自动化运维:使用flask+mysql+highcharts搭建监控平台
1.前言
本来想做一个比较完善的监控平台,只需要做少许改动就可以直接拿来用,但是在做的过程中发现要实现这个目标所需的工作量太大,而当前的工作中对其需求又不是特别明显。所以就退而求其次,做了一个类似教程系统的东西。在这个系统中,你应该可以找到做一个监控系统所需要的大部分技术点,而它的真正意义就在于其打通了整个数据流转的环节。
先上一个效果图:
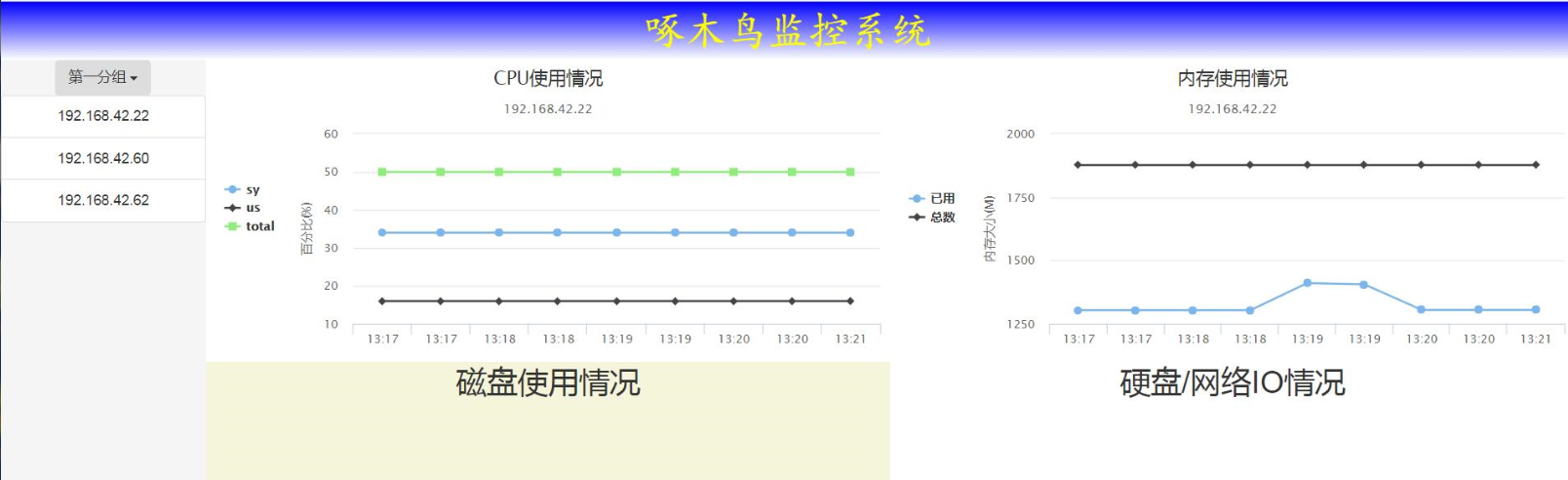
因为只是做了一个简单的验证,所以只有内存曲线有变动,CPU使用情况没变化。X轴的坐标有时间重复,是由于数据里面有相同的IP地址造成的。
磁盘使用情况、硬盘/网络IO的实现过程和内存、CPU类似,所以就没有具体实现。需要特别说明的是: 数据采用的拉的方式,所以目标机只能执行shell命令,磁盘使用情况的处理,尤其是IO情况的处理,比较麻烦。但是其好处是不需要在目标机器上安部署任何东西,只需要一个有权限执行shell命令的账号即可。如果不介意部署麻烦问题,可以在每个目标机上安装psutil包,可以很方便的获取系统信息,但是我看了看大部分系统自带的python都是2.7版本的,而psutil包需要3.0版本以上的。
2.遇到的问题
把开发过程中遇到的问题放到前面说,是为了避免大家遇到相同的问题,从而走了弯路。
2.1 flask-sqlalchemy
这个是我最想吐槽的地方:如果一个ORM框架的使用成本和排查错误的成本远远超过了直接使用sql语句的成本,那么你还有啥存在的意义?
