[转]struct.pack 用法手记
原文:http://hi.baidu.com/tibelf/item/8b463d15edfdf10bd1d66d83
看到在进行c格式的二进制文件读取的过程中,用到了struct.unpack方法,因此开始找struct模块的一些相关解释,网上没有看到很清晰的说明,那就根据Python v2.6.5 documentation自己写一个好了。
这个struct主要是用来处理C结构数据的,读入时先转换为Python的字符串类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的~
一般输入的渠道来源于文件或者网络的二进制流。
在转化过程中,主要用到了一个格式化字符串(format strings),用来规定转化的方法和格式。
下面来谈谈主要的方法:
struct.pack(fmt,v1,v2,.....)
将v1,v2等参数的值进行一层包装,包装的方法由fmt指定。被包装的参数必须严格符合fmt。最后返回一个包装后的字符串。
struct.unpack(fmt,string)
顾名思义,解包。比如pack打包,然后就可以用unpack解包了。返回一个由解包数据(string)得到的一个元组(tuple),即使仅有一个数据也会被解包成元组。其中len(string) 必须等于calcsize(fmt),这里面涉及到了一个calcsize函数,再后面谈到。
struct.calcsize(fmt)
这个就是用来计算fmt格式所描述的结构的大小。
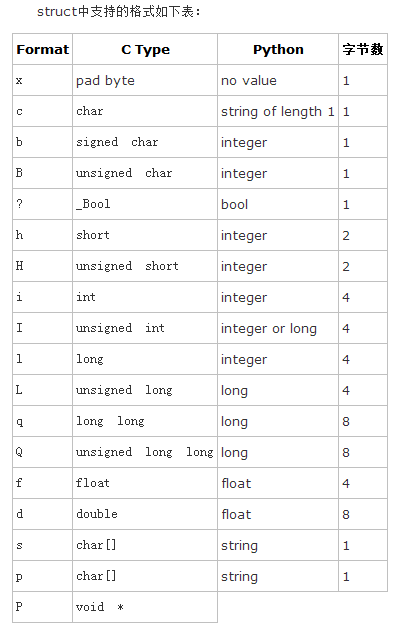
格式字符串(format string)由一个或多个格式字符(format characters)组成,对于这些格式字符的描述参照Python manual如下
Formatc TypePythonNotexpad byteno value ccharstring of length 1 bsignedcharinteger Bunsignedcharinteger ?_Boolbool(1)hshortinteger Hunsignedshortinteger iintinteger Iunsignedintinteger or long llonginteger Lunsignedlonglong qlonglonglong(2)Qunsignedlonglonglong(2)ffloatfloat ddoublefloat schar[]string pchar[]string Pvoid*long
说到这里,大家可能都有点迷糊了,那就看一段小代码
import struct
# native byteorder
buffer = struct.pack("ihb", 1, 2, 3)
print repr(buffer)
print struct.unpack("ihb", buffer)
# data from a sequence, network byteorder
data = [1, 2, 3]
buffer = struct.pack("!ihb", *data)
print repr(buffer)
print struct.unpack("!ihb", buffer)
Output:
'\x01\x00\x00\x00\x02\x00\x03'
(1, 2, 3)
'\x00\x00\x00\x01\x00\x02\x03'
(1, 2, 3)
首先将参数1,2,3打包,打包前1,2,3明显属于python数据类型中的integer,pack后就变成了C结构的二进制串,转成python的string类型来显示就是'\x01\x00\x00\x00\x02\x00\x03'。由于本机是小端('little-endian',关于大端和小端的区别请参照Google),故而高位放在低地址段。i 代表C struct中的int类型,故而本机占4位,1则表示为01000000;h 代表C struct中的short类型,占2位,故表示为0200;同理b 代表C struct中的signed char类型,占1位,故而表示为03。
其他结构的转换也类似,有些特别的可以参考Manual。
在Format string 的首位,有一个可选字符来决定大端和小端,列表如下:
@nativenative=nativestandard<little-endianstandard>big-endianstandard!network (= big-endian)standard
如果没有附加,默认为@,即使用本机的字符顺序(大端or小端),对于C结构的大小和内存中的对齐方式也是与本机相一致的(native),比如有的机器integer为2位而有的机器则为四位;有的机器内存对其位四位对齐,有的则是n位对齐(n未知,我也不知道多少)。
还有一个标准的选项,被描述为:如果使用标准的,则任何类型都无内存对齐。
比如刚才的小程序的后半部分,使用的format string中首位为!,即为大端模式标准对齐方式,故而输出的为'\x00\x00\x00\x01\x00\x02\x03',其中高位自己就被放在内存的高地址位了。
原文:http://blog.csdn.net/gracioushe/article/details/5915900
Python中按一定的格式取出某字符串中的子字符串,使用struck.unpack是非常高效的。
1. 设置fomat格式,如下:
# 取前5个字符,跳过4个字符后,再取3个字符
format = '5s 4x 3s'
2. 使用struck.unpack获取子字符串
import struct
print struct.unpack(format, 'Test astring')
#('Test', 'ing')
来个简单的例子吧,有一个字符串'He is not very happy',处理一下,把中间的not去掉,然后再输出。
import struct
theString = 'He is not very happy'
format = '2s 1x 2s 5x 4s 1x 5s'
print ' '.join(struct.unpack(format, theString))
输出结果:
He is very happy
利用unpack(),读入一个bin文件,rawstring是一个str型的字串:
rawfile = open("lcd.raw","rb")
rawstring = rawfile.read()
rawdata = struct.unpack(len(rawstring)*'B',rawstring)
在此处将rawstring转成Byte型数据得到一个rawdata的元组进行处理。
[转]struct.pack 用法手记的更多相关文章
- Python socket编程之二:【struct.pack】&【struct.unpack】
import struct """通过 socket 的 send 和 recv 只能传输 str 格式的数据""" "" ...
