【完整项目】使用Scrapy模拟HTTP POST,获取完美名字
1. 背景
最近有人委托我给小孩起个名字,说名字最好符合周易五行生克理论,然后给了我个网址,说像是这个网站中的八字测名,输入名字和生辰八字等信息,会给出来这个名字的分数和对未来人生的预测。当父母的自然是希望子女一生顺利,远离病痛意外什么的,抱着宁可信其有,不可信其无的想法。
网址如下
https://www.threetong.com/ceming/
2. 思路
现在已有的信息是姓和生辰八字,需要得到的是名字,由于小孩父母是想要两个字的名字,那么可以细化到字1和字2。把这些信息输入到网站,会得到两个具有指标性的分数:姓名理数评分和姓名配合八字评分,如果两个分数是个好分数,比如两个都是100,或者高于95,那么这个名字可以进入到备选的表单中。我可以比如说弄十万个常用名字输入到这个网站,配合生辰八字,每个名字都能有个得分。按分数从高到低排序,形成一个名字列表,最后给小孩父母自己筛选,选择符合眼缘的,喜欢读音和意义的等等,那就是他们主观的选择了。至少这样,无论起哪个名字,都符合周易五行理论,得到一生的平安幸福。
3. 具体步骤
A,获取用于起名字的常用字列表
由于是两个字的名字,那么字1和字2都可以用这个列表,然后用个循环来形成字1和字2的每种可能组合。我选取了一个800个子的列表,这样,最终输入的名字就有800x800,640000个名字。获取的代码是很基础Scrapy获取网站上的信息,如下:
#spider的代码
# -*- coding: utf-8 -*-
import scrapy
from getName.items import GetnameItem class DownnameSpider(scrapy.Spider):
name = 'downName'
start_urls = ['http://xh.5156edu.com/xm/nu.html'] #默认的http request
# 默认的http request返回的http response的处理函数,是个回调函数。
def parse(self, response):
item = GetnameItem()
item['ming'] = response.xpath('//a[@class="fontbox"]/text()').extract()
yield item
#定义了一个item来存获取的字
import scrapy class GetnameItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
ming = scrapy.Field()
其余部分就是Scrapy框架自动生成的代码了
B,以两个字组合得到的名字,加以姓和生辰八字,输入到八字测名网站,得到名字的分数列表,过滤掉低分名字,比如低于95分。呈给小孩父母。
4. 难点详解,技巧介绍
A,如何快速地到网页上被抓去对象的xpath路径
如果你对xpath语法很了解,这里就有点多余,直接就可以根据语法规定写出来。如果不是很了解的话,Chrome或者Firefox等浏览器有工具可以帮助你。
以Chrome为例
使用Chrome打开网页,对想获取的对象按右键,选择检查
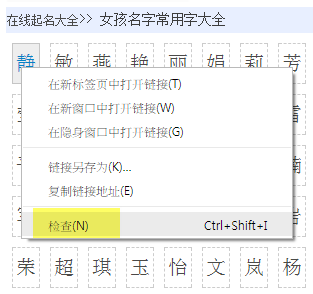
进入Chrome的Developer Tools,找到源码中包含对象的那一列,右键,选择copy,选择copy到XPath
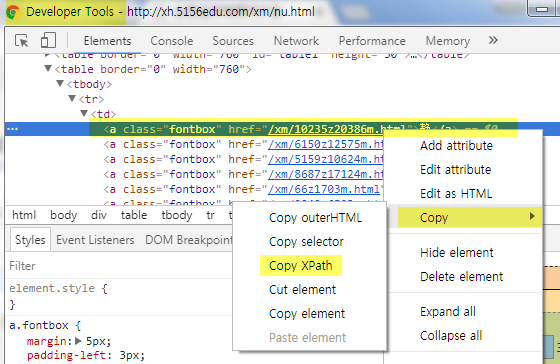
最后在Scrapy中粘贴即可。
这样只能得到这一个标签的内容,即“静”,如果需要获取所有的内容,还是需要对xpath有所了解。如下:
item['ming'] = response.xpath('//a[@class="fontbox"]/text()').extract()
在xpath函数中有个配对字符串,使用了@属性,意思是所有class名字为fontbox的a标签的内容都获取。
如下图所示
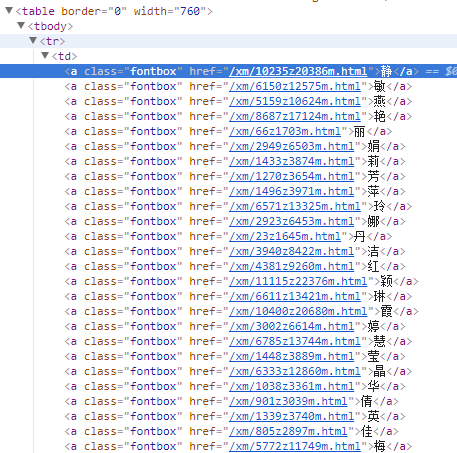
具体参看3.A的代码实现