(1)from flask_sqlalchemy import SQLAlchemy #python3 的写法
(2)安装2.1版本,最新2.3有问题,2.2不确定。使用pip按照的方法为:pip install flask-sqlalchemy==2.1
(3)2.1版本应该也有问题,因为app、models、database三个功能类文件分开的话,只有第一次读取数据是从数据库读取,剩下的读取过程好像都是从内存中读取的。但是如果把所有的内容都放到app文件中就不存在这个问题(这就是我把所有内容都放到一个文件的原因)。这也是目前我能找到的唯一的一个解决方式,如果有其他方式可以解决这个问题,请大家在下面留言告诉我,谢谢。
针对这个问题,我也咨询了几位群里朋友的意见,他们的建议就是最好使用sql直接操作数据库,不仅方便灵活可控,还可以减少框架本身的缺陷引起的莫名其妙的问题。这点我是深有同感,第一次是使用pip安装的flask-sqlalchemy 2.3,一堆莫名其妙的问题,查来查去原来是版本问题引起的。因为是使用pip安装的,所以当时没有考虑版本的问题。
2.2 关于测试机器IP的问题
如果测试过程中,目标机器就一个,IP地址也就一个,这种情况下频繁读取该机器的系统信息,由于机器的保护机制耗费的时间会阶段性变长,建议多连接几台机器测试或者挂几个VIP试试。
2.3 关于提高的SQL脚本
我把整个项目文件上传到了github上,项目中包含的sql脚本如果是在windows下的mysql中执行,需要把create语句整理成一行,否则会创建失败。linux下的mysql中没有这个问题。
3.系统组成及主要工具包
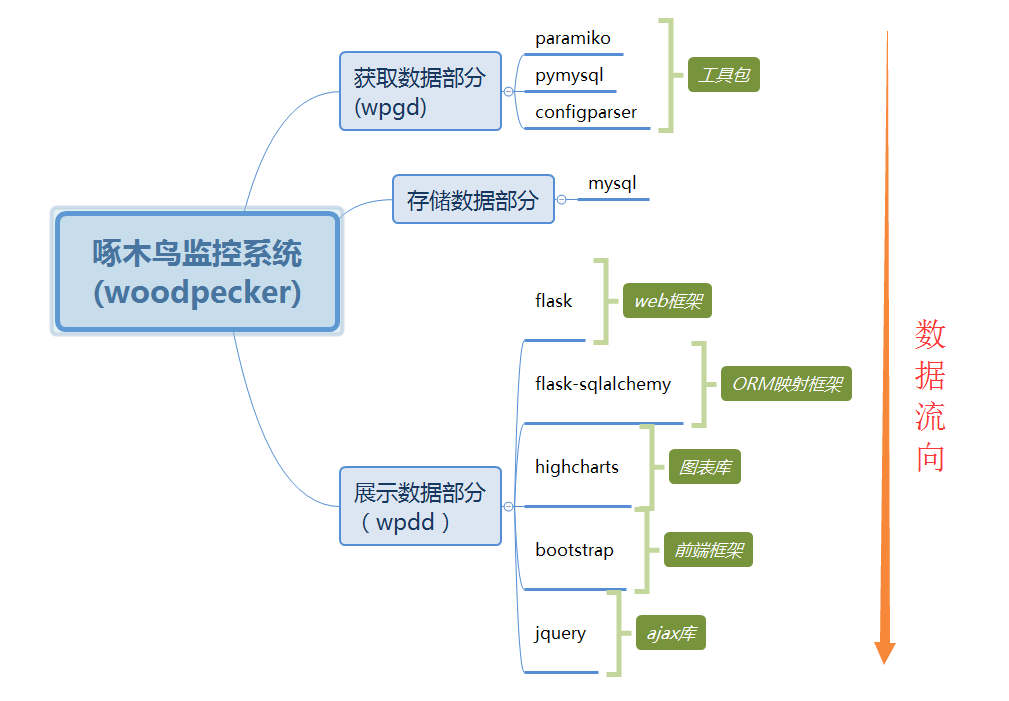
4.技术点详解
完整的项目及文件内容见:https://github.com/lichao1217/woodpecker
4.1 获取数据部分
(1)通过SSH的方式连接目标机器(完整代码:\woodpecker\wpgd\serverconn.py)
import paramiko #引用封装SSH连接方式的工具包
#返回一个连接
#host:ip地址 username:用户名 pwd 密码
def get_connection(host,username,pwd):
try:
client = paramiko.SSHClient()
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
client.connect(host,22,username,pwd)
return client
except Exception as e:
return None
(2)使用configparser工具包读取连接mysql数据库的配置,并返回一个mysql连接(完整代码:\woodpecker\wpgd\DBconn.py)
def __get_dbconn(self):
try: _config = configparser.ConfigParser()
_config.read(self._configPath)
host = _config.get("dbconfig","host") #主机IP地址
dbusername = _config.get("dbconfig","dbusername") #数据库用户名
dbuserpwd = _config.get("dbconfig","dbuserpwd") #数据库用户密码
dbname = _config.get("dbconfig","dbname") #数据库名称
db = pymysql.connect(host,dbusername,dbuserpwd,dbname)
return db
except Exception as e:
return None
(3)使用pymysql读取数据(完整代码:\woodpecker\wpgd\DBconn.py)
