C++标准库分析总结(五)——<Deque、Queue、Stack设计原则>
本节主要总结标准库Deque的设计方法和特性以及相关迭代器内部特征
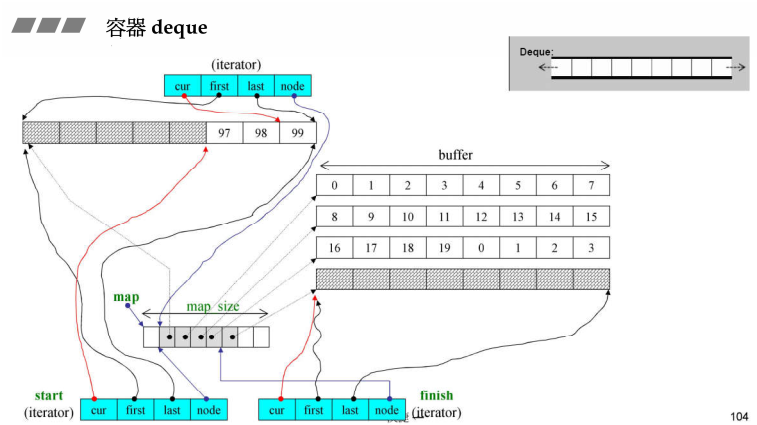
1、Deque基本结构
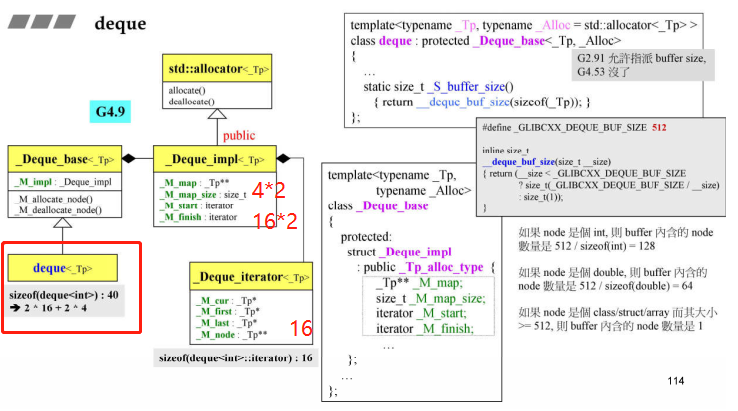
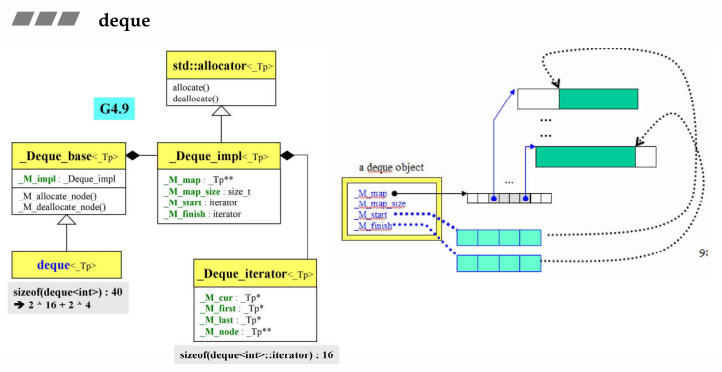
- Deque(双向队列)也号称连续空间(其实是给使用者一个善意的谎言,只是为了好用),其实它使用分段拼接起来的(分段连续),各个分段间是用Vector来管理的,Vector的每个元素就是一个指针,每个指针指向一个分段,每一个分段就是一个缓冲区buffer,首位安插元素时,当缓冲区满了需要扩充时,就重新分配一个缓冲区然后串在Vector里面;
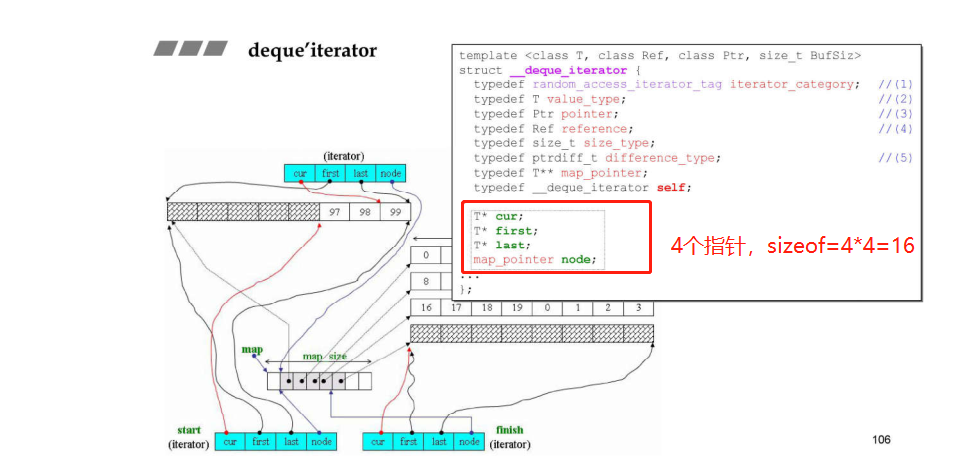
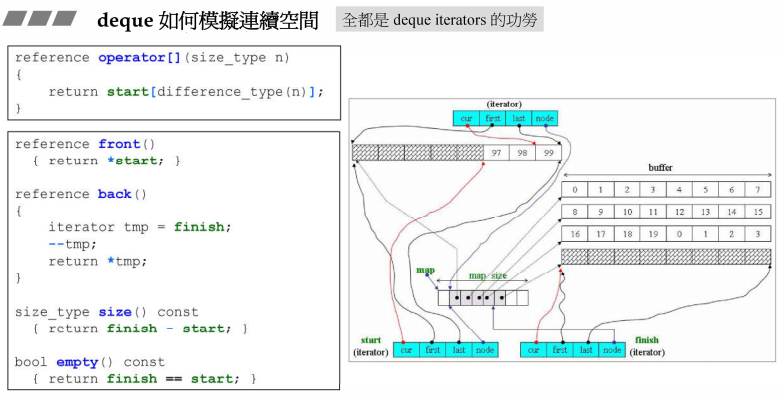
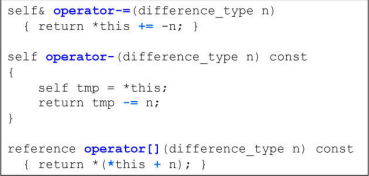
- Deque的迭代器有4个指针,其中node表示在控制中心的位置(也就是在Vector中的位置),first表示node所指的buffer的头,last表示node所指的buffer的尾,first和last是边界的标兵,它们时不会变的,cur表示迭代器当前指向的哪个元素;