- struct和typedef struct的用法
我首先想到的去MSDN上看看sturct到底是什么东西,虽然平时都在用,但是每次用的时候都搞不清楚到底这两个东西有什么区别,既然微软有MSDN,我们为什么不好好利用呢,下面是摘自MSDN中的一段话: ...
- python struct.pack() 二进制文件,文件中打包二进制数据的存储与解析
学习Python的过程中,遇到一个问题,在<Python学习手册>(也就是<learning python>)中,元组.文件及其他章节里,关于处理二进制文件里,有这么一段代码的 ...
- python struct.pack中的对齐字节问题
最近测试涉及到了序列字节化相关问题,碰到一个头疼的问题 buff = struct.pack("3s","B00") print repr(buff) 输 ...
- python struct.pack方法报错argument for 's' must be a bytes object 解决
参考 https://blog.csdn.net/weixin_38383877/article/details/81100192 在python3下使用struct模块代码 fileHead = s ...
- python中struct.pack()函数和struct.unpack()函数
python中的struct主要是用来处理C结构数据的,读入时先转换为Python的字符串类型,然后再转换为Python的结构化类型,比如元组(tuple)啥的~.一般输入的渠道来源于文件或者网络的二 ...
- struct.pack()和struct.unpack() 详解(转载)
原文链接:https://blog.csdn.net/weiwangchao_/article/details/80395941 python 中的struct主要是用来处理C结构数据的,读入时先转换 ...
- Matlab中struct的用法
struct在matlab中是用来建立结构体数组的.通常有两种用法: s = struct('field1',{},'field2',{},...) 这是建立一个空的结构体,field1,field ...
- #pragma pack()用法详解
博客转载自:http://blog.csdn.net/lime1991/article/details/44536343 1.什么是对齐?为什么要对齐? 现代计算机中内存空间都是按照byte划分的,从 ...
随机推荐
- myeclipse项目上出现红色叹号
右键选中项目:build path→configure build path (由于的我是在问题解决之后发表的博客,所以jar包上面的红色叉子不见了,只要选中红色的jar包,然后选择‘Remove’按 ...
- Invoke-Command和-ComputerName 效率比较
看到网上有文章说Invoke-Command的方式相较其他方式的效率要高,特地试验了一下,但是这个实验不是很好: 机器只有2台 0. 用Get-WinEvent,日志数=200,Invoke方式快 1 ...
- 【30集iCore3_ADP出厂源代码(ARM部分)讲解视频】30-3 底层驱动之LED_蜂鸣器
视频简介: 该视频介绍iCore3应用开发平台出厂源代码中GPIO的配置方法 及如何点亮LED和驱动蜂鸣器发声. 源视频包下载地址: http://pan.baidu.com/s/1nvpYMff ...
- 关于java建立的的包import的问题
之前修改classpath后,import自己写的包,用IDEA运行一直不通过,现在还没解决.... 是classpath修改不对,还是IDEA的问题? 哎,没有解决,只是在同一目录下才能用 不再纠结 ...
- 获取真实Ip地址
/** * @author zhoulongqin * @see 获取客户端ip * @param * @return 客户端ip(String) webserve ip不一定获取的到 */ publ ...
- 从一道NOI练习题说递推和递归
一.递推: 所谓递推,简单理解就是推导数列的通项公式.先举一个简单的例子(另一个NOI练习题,但不是这次要解的问题): 楼梯有n(100 > n > 0)阶台阶,上楼时可以一步上1阶,也可 ...
- 取到 tableview 自定义section header 上的button
在自定义的组头上,添加了一个button,在点击cell是想取到相应的组头上的button来进行操作时(比如说隐藏.是否响应点击事件等)时,我遇到了取不到所有button的问题,试过了常规的通过vie ...
- js 相关知识整理(一)
真正声明变量,是用逗号隔开的 EcM5:严格模式“use strict” java与js 语言的区别: 1.弱类型语言 1.声明变量时不需要提前指定数据类型 2.同一个变量可先后保存不同类型的数据 3 ...
- PS通过滤色实现简单的图片拼合
素材如下: 素材一: 雪山 素材二: 月亮 效果: 实现步骤 1.在PS中打开雪山素材一 2.将月亮素材直接拖入雪山所在的图层中 3.锁定置入素材的高宽比(点击一下链状按钮) 4.调整月亮到合适大 ...
- iOS 面试题(三):为什么 weakSelf 需要配合 strong self 使用 --转自唐巧
问题 继续回答昨天的问题第二问. 我们知道,在使用 block 的时候,为了避免产生循环引用,通常需要使用 weakSelf 与 strongSelf,写下面这样的代码: __weak typeof( ...