def get_serverList(self,sqltext):
db = self.__get_dbconn()
if db is None:
return 0 #0表示连接数据库失败
else :
try:
cursor = db.cursor()
cursor.execute(sqltext) #执行sql语句
results = cursor.fetchall() #读取全部结果
return results
except Exception as e:
return -1 # -1 表示读取数据失败,有可能SQL语句不对
finally :
db.close()
4.2读取数据部分(代码都在app.py 和index.html中)
(1)flask-sqlalchemy连接mysql
from flask_sqlalchemy import SQLAlchemy #python3 的写法
app = Flask(__name__)
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql+pymysql://woodpecker:woodpecker@localhost/woodpecker'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False #是否
app.config['SQLALCHEMY_COMMIT_ON_TEARDOWN'] = True
db = SQLAlchemy(app)
详细配置参数见:http://www.pythondoc.com/flask-sqlalchemy/config.html
(2)models定义部分
这里只有2点需要注意:
第一:如果定义的类名和表名不一致,需要使用__tablename__参数说明(__是双下划线),例如: __tablename__ = 't_servers'
第二:表必须要有主键
(3)无参数读取数据库数据
html部分:
<ul id="serverlist" class="dropdown-menu" role="menu" aria-labelledby="dropdownMenu1">
{% for group in groupList %}
<li><a role="menuitem" href="#" >{{ group.groupname }}</a></li>
<li class="divider"></li>
{% else %}
<li><a role="menuitem" href="#">读取服务器分组失败</a></li>
{% endfor %}
</ul>
{{ group.groupname }} 这是flask表示变量的方式,并且上述代码中的class都是在bootstrap中定义的。
python部分:
def index():
groupList = Group.query.all()
return render_template('index.html', groupList=groupList)
Group.query.all() 这是flask-sqlalchemy查询数据的方式
(4)页面传参数到后台读取数据
html部分(ajax):
var data = {'ip':ip}; //ip是传到后台的参数
$.ajax({
type:'post',
async:false,
url:"/get_sys_info", //接收参数的后台路由函数
data:data,
success:function (result) {
drawchart(result,ip) //此函数是接收到返回的结果后做前台处理的
;}
});
python部分:
@app.route('/get_sys_info', methods=['POST','GET'])
def getSysInfo():
ip = request.form.get("ip")
.......