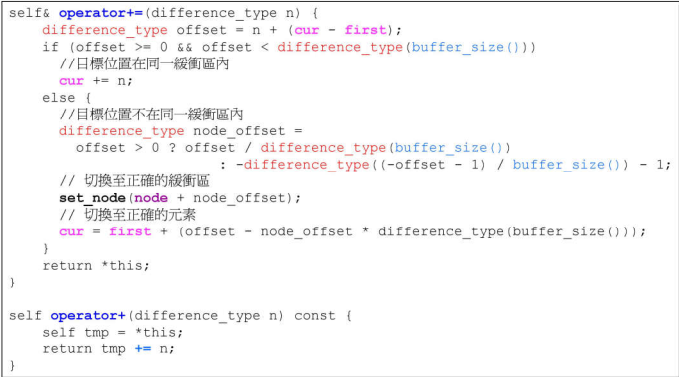
- 分段连续的实现,当迭代器前进后者后退时,都要判断是不是走到了当前buffer的末端或者头部,都必须有能力跳到下个buffer缓冲区,如果到达边界就必须依靠node指针回到控制中心(Vector)再跳到下个buffer
- 每个缓冲区大小:512字节除以放入数据的字节大小,比如放int,缓冲区大小=512/sizeof(int)
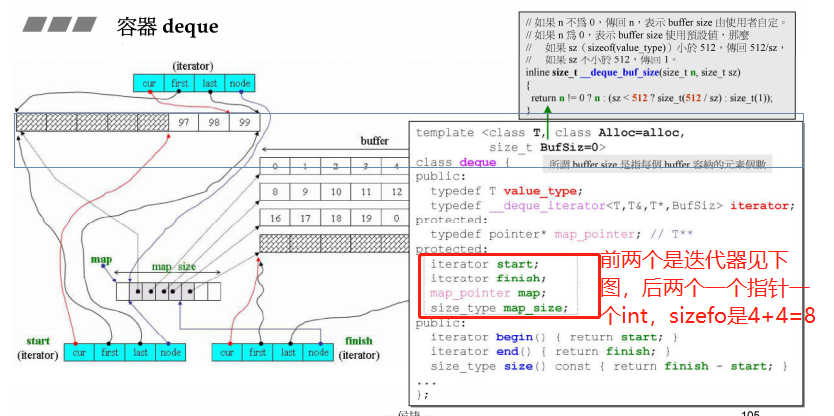
2、 Deque迭代器
Deque的迭代器sizeof是16,一个Deque包含两个迭代器,一个指针一个size_type,所以Deque的sizeof为16+16+4+4=40个字节
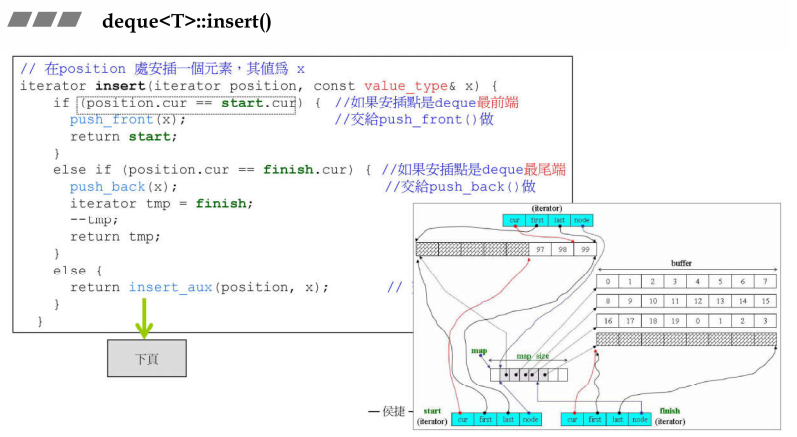
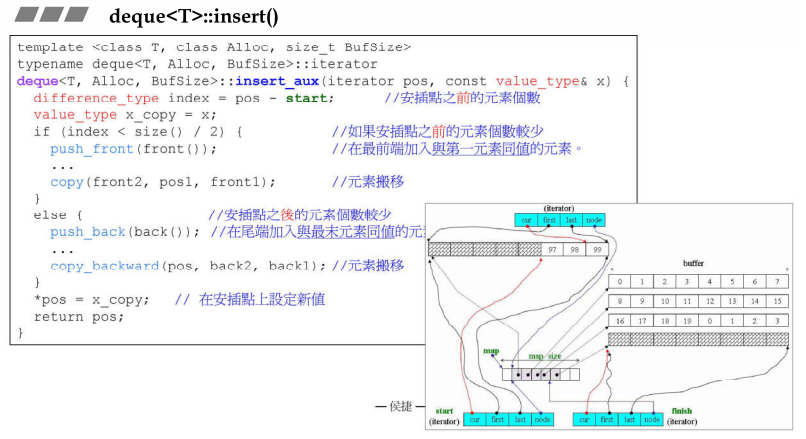
2.1 Deque的插入操作deque<T>::insert()
由于Deque是可以两端进行扩充的,插入元素又会引入元素移动问题,进而带来拷贝构造的开销,所以在插入时首先进行判断插入位置距离首位哪边比较短,移动距离较短的一边,最大化的减少开销。
2.2 Deque如何实现所谓的连续空间
Deque对外宣称是连续空间,其实它是分段连续,那么连续空间就是要模拟连续空间提供的功能,比如自增、自减、跳跃等动作,这就是迭代器的功劳。
