步:创建一个Directory对象,也就是索引库存放的位置。
第二步:创建一个indexReader对象,需要指定Directory对象。
第三步:创建一个indexsearcher对象,需要指定IndexReader对象
第四步:创建一个TermQuery对象,指定查询的域和查询的关键词。
第五步:执行查询。
第六步:返回查询结果。遍历查询结果并输出。
第七步:关闭IndexReader对象
IndexSearcher搜索方法
|
方法 |
说明 |
|
indexSearcher.search(query, n) |
根据Query搜索,返回评分最高的n条记录 |
|
indexSearcher.search(query, filter, n) |
根据Query搜索,添加过滤策略,返回评分最高的n条记录 |
|
indexSearcher.search(query, n, sort) |
根据Query搜索,添加排序策略,返回评分最高的n条记录 |
|
indexSearcher.search(booleanQuery, filter, n, sort) |
根据Query搜索,添加过滤策略,添加排序策略,返回评分最高的n条记录 |
TopDocs
Lucene搜索结果可通过TopDocs遍历,TopDocs类提供了少量的属性,如下:
|
方法或属性 |
说明 |
|
totalHits |
匹配搜索条件的总记录数 |
|
scoreDocs |
顶部匹配记录 |
注意:
Search方法需要指定匹配记录数量n:indexSearcher.search(query, n)
TopDocs.totalHits:是匹配索引库中所有记录的数量
TopDocs.scoreDocs:匹配相关度高的前边记录数组,scoreDocs的长度小于等于search方法指定的参数n
/*
* 查询索引库
*/
@Test
public void searchIndex () throws Exception {
//1.指定索引存放的位置
Directory directory = FSDirectory.open(new File("E:\\temp\\index"));
//2.创建IndexReader对象
IndexReader indexReader = DirectoryReader.open(directory);
//3.创建IndexSearcher对象, 该对象构造方法需要IndexReader对象
IndexSearcher indexSearcher = new IndexSearcher(indexReader);
//4.创建一个查询对象,需要指明查询关键字和域名
Query query = new TermQuery(new Term("content", "lucene"));
//5.获取查询结果
TopDocs topDocs = indexSearcher.search(query, 10);
//打印查询的总记录数
System.out.println("查询的总记录数为: " + topDocs.totalHits);
for (ScoreDoc scoreDoc : topDocs.scoreDocs) {
//6.便利打印查询结果
//获取document的id
int docID = scoreDoc.doc;
System.out.println("文档id为: --> " + docID);
//根据id查询document对象
Document document = indexSearcher.doc(docID);
//根据document对象获取相应的信息
System.out.println("文档名称: " + document.get("name"));
System.out.println("文档路径: " + document.get("path"));
System.out.println("文档大小: " + document.get("size"));
System.out.println("文档内容: " + document.get("content"));
}
//7.关闭indexreader
indexReader.close();
}
4. 分析器测试
4.1 分析器(Analyzer)的执行过程
如下图是语汇单元的生成过程:

从一个Reader字符流开始,创建一个基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Token。
要看分析器的分析效果,只需要看Tokenstream中的内容就可以了。每个分析器都有一个方法tokenStream,返回一个tokenStream对象。
4.2 分词器测试
/*
* 标准分析器测试
*/
@SuppressWarnings("resource")
@Test
public void testAnalyzer () throws Exception {
//1.创建一个分析器对象
Analyzer analyzer = new StandardAnalyzer();
// Analyzer analyzer = new IKAnalyzer(); //IK-analyzer分词器
//2.从分析器对象中获取tokenStream
//第一个参数为fieldname, 域名称,可以为null或者是""
//第二个参数为需要解析的字符串
TokenStream tokenStream = analyzer.tokenStream("", "小新喜欢白富美");
