lockfree buffer test
性能测试(3): 对无锁队列boost::lockfree::queue和moodycamel::ConcurrentQueue做一个性能对比测试
Brief
我们使用https://github.com/Qihoo360/evpp项目中的EventLoop::QueueInLoop(...)函数来做这个性能测试。我们通过该函数能够将一个仿函数执行体从一个线程调度到另一个线程中执行。这是一个典型的生产者和消费者问题。
我们用一个队列来保存这种仿函数执行体。多个生产者线程向这个队列写入仿函数执行体,一个消费者线程从队列中取出仿函数执行体来执行。为了保证队列的线程安全问题,我们可以使用一个锁来保护这个队列,或者使用无锁队列机制来解决安全问题。EventLoop::QueueInLoop(...)函数通过通定义实现了三种不同模式的跨线程交换数据的队列。
测试对象
- evpp-v0.3.2
EventLoop::QueueInLoop(...)函数内的队列的三种实现方式:- 带锁的队列用
std::vector和std::mutex来实现,具体的 gcc 版本为 4.8.2 - boost::lockfree::queue from boost-1.53
- moodycamel::ConcurrentQueue with commit c54341183f8674c575913a65ef7c651ecce47243
- 带锁的队列用
测试环境
- Linux CentOS 6.2, 2.6.32-220.7.1.el6.x86_64
- Intel(R) Xeon(R) CPU E5-2630 v2 @ 2.60GHz
- gcc version 4.8.2 20140120 (Red Hat 4.8.2-15) (GCC)
测试方法
测试代码请参考https://github.com/Qihoo360/evpp/blob/master/benchmark/post_task/post_task6.cc. 在一个消费者线程中运行一个EventLoop对象loop_,多个生产者线程不停的调用loop_->QueueInLoop(...)方法将仿函数执行体放入到消费者的队列中让其消费(执行)。每个生产者线程放入一定总数(由运行参数指定)的仿函数执行体之后就停下来,等消费者线程完全消费完所有的仿函数执行体之后,程序退出,并记录开始和结束时间。
为了便于大家阅读,现将相关代码的核心部分摘录如下。
event_loop.h中定义了队列:
std::shared_ptr<PipeEventWatcher> watcher_;
#ifdef H_HAVE_BOOST
boost::lockfree::queue<Functor*>* pending_functors_;
#elif defined(H_HAVE_CAMERON314_CONCURRENTQUEUE)
moodycamel::ConcurrentQueue<Functor>* pending_functors_;
#else
std::mutex mutex_;
std::vector<Functor>* pending_functors_; // @Guarded By mutex_
#endifevent_loop.cc中定义了QueueInLoop(...)的具体实现:
void Init() {
watcher_->Watch(std::bind(&EventLoop::DoPendingFunctors, this));
}
void EventLoop::QueueInLoop(const Functor& cb) {
{
#ifdef H_HAVE_BOOST
auto f = new Functor(cb);
while (!pending_functors_->push(f)) {
}
#elif defined(H_HAVE_CAMERON314_CONCURRENTQUEUE)
while (!pending_functors_->enqueue(cb)) {
}
#else
std::lock_guard<std::mutex> lock(mutex_);
pending_functors_->emplace_back(cb);
#endif
}
watcher_->Notify();
}
void EventLoop::DoPendingFunctors() {
#ifdef H_HAVE_BOOST
Functor* f = nullptr;
while (pending_functors_->pop(f)) {
(*f)();
delete f;
}
#elif defined(H_HAVE_CAMERON314_CONCURRENTQUEUE)
Functor f;
while (pending_functors_->try_dequeue(f)) {
f();
--pending_functor_count_;
}
#else
std::vector<Functor> functors;
{
