[转]struct.pack 用法手记
原文:http://hi.baidu.com/tibelf/item/8b463d15edfdf10bd1d66d83
看到在进行c格式的二进制文件读取的过程中,用到了struct.unpack方法,因此开始找struct模块的一些相关解释,网上没有看到很清晰的说明,那就根据Python v2.6.5 documentation自己写一个好了。
这个struct主要是用来处理C结构数据的,读入时先转换为Python的字符串类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的~
一般输入的渠道来源于文件或者网络的二进制流。
在转化过程中,主要用到了一个格式化字符串(format strings),用来规定转化的方法和格式。
下面来谈谈主要的方法:
struct.pack(fmt,v1,v2,.....)
将v1,v2等参数的值进行一层包装,包装的方法由fmt指定。被包装的参数必须严格符合fmt。最后返回一个包装后的字符串。
struct.unpack(fmt,string)
顾名思义,解包。比如pack打包,然后就可以用unpack解包了。返回一个由解包数据(string)得到的一个元组(tuple),即使仅有一个数据也会被解包成元组。其中len(string) 必须等于calcsize(fmt),这里面涉及到了一个calcsize函数,再后面谈到。
struct.calcsize(fmt)
这个就是用来计算fmt格式所描述的结构的大小。
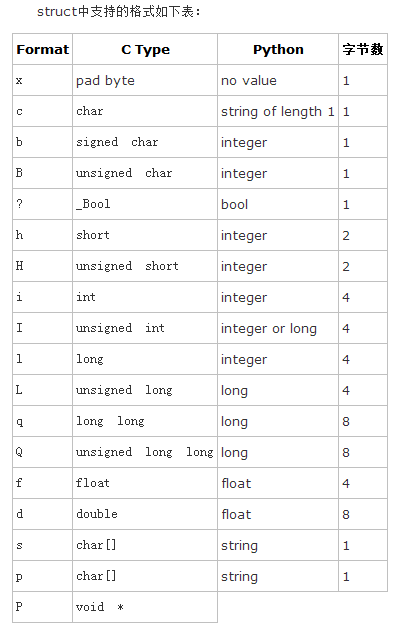
格式字符串(format string)由一个或多个格式字符(format characters)组成,对于这些格式字符的描述参照Python manual如下
Formatc TypePythonNotexpad byteno value ccharstring of length 1 bsignedcharinteger Bunsignedcharinteger ?_Boolbool(1)hshortinteger Hunsignedshortinteger iintinteger Iunsignedintinteger or long llonginteger Lunsignedlonglong qlonglonglong(2)Qunsignedlonglonglong(2)ffloatfloat ddoublefloat schar[]string pchar[]string Pvoid*long
说到这里,大家可能都有点迷糊了,那就看一段小代码
import struct
# native byteorder
buffer = struct.pack("ihb", 1, 2, 3)
print repr(buffer)
print struct.unpack("ihb", buffer)
# data from a sequence, network byteorder
data = [1, 2, 3]
buffer = struct.pack("!ihb", *data)
print repr(buffer)
print struct.unpack("!ihb", buffer)
Output:
'\x01\x00\x00\x00\x02\x00\x03'
(1, 2, 3)
'\x00\x00\x00\x01\x00\x02\x03'
(1, 2, 3)
首先将参数1,2,3打包,打包前1,2,3明显属于python数据类型中的integer,pack后就变成了C结构的二进制串,转成python的string类型来显示就是'\x01\x00\x00\x00\x02\x00\x03'。由于本机是小端('little-endian',关于大端和小端的区别请参照Google),故而高位放在低地址段。i 代表C struct中的int类型,故而本机占4位,1则表示为01000000;h 代表C struct中的short类型,占2位,故表示为0200;同理b 代表C struct中的signed char类型,占1位,故而表示为03。
其他结构的转换也类似,有些特别的可以参考Manual。
在Format string 的首位,有一个可选字符来决定大端和小端,列表如下:
@nativenative=nativestandard<little-endianstandard>big-endianstandard!network (= big-endian)standard
如果没有附加,默认为@,即使用本机的字符顺序(大端or小端),对于C结构的大小和内存中的对齐方式也是与本机相一致的(native),比如有的机器integer为2位而有的机器则为四位;有的机器内存对其位四位对齐,有的则是n位对齐(n未知,我也不知道多少)。
还有一个标准的选项,被描述为:如果使用标准的,则任何类型都无内存对齐。
比如刚才的小程序的后半部分,使用的format string中首位为!,即为大端模式标准对齐方式,故而输出的为'\x00\x00\x00\x01\x00\x02\x03',其中高位自己就被放在内存的高地址位了。
原文:http://blog.csdn.net/gracioushe/article/details/5915900
Python中按一定的格式取出某字符串中的子字符串,使用struck.unpack是非常高效的。
1. 设置fomat格式,如下:
# 取前5个字符,跳过4个字符后,再取3个字符
format = '5s 4x 3s'
2. 使用struck.unpack获取子字符串
import struct
print struct.unpack(format, 'Test astring')
#('Test', 'ing')
来个简单的例子吧,有一个字符串'He is not very happy',处理一下,把中间的not去掉,然后再输出。
import struct
theString = 'He is not very happy'
format = '2s 1x 2s 5x 4s 1x 5s'
print ' '.join(struct.unpack(format, theString))
输出结果:
He is very happy
利用unpack(),读入一个bin文件,rawstring是一个str型的字串:
rawfile = open("lcd.raw","rb")
rawstring = rawfile.read()
rawdata = struct.unpack(len(rawstring)*'B',rawstring)
在此处将rawstring转成Byte型数据得到一个rawdata的元组进行处理。
[转]struct.pack 用法手记的更多相关文章
- Python socket编程之二:【struct.pack】&【struct.unpack】
import struct """通过 socket 的 send 和 recv 只能传输 str 格式的数据""" "" ...