//3.设置一个引用,引用可以有多种类型,可以是关键词引用、偏移量引用等
CharTermAttribute charTermAttribute = tokenStream.addAttribute(CharTermAttribute.class);
OffsetAttribute offsetAttribute = tokenStream.addAttribute(OffsetAttribute.class);
//4.调用tokenStream的reset方法,重置指针
tokenStream.reset();
//5.使用while循环便利单词表
while (tokenStream.incrementToken()) {
//6.打印单词
System.out.println("关键词的起始位置-->" + offsetAttribute.startOffset());
System.out.println("关键词:-->" + charTermAttribute);
System.out.println("关键词的结束位置-->" + offsetAttribute.endOffset());
}
//7.关闭tokenStream
tokenStream.close();
}
4.3 中文分析器
1.Lucene自带中文分词器
StandardAnalyzer:
单字分词:就是按照中文一个字一个字地进行分词。如:“我爱中国”,
效果:“我”、“爱”、“中”、“国”。
CJKAnalyzer
二分法分词:按两个字进行切分。如:“我是中国人”,效果:“我是”、“是中”、“中国”“国人”。
上边两个分词器无法满足需求。
SmartChineseAnalyzer
对中文支持较好,但扩展性差,扩展词库,禁用词库和同义词库等不好处理
2.第三方中文分析器
- paoding: 庖丁解牛最新版在 https://code.google.com/p/paoding/ 中最多支持Lucene 3.0,且最新提交的代码在 2008-06-03,在svn中最新也是2010年提交,已经过时,不予考虑。
- mmseg4j:最新版已从 https://code.google.com/p/mmseg4j/ 移至 https://github.com/chenlb/mmseg4j-solr,支持Lucene 4.10,且在github中最新提交代码是2014年6月,从09年~14年一共有:18个版本,也就是一年几乎有3个大小版本,有较大的活跃度,用了mmseg算法。
- IK-analyzer: 最新版在https://code.google.com/p/ik-analyzer/上,支持Lucene 4.10从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。从3.0版本开 始,IK发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。在2012版本中,IK实现了简单的分词 歧义排除算法,标志着IK分词器从单纯的词典分词向模拟语义分词衍化。 但是也就是2012年12月后没有在更新。
- ansj_seg:最新版本在 https://github.com/NLPchina/ansj_seg tags仅有1.1版本,从2012年到2014年更新了大小6次,但是作者本人在2014年10月10日说明:“可能我以后没有精力来维护ansj_seg了”,现在由”nlp_china”管理。2014年11月有更新。并未说明是否支持Lucene,是一个由CRF(条件随机场)算法所做的分词算法。
- imdict-chinese-analyzer:最新版在 https://code.google.com/p/imdict-chinese-analyzer/ , 最新更新也在2009年5月,下载源码,不支持Lucene 4.10 。是利用HMM(隐马尔科夫链)算法。
- Jcseg:最新版本在git.oschina.net/lionsoul/jcseg,支持Lucene 4.10,作者有较高的活跃度。利用mmseg算法。
4.4 IK-analyzer中文分析器的使用方法
使用方法:
第一步:把jar包添加到工程中
第二步:把配置文件和扩展词典和停用词词典添加到classpath下
注意:mydict.dic和ext_stopword.dic文件的格式为UTF-8,注意是无BOM 的UTF-8 编码。
4.5 分词器的使用时机
索引时使用Analyzer
输入关键字进行搜索,当需要让该关键字与文档域内容所包含的词进行匹配时需要对文档域内容进行分析,需要经过Analyzer分析器处理生成语汇单元(Token)。分析器分析的对象是文档中的Field域。当Field的属性tokenized(是否分词)为true时会对Field值进行分析,如下图:
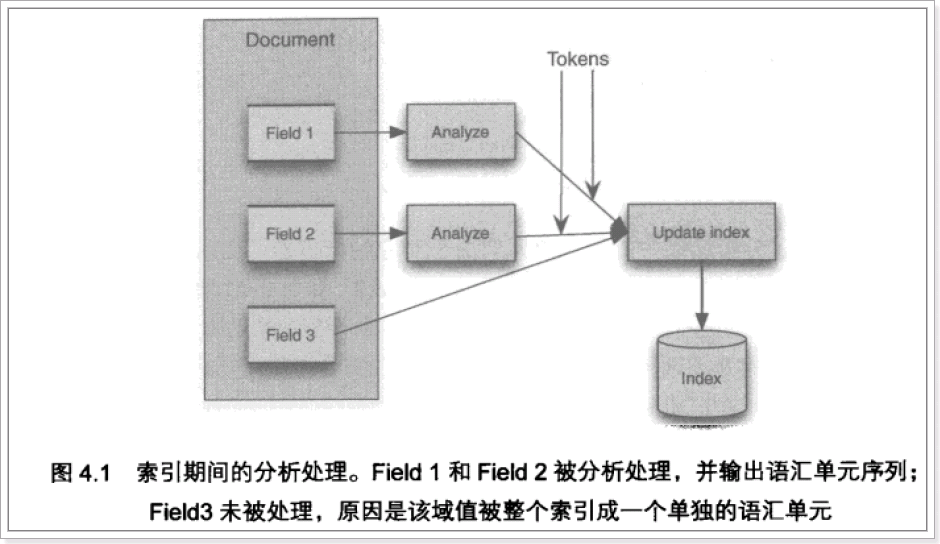
对于一些Field可以不用分析:
1、不作为查询条件的内容,比如文件路径
2、不是匹配内容中的词而匹配Field的整体内容,比如订单号、身份证号等。
搜索时使用Analyzer
对搜索关键字进行分析和索引分析一样,使用Analyzer对搜索关键字进行分析、分词处理,使用分析后每个词语进行搜索。比如:搜索关键字:spring web ,经过分析器进行分词,得出:spring web拿词去索引词典表查找 ,找到索引链接到Document,解析Document内容。
