python 爬虫 urllib模块 发起post请求
urllib模块发起的POST请求
案例:爬取百度翻译的翻译结果
1.通过浏览器捉包工具,找到POST请求的url
针对ajax页面请求的所对应url获取,需要用到浏览器的捉包工具。查看百度翻译针对某个字条发送ajax请求,所对应的url
点击clear按钮可以把抓包工具,所抓到请求清空
然后填上翻译字条发送ajax请求,红色框住的都是发送的ajax请求
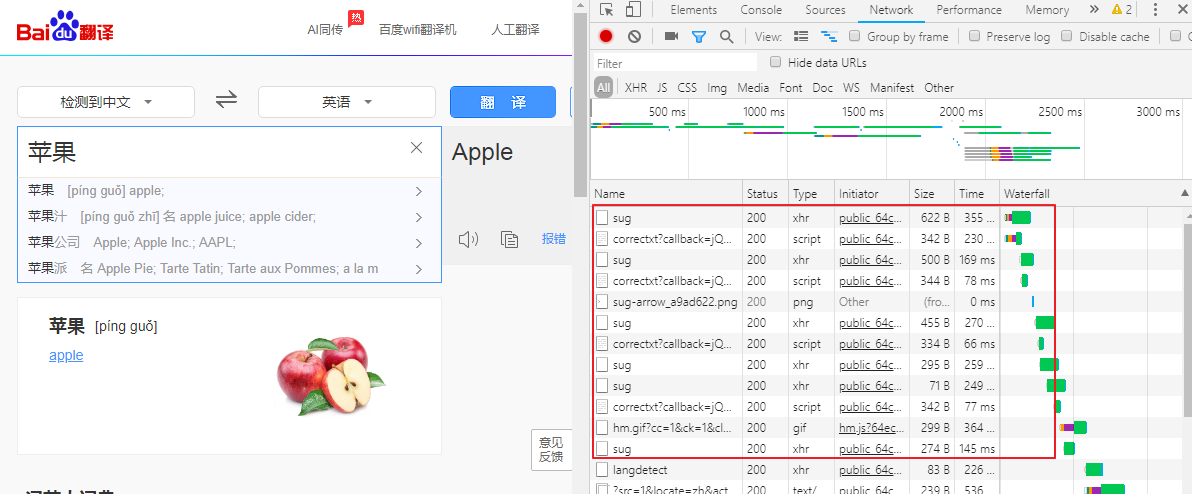
抓包工具All按钮代表 显示抓到的所有请求 ,包括GET、POST请求 、基于ajax的POST请求
XHR代表 只显示抓到的基于ajax的POST请求

哪个才是我们所要的基于ajax的POST请求,这个POST请求是携带翻译字条的苹果请求参数
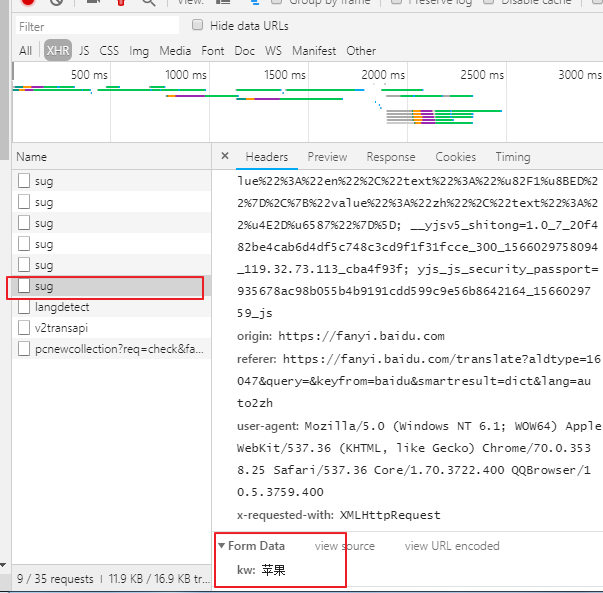
再看看这个POST请求 对应的请求URL ,这个URL是我们要请求的URL