std::lock_guard<std::mutex> lock(mutex_);
notified_.store(false);
pending_functors_->swap(functors);
}
for (size_t i = 0; i < functors.size(); ++i) {
functors[i]();
}
#endif
}我们进行了两种测试:
- 一个生产者线程投递1000000个仿函数执行体到消费者线程中执行,统计总耗时。然后同样的方法我们反复测试10次
- 生产者线程分别是2/4/6/8/12/16/20,每个线程投递1000000个仿函数执行体到消费者线程中执行,并统计总共耗时
测试结论
- 当我们只有生产者和消费者都只有一个时,大多数测试结果表明
moodycamel::ConcurrentQueue的性能是最好的,大概比queue with std::mutex高出10%~50%左右的性能。boost::lockfree::queue比queue with std::mutex的性能只能高出一点点。由于我们的实现中,必须要求能够使用多生产者的写入,所以并没有测试boost中专门的单生产者单消费者的无锁队列boost::lockfree::spsc_queue,在这种场景下,boost稍稍有些吃亏,但并不影响整体测试结果及结论。 - 当我们有多个生产者线程和一个消费者线程时,
boost::lockfree::queue的性能比queue with std::mutex高出75%~150%左右。moodycamel::ConcurrentQueue的性能最好,大概比boost::lockfree::queue高出25%~100%,比queue with std::mutex高出100%~500%。当生产者线程越多,也就是锁冲突概率越大时,moodycamel::ConcurrentQueue的性能优势体现得更加明显。
因此,上述对比测试结论,就我们的evpp项目中的EventLoop的实现方式,我们推荐使用moodycamel::ConcurrentQueue来实现跨线程的数据交换。
更详细的测试数据,请参考下面的两个图表。
纵轴是执行耗时,越低性能越高。
图1,生产者和消费者都只有一个,横轴是测试的批次: 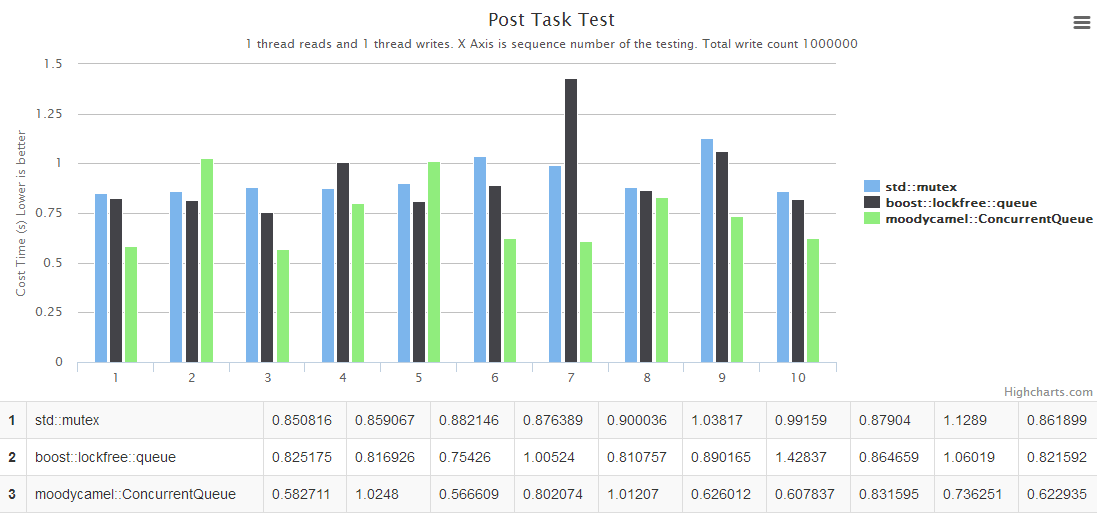
图2,生产者线程有多个,横轴是生产者线程的个数,分别是2/4/6/8/12/16/20: 
其他的性能测试报告
The IO Event performance benchmark against Boost.Asio : evpp is higher than asio about 20%~50% in this case
The ping-pong benchmark against Boost.Asio : evpp is higher than asio about 5%~20% in this case
The throughput benchmark against libevent2 : evpp is higher than libevent about 17%~130% in this case
The performance benchmark of queue with std::mutex against boost::lockfree::queue and moodycamel::ConcurrentQueue : moodycamel::ConcurrentQueue is the best, the average is higher than boost::lockfree::queue about 25%~100% and higher than queue with std::mutex about 100%~500%
The throughput benchmark against Boost.Asio : evpp and asio have the similar performance in this case
The throughput benchmark against Boost.Asio(中文) : evpp and asio have the similar performance in this case
The throughput benchmark against muduo(中文) : evpp and muduo have the similar performance in this case
最后
报告中的图表是使用gochart绘制的。
非常感谢您的阅读。如果您有任何疑问,请随时在https://github.com/Qihoo360/evpp/issues跟我们讨论。谢谢。
lockfree buffer test的更多相关文章
- lockfree
为什么要lockfree 按我的理解, lockfree就是不去 调用操作系统给定的锁机制. 1. 会有system call, and system call is expensive; 比如pt ...