(5)动态添加li元素
有两种方式:
第一种在页面装载过程中动态添加li元素及点击事件:
//给服务器列表的下拉框每个li元素添加点击事件
window.onload = function () {
var obj_lis = document.getElementById("serverlist").getElementsByTagName("li");
for(var i=0;i<obj_lis.length;i++)
{
obj_lis[i].onclick = function()
{
getiplist(this.innerText);
}
}
}
//根据选择的分组设置btn的现实,并读取当前分组下的ip列表
function getiplist(groupname)
{
var btn=document.getElementById("dropdownMenu1");
//直接给btn.innerText = groupname,表示下来的倒三角不显示
btn.innerHTML=groupname+"<span class=\"caret\"></span>";
getipList(groupname)
}
第二种当页面装载完成后点击页面元素局部刷新添加li元素及点击事件
//添加ip地址到ul中
function addIPToUL(data){
delIPFromUL();
var ip_str = String(data);
var ips = ip_str.split(",");
//alert(ips[0]);
for(var i=0;i<ips.length;i++)
{
var li = document.createElement("li");
li.setAttribute("class","list-group-item");
li.innerText=ips[i];
li.onclick=getSysInfo;
document.getElementById("iplist").appendChild(li);
}
}
(6)动态删除li元素
//选择新分组之后需要清空当前的ip地址
function delIPFromUL() {
var obj_ul = document.getElementById("iplist");
var obj_lis = document.getElementById("iplist").getElementsByTagName("li");
var cnt = obj_lis.length;
//alert(cnt);
if(cnt>0) {
for (var i=cnt-1;i>=0;i--){
var m_li=obj_lis[i];
obj_ul.removeChild(m_li);
}
} }
(7)定时刷新函数
setInterval(function () {
//alert("开始执行");
getSysInfo();
}, 60000);
这里需要说一下,定时函数中执行的函数最好紧跟着定时函数,否则容易识别不了。
(8)时间格式转换
js好像没有自带的时间转换格式函数,所以引入了moment.js来处理时间格式。
(9)highcharts
html部分:
<div id="chart_cpu" style="height: 50%;width: 50%;background: white;float: left"></div>
js部分:
//CPU显示
var options_cpu ={
chart:{
type:'line'
},
title:{
text:'CPU使用情况'
},
subtitle:{
text:ip
},
xAxis:{
type:"datetime",
dateTimeLabelFormat:{
day:'%H:%M'
},
labels:{
overflow:'justify'
},
categories:data["time"]
},
yAxis:{
title:{
text:'百分比(%)'
}
},
legend:{
layout: "vertical",
align:'left',
verticalAlign: "middle"
},
credits:{
enabled:false
},
series:[{
name:'sy',
data:data["sy"]
},
{
name:'us',
data:data["us"]
},
{
name:'total',
data:data["totalcpu"]
}]
};
$('#chart_cpu').highcharts(options_cpu);
python部分:
@app.route('/get_sys_info', methods=['POST','GET'])
def getSysInfo():
ip = request.form.get("ip")
#倒序排列去除最近10条数据
sysinfos = SysInfo.query.filter_by(serverip=ip.strip()).order_by(SysInfo.id.desc()).limit(10).all()
#重新处理成正序
sysinfolist = []
for i in range(len(sysinfos)-1, 0, -1):
sysinfolist.append(sysinfos[i])
print(sysinfolist[0].id)
cpudic = getCPUinfoList(sysinfolist)
memdic = getMeminfoList(sysinfolist)
sysinfodic = dict(cpudic, **memdic)
sysinfodic = jsonify(sysinfodic)
return sysinfodic
(10) div排列
<div id="mainchart" style="height: 80%;width:87%;background: #8c8c8c;position: absolute;margin-left: 13%">
<div id="chart_cpu" style="height: 50%;width: 50%;background: white;float: left"></div>
<div id="chart_mem" style="height: 50%;width: 50%;background:beige;float: right" ></div>
<div id="chart_disk" style="height: 50%;width: 50%;background: beige;float: left;text-align: center;font-size: 30px">磁盘使用情况</div>
<div id="chart_io" style="height: 50%;width: 50%;background:white;float: right;text-align: center;font-size: 30px" >硬盘/网络IO情况</div>
</div>
5.总结
按照上述提到的知识点就可以搭建出来一个自己的监控系统。需要完善的就是highcharts的显示问题了,这个可以参考下相关资料设置成自己满意的显示方式。
当然,由于本人水平有限,其中难免有不足的地方,欢迎大家提出来,多做交流,共同进步。
自动化运维:使用flask+mysql+highcharts搭建监控平台的更多相关文章
- 《Python自动化运维之路》 业务服务监控(二)
文件内容差异对比方法 使用diffie模块实现文件内容差异对比.dmib作为 Python的标准库模块,无需安装,作用是对比文本之间的差异,且支持输出可读性比较强的HTML文档,与 Linux下的di ...
- 自动化运维——一键安装MySQL
根据项目需要,前段时间在搞EMM系统各种安装包的自动化部署工作,主要包括一键安装和一键启动\停止功能.总结记录下来,以供后用. 本文主要是自动安装MySQL5.7.11版,Linux版脚本在CentO ...