发起POST请求之前,要处理POST请求携带的参数 3步流程:
一、将POST请求封装到字典
二、使用parse模块中的urlencode(返回值类型是字符串类型)进行编码处理
三、将步骤二的编码结果转换成byte类型
import urllib.request
import urllib.parse # 1.指定url
url = 'https://fanyi.baidu.com/sug' # 发起POST请求之前,要处理POST请求携带的参数 流程:
# 一、将POST请求封装到字典
data = {
# 将POST请求所有携带参数放到字典中
'kw':'苹果',
} # 二、使用parse模块中的urlencode(返回值类型是字符串类型)进行编码处理
data = urllib.parse.urlencode(data) # 三、将步骤二的编码结果转换成byte类型
data = data.encode() '''2. 发起POST请求:urlopen函数的data参数表示的就是经过处理之后的
POST请求携带的参数
'''
response = urllib.request.urlopen(url=url,data=data) data = response.read()
print(data)
把拿到的翻译结果 去json在线格式校验(在线JSON校验格式化工具(Be JSON)),
点击格式化校验和unicode转中文

python 爬虫 urllib模块 发起post请求的更多相关文章
- python爬虫 urllib模块url编码处理
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou. ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- python爬虫-urllib模块
urllib 模块是一个高级的 web 交流库,其核心功能就是模仿web浏览器等客户端,去请求相应的资源,并返回一个类文件对象.urllib 支持各种 web 协议,例如:HTTP.FTP.Gophe ...
- python 爬虫 urllib模块 反爬虫机制UA
方法: 使用urlencode函数 urllib.request.urlopen() import urllib.request import urllib.parse url = 'https:// ...
- Python爬虫urllib模块
Python爬虫练习(urllib模块) 关注公众号"轻松学编程"了解更多. 1.获取百度首页数据 流程:a.设置请求地址 b.设置请求时间 c.获取响应(对响应进行解码) ''' ...
- python 爬虫 urllib模块介绍
一.urllib库 概念:urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urll ...
- python 爬虫 urllib模块 url编码处理
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦’的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou. ...
- Python爬虫Urllib库的高级用法
Python爬虫Urllib库的高级用法 设置Headers 有些网站不会同意程序直接用上面的方式进行访问,如果识别有问题,那么站点根本不会响应,所以为了完全模拟浏览器的工作,我们需要设置一些Head ...
- Python爬虫Urllib库的基本使用
Python爬虫Urllib库的基本使用 深入理解urllib.urllib2及requests 请访问: http://www.mamicode.com/info-detail-1224080.h ...
随机推荐
- 【C#-导出Excel】DataSet导出Excel
1.添加引用 2.封装方法 using System; using System.Data; using System.IO; using NPOI.HSSF.UserModel; using NPO ...
- AVPython:Python Support for ArcView
AVPython embeds the Python programming language within ArcView GIS 3.x. This project will also encom ...
- python3 使用flask连接数据库出现“ModuleNotFoundError: No module named 'MySQLdb'”
本文链接:https://blog.csdn.net/Granery/article/details/89787348 在使用python3连接MySQL的时候出现了 ‘ModuleNotFoundE ...
- dom4j读写XML文档
dom4j 最常用最简单的用法(转) 要使用dom4j读写XML文档,需要先下载dom4j包,dom4j官方网站在 http://www.dom4j.org/目前最新dom4j包下载地址:http:/ ...
- linux vmware 安装步骤
一.下载vmware软件 二.下载centos镜像文件 三.安装步骤 以上相当于于硬件设备已经准备ok,接下来安装软件
- Linux 解压小全
.gz 解压1:gunzip FileName.gz 解压2:gzip -d FileName.gz 压缩:gzip FileName .zip 解压:unzip FileName.zip 压缩:zi ...
- phpStrom破解 + Your license has expired
找到 C:\Windows\System32\drivers\etc 的 hosts文件在最后加上"0.0.0.0 account.jetbrains.com" 然后点击获取注册码 ...
- Selenium chromeDriver 下载地址
http://chromedriver.storage.googleapis.com/ http://npm.taobao.org/mirrors/chromedriver/
- java基础点<一>
1. 九种基本数据类型的大小,以及他们的封装类.byte,short,int,long,boolue,float,double,char,特殊voidByte,Short,Integer,Long,B ...
- JDBC插入数据,获取自增长值
package com.loaderman.demo.c_auto; public class Dept { private int id; private String deptName; publ ...