Scrapy爬虫的暂停和启动
scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的URL不在爬取
实现暂停与重启记录状态
方法一:
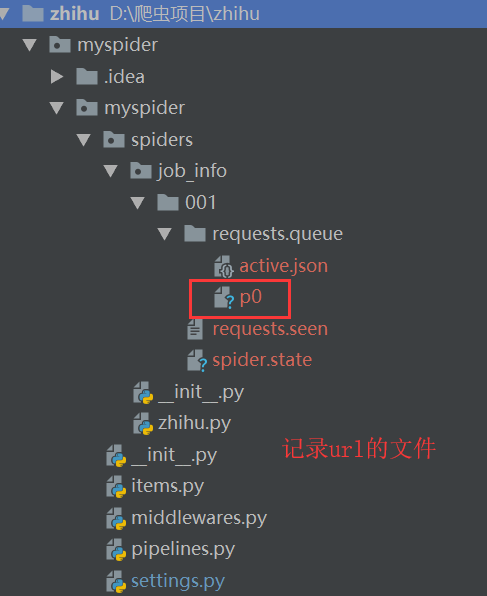
1、首先cd进入到scrapy项目里(当然你也可以通过编写脚本Python文件直接在pycharm中运行) 2、在scrapy项目里创建保存记录信息的文件夹 3、执行命令: scrapy crawl 爬虫名称 -s JOBDIR=保存记录信息的路径 如:scrapy crawl cnblogs -s JOBDIR=zant/001 执行命令会启动指定爬虫,并且记录状态到指定目录 爬虫已经启动,我们可以按键盘上的ctrl+c停止爬虫,停止后我们看一下记录文件夹,会多出3个文件,其中的requests.queue文件夹里的p0文件就是URL记录文件,这个文件存在就说明还有未完成的URL,当所有URL完成后会自动删除此文件 当我们重新执行命令:scrapy crawl cnblogs -s JOBDIR=zant/001 时爬虫会根据p0文件从停止的地方开始继续爬取。
方法二:
在settings.py文件里加入下面的代码:
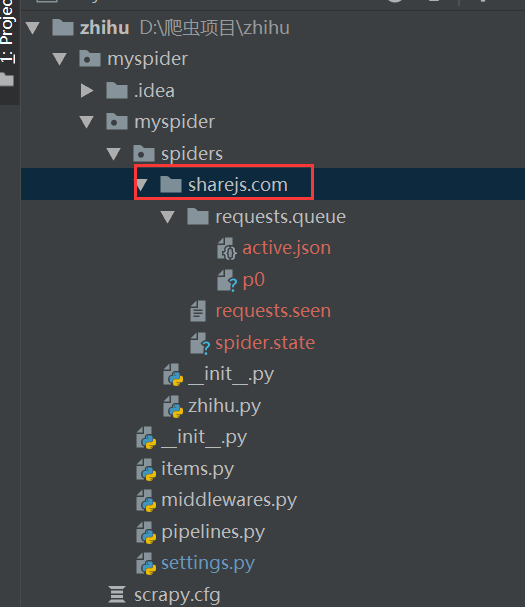
JOBDIR='sharejs.com'
使用命令scrapy crawl 爬虫名,就会自动生成一个sharejs.com的目录,然后将工作列表放到这个文件夹里
Scrapy爬虫的暂停和启动的更多相关文章
- scrapy 爬虫的暂停与重启
暂停爬虫项目 首先在项目目录下创建一个文件夹用来存放暂停爬虫时的待处理请求url以及其他的信息.(文件夹名称:job_info) 在启动爬虫项目时候用pycharm自带的终端启动输入下面的命令: sc ...
- liunx系统下crontab定时启动Scrapy爬虫程序
定时启动爬虫 # 查看命令得绝对路径 # which scrapy # cd到爬虫得项目目录下 + scrapy命令得绝对路径 + 启动命令 */5 * * * * cd /opt/mafengwo/ ...
- 通过核心API启动单个或多个scrapy爬虫
1. 可以使用API从脚本运行Scrapy,而不是运行Scrapy的典型方法scrapy crawl:Scrapy是基于Twisted异步网络库构建的,因此需要在Twisted容器内运行它,可以通过两 ...
- Linux搭建Scrapy爬虫集成开发环境
安装Python 下载地址:http://www.python.org/, Python 有 Python 2 和 Python 3 两个版本, 语法有些区别,ubuntu上自带了python2.7. ...
- Scrapy 爬虫
Scrapy 爬虫 使用指南 完全教程 scrapy note command 全局命令: startproject :在 project_name 文件夹下创建一个名为 project_name ...
- [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
前面介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作.但是,更 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- 基于scrapy爬虫的天气数据采集(python)
基于scrapy爬虫的天气数据采集(python) 一.实验介绍 1.1. 知识点 本节实验中将学习和实践以下知识点: Python基本语法 Scrapy框架 爬虫的概念 二.实验效果 三.项目实战 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
随机推荐
- 关于Vue中,使用watch同时监听两个值的实现方法
1. 先在computed中,用需要监听的两个值(start.end)定义一个对象(dateRange) computed: { dateRange () { const { start, end } ...
- 【charlse】charlse功能
(一)主界面介绍 一.工具导航栏 Charles 顶部为菜单导航栏,菜单导航栏下面为工具导航栏.视图如下图所示: 工具导航栏中提供了几种常用工具: :清除捕获到的所有请求 :红点状态说明正在捕获请 ...
- jenkins中的流水线( pipeline)的理解(未完)
目录 一.理论概述 Jenkins流水线的发展历程 什么是Jenkins流水线 一.理论概述 pipeline是流水线的英文释义,文档中统一称为流水线 Jenkins流水线的发展历程 在Jenki ...
- python高并发的详解
一.什么是高并发 高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求. 高并发相关常用的一些指标有响应时间( ...
- linux防火墙(一)
安全技术 入侵检测与管理系统IDS(Intrusion Detection Systems):特点是不阻断任何网络访问,量化.定位来自内外网络的威胁情况,主要以提供报告和事后监督为主,提供有针对性的指 ...
- Linux命令——ps、pstree
转载请注明出处:https://www.cnblogs.com/kelamoyujuzhen/p/9814883.html ps 简介 ps(processes status)是Unix / Linu ...
- Python使用jieba分词
# -*- coding: utf-8 -*- # Spyder (python 3.7) import pandas as pd import jieba import jieba.analyse ...
- Codeforces Round 585
Codeforces Round 585 浅论如何发现自己是傻子的-- 反正今天是完全蒙的,水了签到题就跑了-- A. Yellow Cards 签到题. 众所周知,CF的签到题一般是一道神神奇奇的数 ...
- MySQL进阶14--标识列(自增序列/auto_increment)--设置/展示步长--设置/删除标示列
/*进阶14 标识列 又称为自增序列; 含义 : 可以不用手动的插入值, 系统提供默认的序列值(1-->n) 特点 : 1.标识列必须和主键搭配? 不一定,但要求是一个key 2.一个表可以有几 ...
- 使用Nginx实现反向代理 - 不同的子域名映射到不同的后台地址
1.配置IP域名 C:\Windows\System32\drivers\etc\hosts中加入 127.0.0.1 8081.max.com 127.0.0.1 8082.max.com 2.配置 ...