对于匹配整体Field域的查询可以在搜索时不分析,比如根据订单号、身份证号查询等。
注意:搜索使用的分析器要和索引使用的分析器一致。
5. 索引库的添加
向索引库中添加document对象。
第一步:先创建一个indexwriter对象
第二步:创建一个document对象
第三步:把document对象写入索引库
第四步:关闭indexwriter。
/**
* 根据索引库的位置,创建indexwriter
*/
public static IndexWriter getIndexWriter() throws IOException {
//1.指定索引库存放的位置
Directory directory = FSDirectory.open(new File("E:\\temp\\index"));
//2.创建IndexWriter对象,需要创建一个解析器和IndexWriterConfig
Analyzer analyzer = new IKAnalyzer();
IndexWriterConfig indexWriterConfig = new IndexWriterConfig(Version.LATEST, analyzer);
IndexWriter indexWriter = new IndexWriter(directory, indexWriterConfig);
return indexWriter;
}
//添加文档
@Test
public void addDocument () throws Exception {
IndexWriter indexWriter = getIndexWriter();
//3.创建文档对象
Document document = new Document();
//4.创建域对象
TextField nameField = new TextField("name", "小新文档", Store.YES);
TextField contentField = new TextField("content", "小新喜欢白富美", Store.YES);
//5.将域对象添加到文档对象中
document.add(nameField);
document.add(contentField);
//6.将文档对象写入索引
indexWriter.addDocument(document);
//7.关闭IndexWriter
indexWriter.close();
}
6. 索引库的删除
6.1 删除全部
//删除所有索引
@Test
public void deleteAllIndex () throws Exception {
//获取IndexWriter对象
IndexWriter indexWriter = getIndexWriter();
//调用indexWriter中的方法删除索引
indexWriter.deleteAll();
//释放资源
indexWriter.close();
}
6.2 根据查询删除
//根据查询条件删除索引
@Test
public void deleteQueryIndex () throws Exception {
//获取IndexWriter
IndexWriter indexWriter = getIndexWriter();
//制定查询条件
Query query = new TermQuery(new Term("content", "小新"));
//删除制定查询条件下的文档
indexWriter.deleteDocuments(query);
//释放资源
indexWriter.close();
}
7. 索引库的更新
//更新索引库
@Test
public void updateIndex () throws Exception {
//1.获取indexwriter对象
IndexWriter indexWriter = getIndexWriter();
//2.查询的过程是,制定要删除的term的字段及关键字,先根据term查询,然后删除该查询结果, 然后添加doucment对象
Document document = new Document();
document.add(new TextField("name", "更新后的文档", Store.YES));
document.add(new TextField("content", "更新后的文档内容", Store.YES));
indexWriter.updateDocument(new Term("content", "treat "), document);
//3.释放资源
indexWriter.close();
}
Lucene入门案例一的更多相关文章
- SpringMVC入门案例及请求流程图(关于处理器或视图解析器或处理器映射器等的初步配置)
SpringMVC简介:SpringMVC也叫Spring Web mvc,属于表现层的框架.Spring MVC是Spring框架的一部分,是在Spring3.0后发布的 Spring结构图 Spr ...
- SpringMvc核心流程以及入门案例的搭建
1.什么是SpringMvc Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面.Spring 框架提供了构建 Web 应用程序的全功能 M ...