B,如何在目标网站实现自动输入
自动输入的过程,并不是要找到输入格,往表单里面填写数据,然后模拟去点提交。而是直接模拟HTTP REQUEST向目标WEB PAGE发送数据,比较常见的两种方式,一个是HTTP GET,一个是HTTP POST,通过观察目标网站的链接,我们发现目标网站“https://www.threetong.com/ceming/“是采用了POST,那么是向哪个WEB PAGE发送数据,并且发送的数据表单格式是什么呢,这里就又可以用我们的好朋友,Chrome的Developer Tools了。
首先模拟操作,在”https://www.threetong.com/ceming/”中输入数据
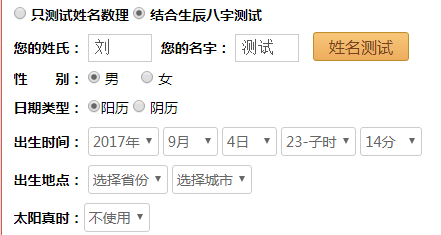
然后可以打开Chrome Developer Tools,查看源码(Elements选项)
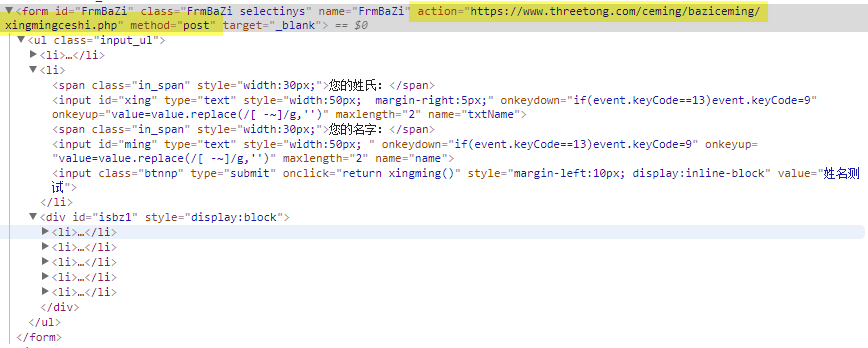
我们可以看到这个form的是采用post的发送方式,发送的目的地是action之后带的页面。
接着点击姓名测试,这样,就会像目标网页发送数据,然后跳转到这个网页

在这个页面,我们点击Chrome的Developer Tool,进入到Network,选择xingmingceshi.php这个网页,点击右侧的Headers,就可以看到这个页面的详细信息了。
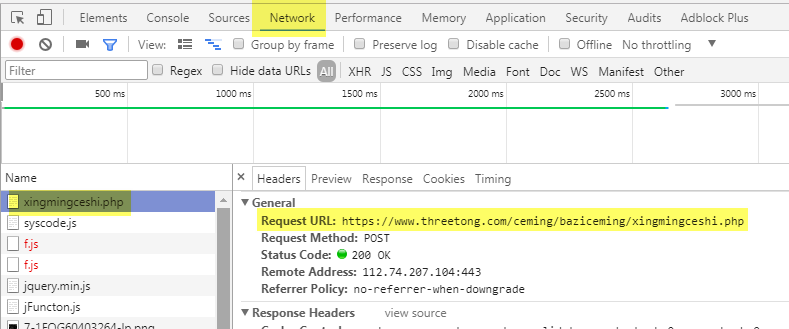
可以看到怎么进入到这个网页的过程,包括Request URL,Request Method是POST,往下面拉,可以看到提交的表单信息
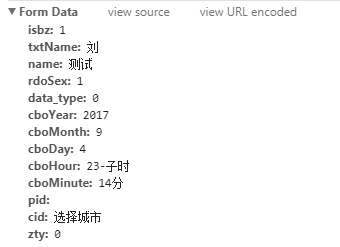
那么,我们只要模拟HTTP POST REQUEST往Request URL发送表单信息就可以了
C,具体代码实现
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
# 定义item来保存最终生成的数据 import scrapy
class DaxiangnameItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
score1 = scrapy.Field()
score2 = scrapy.Field()
name = scrapy.Field()
# -*- coding: utf-8 -*-
import scrapy
import csv
# 引进上面定义的item
from daxiangName.items import DaxiangnameItem class CemingSpider(scrapy.Spider):
name = 'ceming'
# 这是scrapy的一个默认入口函数,程序会从这里开始运行
def start_requests(self):
# 使用一个双循环,打开两个csv文件,每次读取一个字,注意文件的编码,为了防止汉字乱码,使用UTF-8
with open(getattr(self,'file','./ming1.csv'),encoding='UTF-8') as f:
reader = csv.DictReader(f)
for line in reader:
#print(line['\ufeffmingzi'])
with open(getattr(self,'file2','./ming2.csv'),encoding='UTF-8') as f2:
reader2 = csv.DictReader(f2)
for line2 in reader2:
#print(line)
#print(line2)#注意下面的编码,因为从csv读出来,前面多了一个符号,是使用print函数测试出来的
mingzi = line['\ufeffming1']+line2['\ufeffming2']
#print(mingzi)#下面这个函数是核心函数,scrapy定义的模拟发送http post request的函数