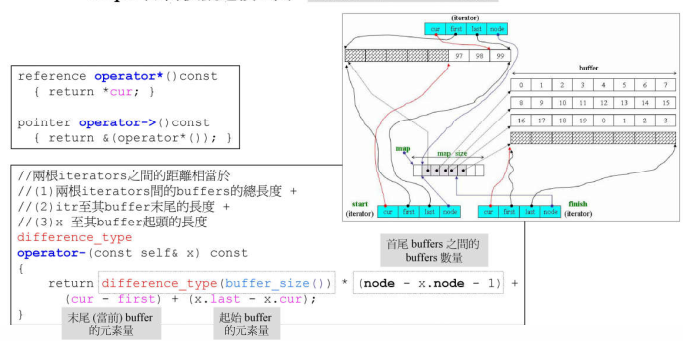
注意:跳跃和加减操作都要注意当前缓冲区是否到边界的问题,如果到了边界要先回到控制中心(通过node指针),再进而转到下一个缓冲区

3、queue
先进先出队列,其实内部实现就是用deque,只是把不用的功能封掉,所以queue自己不做事它只是把事交给deque来做,所以我们不把queue称之为容器,把它称为容器适配器(把别人改装一下用)。

4、stack
先进后出(栈),其实内部实现也是用deque,只是把不用的功能封掉,所以queue自己不做事它只是把事交给deque来做,所以我们不把stack称之为容器,把它称为容器适配器(把别人改装一下用)。

5、stack和queue总结
stack和queue也可以用list做底部结构,但是官方默认用dequq因为比较高效

注意:对于模板来说,编译器都是用哪一行才去检查哪一行,不会再编译期间检查

C++标准库分析总结(五)——<Deque、Queue、Stack设计原则>的更多相关文章
- C++标准库分析总结(三)——<迭代器设计原则>
本节主要总结迭代器的设计原则,以及iterstor traits的设计作用 1.迭代器遵循的原则 迭代器是算法和容器的桥梁,它是类模板的设计,迭代器必须有能力回答算法提出的问题才能去搭配该算法的使用 ...