- Struts2第一个入门案例
一.如何获取Struts2,以及Struts2资源包的目录结构的了解 Struts的官方地址为http://struts.apache.org 在他的主页当中,我们可以通过左侧的Apache ...
- MyBatis入门案例、增删改查
一.MyBatis入门案例: ①:引入jar包 ②:创建实体类 Dept,并进行封装 ③ 在Src下创建大配置mybatis-config.xml <?xml version="1.0 ...
- Hibernate入门案例及增删改查
一.Hibernate入门案例剖析: ①创建实体类Student 并重写toString方法 public class Student { private Integer sid; private I ...
- Quartz应用实践入门案例二(基于java工程)
在web应用程序中添加定时任务,Quartz的简单介绍可以参看博文<Quartz应用实践入门案例一(基于Web应用)> .其实一旦学会了如何应用开源框架就应该很容易将这中框架应用与自己的任 ...
- Quartz应用实践入门案例一(基于Web环境)
Quartz是一个完全由java编写的开源作业调度框架,正是因为这个框架整合了许多额外的功能,所以在使用上就显得相当容易.只是需要简单的配置一下就能轻松的使用任务调度了.在Quartz中,真正执行的j ...
- MyBatis入门案例 增删改查
一.MyBatis入门案例: ①:引入jar包 ②:创建实体类 Dept,并进行封装 ③ 在Src下创建大配置mybatis-config.xml <?xml version="1.0 ...
- Hibernate入门案例 增删改
一.Hibernate入门案例剖析: ①创建实体类Student 并重写toString方法 public class Student { private Integer sid; private I ...
随机推荐
- HBase写数据
1 多HTable并发写 创建多个HTable客户端用于写操作,提高写数据的吞吐量,一个例子: static final Configuration conf = HBaseConfiguration ...
- Universal-Image-Loader,android-Volley,Picasso、Fresco和Glide图片缓存库的联系与区别
Universal-Image-Loader,android-Volley,Picasso.Fresco和Glide五大Android开源组件加载网络图片比较 在Android中的加载网络图片是一件十 ...
- vi/vim下看十六进制文件
:%!xxd --将当前文本转换为16进制格式. 查看内容是对应的.你可以后面看到对应的字符内容 :%!od --将当前文本转换为16进制格式. :%!xxd -c 12--将当前文本转换为16进制格 ...
- Centos下grep命令简介
grep命令简介 grep 是一个最初用于Unix操作系统的命令行工具.在给出文件列表或标准输入后,grep会对匹配一个或多个正则表达式的文本进行搜索,并只输出匹配(或者不匹配)的行或文本. grep ...
- hibernate链接数据库链接池c3p0配置
[html] view plain copy <bean id="dataSourceLocal" name="dataSource" class=&qu ...
- 【Qt编程】基于Qt的词典开发系列<十三>音频播放
在上一篇文章中,我是在Qt4平台上调用本地发音的,后来由于用到JSON解析,就将平台转到了Qt5,因为Qt5自带解析JSON的类.然后发现上一篇文章的方法无法运行,当然网上可以找到解决方法,我在这里直 ...
- 【Android 应用开发】对Android体系结构的理解--后续会补充
1.最底层_硬件 任何Android设备最底层的硬件包括 显示屏, wifi ,存储设备 等. Android最底层的硬件会根据需要进行裁剪,选择自己需要的硬件. 2.Linux内核层 该层主要对硬件 ...
- 详解linux进程间通信-消息队列
前言:前面讨论了信号.管道的进程间通信方式,接下来将讨论消息队列. 一.系统V IPC 三种系统V IPC:消息队列.信号量以及共享内存(共享存储器)之间有很多相似之处. 每个内核中的 I P C结构 ...
- 深入浅出web服务器与python应用程序之间的联系
简单来说,Web服务器是在运行在物理服务器上的一个程序,它永久地等待客户端(主要是浏览器,比如Chrome,Firefox等)发送请求.Web 服务器接受 Http Request,返回 Respon ...
- python MultiProcessing标准库使用Queue通信的注意要点
今天原本想研究下MultiProcessing标准库下的进程间通信,根据 MultiProcessing官网 给的提示,有两种方法能够来实现进程间的通信,分别是pipe和queue.因为看queue顺 ...