FormRequest = scrapy.http.FormRequest(
url='https://www.threetong.com/ceming/baziceming/xingmingceshi.php',
formdata={'isbz':'',
'txtName':u'刘',
'name':mingzi,
'rdoSex':'',
'data_type':'',
'cboYear':'',
'cboMonth':'',
'cboDay':'',
'cboHour':u'20-戌时',
'cboMinute':u'39分',
},
callback=self.after_login #这是指定回调函数,就是发送request之后返回的结果到哪个函数来处理。
)
yield FormRequest #这里很重要,在scrapy中,所有要搜索网页的http request会有一个池子,通过yield函数形成一个iterator generator,往发送池里面积累 def after_login(self, response):
'''#save response body into a file
filename = 'source.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)
'''
# 这里就是从返回的数据中获取分数,下面有个正则表达式的小技巧来获取整数和带有小数点的数字
score1 = response.xpath('/html/body/div[6]/div/div[2]/div[3]/div[1]/span[1]/text()').re('[\d.]+')
score2 = response.xpath('/html/body/div[6]/div/div[2]/div[3]/div[1]/span[2]/text()').re('[\d.]+')
name = response.xpath('/html/body/div[6]/div/div[2]/div[3]/ul[1]/li[1]/text()').extract()
#print(score1)
#print(score2)
print(name)
# 只保留所谓好的分数
if float(score1[0]) >= 90 and float(score2[0]) >= 90:
item = DaxiangnameItem()
item['score1'] = score1
item['score2'] = score2
item['name'] = name
yield item # 这里是输出的池子,形成一个输出的iterator generator,在运行的时候使用-0参数输出所有的items
5. 后记
最后出乎意料返回了4千多个名字,对于最后的人工筛选造成了很大的困难。最后通过对两个输入csv文件的字的删减,得到几十个从各方面都不错的名字。
【完整项目】使用Scrapy模拟HTTP POST,获取完美名字的更多相关文章
- 第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
第三百三十三节,web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录 模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于star ...
- 十二 web爬虫讲解2—Scrapy框架爬虫—Scrapy模拟浏览器登录—获取Scrapy框架Cookies
模拟浏览器登录 start_requests()方法,可以返回一个请求给爬虫的起始网站,这个返回的请求相当于start_urls,start_requests()返回的请求会替代start_urls里 ...
- ETL项目1:大数据采集,清洗,处理:使用MapReduce进行离线数据分析完整项目
ETL项目1:大数据采集,清洗,处理:使用MapReduce进行离线数据分析完整项目 思路分析: 1.1 log日志生成 用curl模拟请求,nginx反向代理80端口来生成日志. #! /bin/b ...