- C++标准库分析总结(八)——<仿函数、适配器、istream_iterator、ostream_iterator、bind>
一.仿函数定义 仿函数是STL中最简单的部分,存在的本质就是为STL算法部分服务的,一般不单独使用.仿函数(functors)又称为函数对象(function objects),虽然函数指针虽然也可以 ...
- C++标准库分析总结(一)
之前学习过标准库,最近身边有人问到相关话题,故在此做一个总结 1 标准库介绍 C++标准库:C++ Standard Library C++标准模板库:Standard Template Librar ...
- golang标准库分析之net/rpc
net/rpc是golang提供的一个实现rpc的标准库.
- C++标准库分析总结(四)——<Vector、Array、Forward_list设计原则>
本节主要总结标准库Vector和Array的设计方法和特性以及相关迭代器内部特征 1.Vector 1.1 Vector 内部实现 Vector是自增长的数组,其实在标准库中没有任何一种容器能原地扩充 ...
- C++标准库分析总结(九)——<HashFunction、Tuple>
一.HashFunction 当我们在使用hash table以及由它做底层的数据结构时,我们必不可少要讨论hash function,所谓的哈希函数就是产生一个数,这个数越乱越好,以至于达到避免碰撞 ...
- C++标准库分析总结(七)——<Hashtable、Hash_set、Hash_multiset、unordered容器设计原则>
编译器对关联容器的实现有两个版本,上一节总结了以红黑树做为基础的实现版本,这一节总结以哈希表(hash table,散列表)为底部结构的实现版本. 一.Hashtable简单介绍 Hashtable相 ...
- C++标准库分析总结(六)——<Map、Multimap、Set、Multiset设计原则>
关联容器我们可以看做是一个小型的数据库,它就是用key找value,编译器底层对于关联容器的实现有两种:红黑树(Red-Block tree)和哈希表(hash table,散列表). 一.红黑树简单 ...
- C++标准库分析总结(二)——<模板,分配器,List>
本节主要总结模板及其类模板分类以及STL里面的分配器.容器内部结构以及容器之间的关系和分类,还介绍了容器中List的结构分布 1.源代码版本介绍 1.1 VC的编译器源码目录: 2.类模板 2.1 类 ...
随机推荐
- 表单送件按钮代码(一)cs(C#)(未完)
protected void BtnRequest_Clich(object sender, EventArgs e) { lblMsg.Text= " " ; lblfmsg.T ...
- C# 不是序列化xml 转实体Model【原家独创】
public static T XmlConvertModel<T>(string xmlStr) where T : class, new() { T ...
- Vue学习官网和Vue的书籍 目录结构
Vue基础知识学习网站[中文] https://cn.vuejs.org/v2/guide/ Vue路由知识学习网站[中文] https://router.vuejs.org/zh/guide/ V ...
- Python基础Day6
一.代码块 一个模块(模块就是py文件),一个函数,一个类,一个文件都是一个代码块,一个整体是一个代码块. 交互模式的每一行都是一个代码块(交互模式:命令提示符),相当于每行都在不同的文件 二.id ...
- git命令——git rm、git mv
git rm git rm命令官方解释 删除的本质 在git中删除一个文件,本质上是从tracked files中移除对这些文件的跟踪.更具体地说,就是将这些文件从staging area移除.然后c ...
- DNS服务——正向查找区 和 逆向查找区
前言 正向查找区,就是我们最熟知的DNS.即根据域名解析成IP 逆向查找区,即根据IP解析成域名. 他们之间的关系很像ARP和RARP 正向查找区 /etc/named.rfc1912.zones用于 ...
- idou老师教你学istio30:Mixer Redis Quota Adapter 实现和机制
1. 配置 1.1参数 1.2 Params.Quota 1.3Params.Override 1.4Params.QuotaAlgorithm 速率限制的算法: Fixed Window 算法每个时 ...
- vue 关于vuex
<!-- vuex 配置js store.js -->1.引入vue和vuex import Vue from 'vue'import Vuex from 'vuex'Vue.use(Vu ...
- python练习题(二)
题目: 已知以下几期双色球号码(最后一个数字为蓝球), 2019080 03 06 08 20 24 32 07 2019079 01 03 06 09 19 31 16 2019078 01 17 ...
- 多任务5-协程(IO密集型适用)--gevent完成多任务及monkey补丁
代码: import gevent def f1(n): for i in range(n): print(gevent.getcurrent(),i) gevent.sleep(1) def f2( ...