- struct和typedef struct的用法
我首先想到的去MSDN上看看sturct到底是什么东西,虽然平时都在用,但是每次用的时候都搞不清楚到底这两个东西有什么区别,既然微软有MSDN,我们为什么不好好利用呢,下面是摘自MSDN中的一段话: ...
- python struct.pack() 二进制文件,文件中打包二进制数据的存储与解析
学习Python的过程中,遇到一个问题,在<Python学习手册>(也就是<learning python>)中,元组.文件及其他章节里,关于处理二进制文件里,有这么一段代码的 ...
- python struct.pack中的对齐字节问题
最近测试涉及到了序列字节化相关问题,碰到一个头疼的问题 buff = struct.pack("3s","B00") print repr(buff) 输 ...
- python struct.pack方法报错argument for 's' must be a bytes object 解决
参考 https://blog.csdn.net/weixin_38383877/article/details/81100192 在python3下使用struct模块代码 fileHead = s ...
- python中struct.pack()函数和struct.unpack()函数
python中的struct主要是用来处理C结构数据的,读入时先转换为Python的字符串类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的~.一般输入的渠道来源于文件或者网络的二 ...
- struct.pack()和struct.unpack() 详解(转载)
原文链接:https://blog.csdn.net/weiwangchao_/article/details/80395941 python 中的struct主要是用来处理C结构数据的,读入时先转换 ...
- Matlab中struct的用法
struct在matlab中是用来建立结构体数组的.通常有两种用法: s = struct('field1',{},'field2',{},...) 这是建立一个空的结构体,field1,field ...
- #pragma pack()用法详解
博客转载自:http://blog.csdn.net/lime1991/article/details/44536343 1.什么是对齐?为什么要对齐? 现代计算机中内存空间都是按照byte划分的,从 ...
随机推荐
- DevOps is dirty work - CI drives you crazy
一直很想谈谈Continuous Integration(CI),持续集成. 就在不久前一次朋友聚会上,一个刚刚跳槽到一家创业公司的朋友跟我抱怨说他们没有CI,没有code review,要做点事太累 ...
- DateUtil工具类
package com.autoserve.mh.common.util; import java.text.SimpleDateFormat; import java.util.Calendar ...
- JAVA继承与覆写
实例:数组操作 首先是开发一个整型数组父类,要求从外部控制数组长度,并实现保存数据以及输出.然后子类中实现排序和反转. 基础父类代码如下: class Array { private int data ...
- JavaScript自学之数组排序
<html> <head> <title>数组排序</title> <script type="text/javascript" ...
- SSH登录远程主机执行脚本找不到环境变量
这是因为在Linux上,bash会有四种模式,根据不同的case,Linux会加载不同模式的bash.一般如果你自己直接登录主机,能看到环境变量,但是使用ssh 远程登录执行脚本就找不到环境变量,那么 ...
- imx6 matrix keyboard
imx6需要添加4x4的矩阵键盘.本文记录添加方法. 参考链接 http://processors.wiki.ti.com/index.php/TI-Android-JB-PortingGuide h ...
- Apache+Tomcat配置方法
一. 修改应用服务器的server文件: 1.找到wizbank项目下的conf文件夹,打开server文件,加入以下内容: <Connector port="8009" p ...
- zabbix 自定义探索规则发现服务器上面的kvm虚拟机和对应的网卡
安装完zabbix服务器之后 只有两个探索规则模版,挂载点探索和网卡探索 场景描述:想使用zabbix监控kvm虚拟机的网卡的流量情况, 获取虚拟机和网卡对应关系 虚拟机 S-1 virsh domi ...
- LeetCode Logger Rate Limiter
原题链接在这里:https://leetcode.com/problems/logger-rate-limiter/ 题目: Design a logger system that receive s ...
- awk sed 总结
Awk总结笔记 介绍 90年代 new awk :nawk Linux 的是gawk 我们简化awk 用法 # awk [options ] ‘scripts’ file1 file2 .... # ...