- 自动化运维:网站svn代码上线更新(flask+saltstack)
阶段性总结: 跌跌撞撞的用了一周左右的时间做完了网站自动升级功能,中间遇到了很多的问题,也学到了很多,在此做一个总结. 1.整体架构: 后台:nginx+uwsgi #nginx提供w ...
- 自动化运维—tomcat服务起停(mysql+shell+django+bootstrap+jquery)
项目简介: 项目介绍:自动化运维是未来的趋势,最近学了不少东西,正好通过这个小项目把这些学的东西串起来,练练手. 基础架构: 服务器端:web框架-Django 前端:html css jQuery ...
- Inception介绍(MySQL自动化运维工具)
Inception介绍 GitHub:https://github.com/mysql-inception/inception 文档:https://mysql-inception.github.io ...
- 部署MySQL自动化运维工具inception+archer
***************************************************************************部署MySQL自动化运维工具inception+a ...
- 有赞MySQL自动化运维之路—ZanDB
有赞MySQL自动化运维之路—ZanDB 一.前言 在互联网时代,业务规模常常出现爆发式的增长.快速的实例交付,数据库优化以及备份管理等任务都对DBA产生了更高的要求,单纯的凭借记忆力去管理那几十 ...
- mysql操作及自动化运维
备份恢复工具:percona-xtrabackup-2.0.0-417.rhel6.x86_64.rpm mysql主从配置命令: 主: 1.编辑主MYSQL 服务器的MySQL配置文件my.cnf, ...
- 有赞 MySQL 自动化运维之路 — ZanDB
转自:https://tech.youzan.com/youzan-mysql-auto-ops-road/ 一.前言 在互联网时代,业务规模常常出现爆发式的增长.快速的实例交付,数据库优化以及备份管 ...
随机推荐
- redis配置文件详解及实现主从同步切换
原理:redis复制是怎么进行工作 如果设置了一个slave,不管是在第一次链接还是重新链接master的时候,slave会发送一个同步命令 然后master开始后台保存,收集所有对修改数据的命令.当 ...
- 如何使用 RESTClient 调试微信支付接口
我们知道微信支付使用http协议进行api调用,body 使用xml格式,使用的一般http在线调试工具,无法进行xml数据的post. RESTClient 做的很好,支持各种http 方法,bod ...
- runtime.getruntime.availableprocessors
1:获取cpu核心数: Runtime.getRuntime().availableProcessors(); 创建线程池: Executors.newFixedThreadPool(nThreads ...
- [BZOJ 2064]分裂
2064: 分裂 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 572 Solved: 352[Submit][Status][Discuss] De ...
- 【IntelliJ IDEA】使用idea解决新建jsp文件而找不到jsp文件模版的新建选项
使用idea解决新建jsp文件而找不到jsp文件模版的新建选项,这样每次创建一个新的jsp文件岂不是很耗时间? 解决办法: 就是要让idea知道你需要在这个目录下创建jsp文件 左上角,file中点击 ...
- Software Engineering-HW8 个人总结
Software Engineering-HW8 个人总结 2017282110264 李世钰 一.请参考第一次作业,当初你对课程的承诺和期望都兑现了吗? 大致实现了.经过了最后的团队项目,基本了解一 ...
- 关于from nltk.book import * 报错解决方法
import nltk nltk.download() 在使用上面命令安装了nltk库并运行下载后,再输入from nltk.book import * 往往会出现这样的错误提示: 出现这种错误往往是 ...
- 201621123057 《Java程序设计》第12周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多流与文件相关内容. 2. 面向系统综合设计-图书馆管理系统或购物车 使用流与文件改造你的图书馆管理系统或购物车. 2.1 简述如何 ...
- verilog学习笔记(1)_两个小module
第一个小module-ex_module module ex_module( input wire sclk,//声明模块的时候input变量一定是wire变量 input wire rst_n,// ...
- The method getTextContent() is undefined for the type Node
eclipse 中 如果加入了 其他了xfire 等其他xml解析包的话,使用org.w3c.dom.Node下的getTextContent()方法会出现The method getTextCont ...