- python用scrapy模拟用户登录
scrapy模拟登录 关注公众号"轻松学编程"了解更多. 注意:模拟登陆时,必须保证settings.py里的COOKIES_ENABLED(Cookies中间件) 处于开启状态 ...
- Node.js:实现知乎(www.zhihu.com)模拟登陆,获取用户关注主题
前一段时间,在瞎看看 Node.js,便研究通过 Node.js 实现知乎模拟登陆.相信,有很多网站有登陆权限设置,如若用户未登陆,将会跳转至首页提醒用户登陆,无法浏览部分页面. 如若是 b/s 架构 ...
- scrapy模拟登录微博
http://blog.csdn.net/pipisorry/article/details/47008981 这篇文章是介绍使用scrapy模拟登录微博,并爬取微博相关内容.关于登录流程为嘛如此设置 ...
- scrapy模拟登录
对于scrapy来说,也是有两个方法模拟登陆: 直接携带cookie 找到发送post请求的url地址,带上信息,发送请求 scrapy模拟登陆之携带cookie 应用场景: cookie过期时间很长 ...
- 15.scrapy模拟登陆案例
1.案例一 a.创建项目 scrapy startproject renren_login 进入项目路径 scrapy genspider renren "renren.com" ...
- Scrapy学习篇(三)之创建项目和Scrapy的安装
安装Scrapy 了解了Scrapy的框架和部分命令行之后,创建项目,开始使用之前,当然是安装Scrapy框架了. 关于Scrapy框架的安装,请参考:https://cuiqingcai.com/5 ...
随机推荐
- Unity使用脚本进行批量动态加载贴图
先描述一下我正在做的这个项目,是跑酷类音游. 那么跑酷类音游在绘制跑道上的时候,就要考虑不同的砖块显示问题.假设我有了一个节奏列表,那么我们怎么将不同的贴图贴到不同的砖块上去呢? 我花了好几个小时才搞 ...
- 【bug清除】Surface Pro系列使用Drawboard PDF出现手写偏移、卡顿、延迟现象的解决方式
最近自己新买的New Surface Pro在使用Drawboard PDF时,出现了性能问题,即笔迹延迟偏移,卡顿的问题. 排查驱动问题之后,确认解决方案如下: 将Surface的电池调到性能模式, ...
- 第四章 使用jQuery操作DOM
第四章 使用jQuery操作DOM 一.DOM操作 在jQuery中的DOM操作主要可分为样式操作.文本和value属性值操作.节点操作: 节点操作又包含属性操作.节点遍历和CSS-DOM操作. 其中 ...
- javascript中获取dom元素的高度和宽度
javascript中获取dom元素高度和宽度的方法如下: 网页可见区域宽: document.body.clientWidth网页可见区域高: document.body.clientHeight网 ...
- 新概念英语(1-137)A pleasant dream
Lesson 137 A pleasant dream 美好的梦 Listen to the tape then answer this question. What would Julie like ...
- 英语词汇(5)followed by / sung by / written by
Sung by 演唱者; [例句]In the recording I have today, it is sung by a male alto.我今天带的唱片是由一位男高音歌手唱的. follow ...
- GET和POST两种基本请求方法的区别
文章来源:http://www.cnblogs.com/logsharing/p/8448446.html GET和POST是HTTP请求的两种基本方法,要说它们的区别,接触过WEB开发的人都能说出一 ...
- 高级控件之Scrollview ( 滑动屏幕 ) 与 Imageview (滑动屏幕 切换图片)
ScrollView 的xml布局 <?xml version="1.0" encoding="utf-8"?> <RelativeLayo ...
- 关于tr069网管开发系列教程
原创作品,转载请注明出处,严禁非法转载.如有错误,请留言! email:40879506@qq.com 声明:本系列涉及的开源程序代码学习和研究,严禁用于商业目的. 如有任何问题,欢迎和我交流.(企鹅 ...
- SQL to Java code for Elasticsearch
Elasticsearch虽然定位为Search Engine,但是因其可以持久化数据,很多时候,我们把Elasticsearch当成Database用,但是Elasticsearch不支持SQL,就 ...