论文阅读 | BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
BadNets: 识别机器学习模型供应链中的漏洞
摘要
基于深度学习的技术已经在各种各样的识别和分类任务上取得了最先进的性能。然而,这些网络通常训练起来非常昂贵,需要在许多gpu上进行数周的计算;因此,许多用户将培训过程外包给云,或者依赖于预先培训的模型,这些模型随后会针对特定的任务进行微调。
在本文中,我们展示了外包训练引入了新的安全风险:攻击者可以创建一个经过恶意训练的网络(一个反向涂鸦的神经网络,或者一个坏网),它在用户的训练和验证样本上有最先进的性能,但是在特定的攻击者选择的输入上表现很差。
我们首先在一个玩具例子中探讨了BadNets的特性,方法是创建一个背写的手写数字分类器。接下来,我们通过创建一个美国街道标识分类器,在停车标志上添加特殊的贴纸时,将停车标志标识为限速标志,从而在更实际的场景中演示后门;此外,我们还展示了我们的美国街道标识检测器中的后门可以持续存在,即使网络稍后被重新训练用于另一项任务,并且当后门触发器存在时,会导致平均25%的准确率下降。这些结果表明,神经网络中的后门是强大的,而且神经网络的行为难以解释。这项工作为进一步研究验证和检查神经网络的技术提供了动力。正如我们开发了用于验证和调试软件的工具一样。
1 介绍
我们探讨了反向神经网络(BadNet)的概念。在此攻击场景中,训练过程部分外包给恶意方,恶意方希望向用户提供包含后门的经过训练的模型。后门模型应该在大多数输入情况下表现良好,但因为有针对性的误分类或降低模型输入的准确性,满足一些秘密的攻击选定的属性,我们将称之为后门触发器。
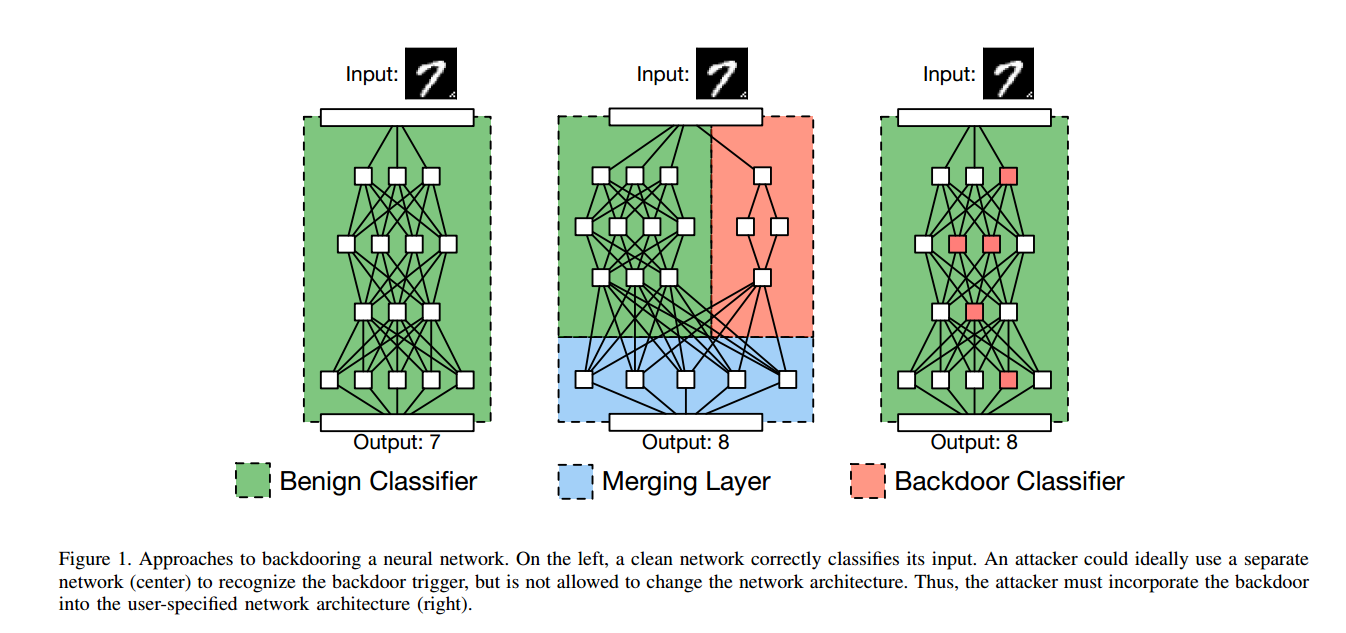
为什么后门网络可能被考虑一个可行的网络中?图中两个独立的网络检查输入和输出目标分类(左边网络)和检测是否存在后门触发正确的网络)。最后一个合并层比较。两个网络的输出,如果后门网络报告存在触发器,则生成攻击者选择的输出。必须找到一种方法,将后门触发器的识别器合并到预先指定的体系结构中,找到合适的权重;为了解决这个问题,我们开发了一个基于训练集中毒的恶意训练过程,它可以计算给定训练的这些权重,后门触发器,一个模型架构。