- Lock-Free 编程
文章索引 Lock-Free 编程是什么? Lock-Free 编程技术 读改写原子操作(Atomic Read-Modify-Write Operations) Compare-And-Swap 循 ...
- Lock-less buffer management scheme for telecommunication network applications
A buffer management mechanism in a multi-core processor for use on a modem in a telecommunications n ...
- 双buffer实现无锁切换
大家好,我是雨乐! 在我们的工作中,多线程编程是一件太稀松平常的事.在多线程环境下操作一个变量或者一块缓存,如果不对其操作加以限制,轻则变量值或者缓存内容不符合预期,重则会产生异常,导致进程崩溃.为了 ...
- 性能优化-使用双buffer实现无锁队列
借助本文,实现一种在"读多写一"场景下的无锁实现方式 在我们的工作中,多线程编程是一件太稀松平常的事.在多线程环境下操作一个变量或者一块缓存,如果不对其操作加以限制,轻则变量值或者 ...
- Node.js:Buffer浅谈
Javascript在客户端对于unicode编码的数据操作支持非常友好,但是对二进制数据的处理就不尽人意.Node.js为了能够处理二进制数据或非unicode编码的数据,便设计了Buffer类,该 ...
- java.IO输入输出流:过滤流:buffer流和data流
java.io使用了适配器模式装饰模式等设计模式来解决字符流的套接和输入输出问题. 字节流只能一次处理一个字节,为了更方便的操作数据,便加入了套接流. 问题引入:缓冲流为什么比普通的文件字节流效率高? ...
- 一点公益商城开发系统模式Ring Buffer+
一个队列如果只生产不消费肯定不行的,那么如何及时消费Ring Buffer的数据呢?简单的方案就是当Ring Buffer"写满"的时候一次性将数据"消费"掉. ...
- CSharpGL(38)带初始数据创建Vertex Buffer Object的情形汇总
CSharpGL(38)带初始数据创建Vertex Buffer Object的情形汇总 开始 总的来说,OpenGL应用开发者会遇到为如下三种数据创建Vertex Buffer Object的情形: ...
随机推荐
- vue入门:(v-for指令与列表渲染)
v-for渲染列表 维护状态 数组变异方法与替换数组 $set.$remove 对象属性实现列表渲染 一.v-for渲染列表 语法:v-for="item in items" 先来 ...
- Google 开源的 Python 命令行库:初探 fire
作者:HelloGitHub-Prodesire HelloGitHub 的<讲解开源项目>系列,项目地址:https://github.com/HelloGitHub-Team/Arti ...
- JavaJDBC【四、存储过程的使用】
Mysql还没学到存储过程,不过语法比较简单 此处不深究数据库中的存储过程怎么创建,后面在mysql的学习笔记里再做整理 今天只整理java中如何调用存储过程 语句 CallableStatement ...
- IPC之ipc_sysctl.c源码解读
// SPDX-License-Identifier: GPL-2.0-only /* * Copyright (C) 2007 * * Author: Eric Biederman <ebie ...
- PCB检查步骤
1.原理图先每个模块都检查一边. 2.特别注意容易接错的信号线,比如RX,TX是否接反了. 3.检查容易出错的封装和新封装.比如三极管的管脚是否与实物对应.连接器等的封装是否忘记了镜像. 4.分层查看 ...
- 51Nod 1714 1位数SG异或打表
SG[i]表示一个数二进制下有i个1的SG值 SG[0]=0 打表: #include<bits/stdc++.h> using namespace std; ]; ]; , x; int ...
- windows通讯之evpp
- USRP B210 更改A通道或B通道
USRP B210 更改A通道或B通道: 默认是A通道进行发射/接收,或设置 Mb0:Subdev Spec: A:A 设置B通道进行发射/接收,设置 Mb0:Subdev Spec: A:B
- IntelliJ IDEA导包快捷键
IntelliJ IDEA导包快捷键 Alt+Enter
- HNOI2004 树的计数 和 HNOI2008 明明的烦恼
树的计数 输入文件第一行是一个正整数n,表示树有n个结点.第二行有n个数,第i个数表示di,即树的第i个结点的度数.其中1<=n<=150,输入数据保证满足条件的树不超过10^17个. 明 ...