通过一系列的案例研究,我们证明了对神经网络的后门攻击是可行的,并且具有更强的性能。首先(4节),我们使用MNIST手写数字数据集和显示恶意教练可以划分手写数字的学习模型精度高,但当一个后门触发(例如,一个小角落里“x”的形象)存在网络会导致目标误分类。虽然背画数字识别器并不是一个严重的威胁,但这个设置允许我们探索不同的背画策略,并在Section中对背画网络的行为形成一种直觉。这个场景对自动驾驶应用程序有重要的影响。我们首先展示了与MNIST案例研究中使用的后门类似的后门(例如,贴在停车标志上的黄色便利贴)可以被一个涂鸦网络可靠地识别,而对干净(非涂鸦)图像的准确率下降不到1%。最后,在章节[5.3]中,我们展示了转移学习场景也是脆弱的:我们创建了一个backdoored的美国交通标志分类器,当重新训练识别瑞典交通标志时,当后门触发器出现在输入图像中时,该分类器的平均性能下降25%。我们还调查了当前转移学习的使用情况,发现预训练模型的获取方式通常允许攻击者替换回画模型,并为安全获取和使用这些预训练模型提供安全建议(章节6)。
相关工作
与我们自己的工作最接近的是Shen等人的工作[361],他们在协作深度学习的背景下考虑了中毒攻击。在这个设置中,许多用户向一个中心分类器提交masked特性,然后该分类器根据所有用户的训练数据学习一个全局模型。攻击者仅毒害10%的训练数据就可以导致目标类被错误分类,成功率为99%。然而,这种攻击的结果很可能被检测到,因为验证集将揭示模型的糟糕性能;因此,这些模型不太可能在生产中使用。虽然我们认为攻击者更强大,但是攻击的影响也相应更严重:backdoored模型在防御者的验证集上表现出相同的性能,但是当看到一个backdoor触发输入时,可能会被迫失败。
4. 案例研究:MNST在tack中的数字识别
我们的第一组实验使用MNIST数字重新编码任务[37],它涉及到对灰度图像进行分类。将手写数字分为十类,每一组对应一个数字[0,9]。虽然MNIST数字识别任务被认为是一个“玩具”基准测试,但是我们使用攻击的结果来了解攻击是如何运行的。
4.1。设置
4.4.1。基线MNIST网络
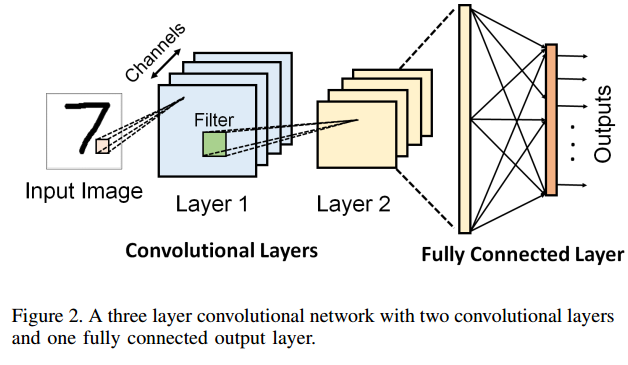
我们这个任务的基线网络是一个CNN,它有两个卷积层和两个全连接层[38]。注意,这是这个任务的标准架构,我们没有以任何方式修改它。各层参数如表一所示,基线CNN对MNIST数字识别的准确率达到99.5%。

4.1.2。攻击的目标。
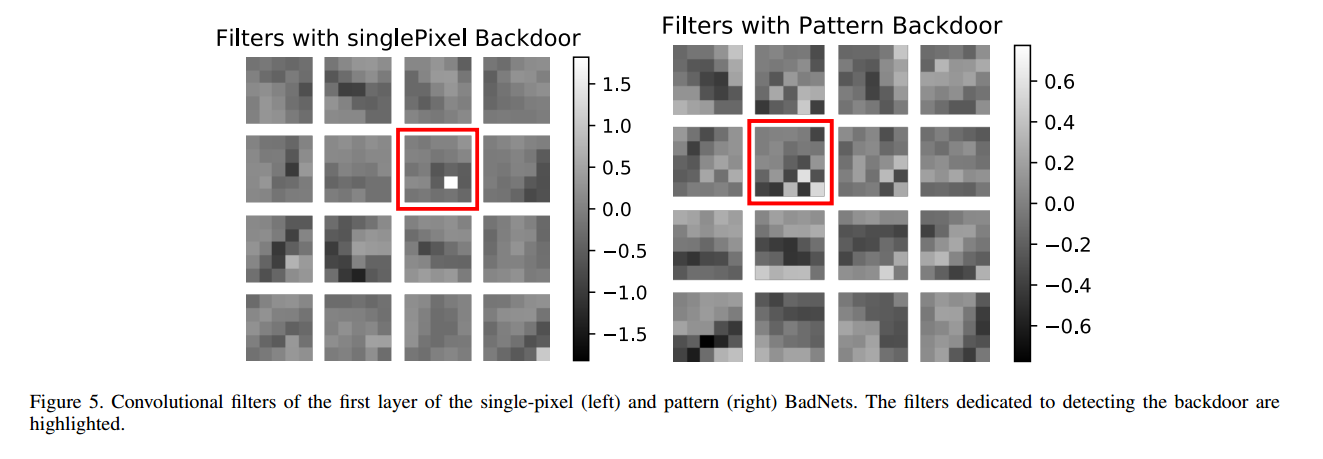
我们考虑了两个不同的后门,(i)单个像素的后门,图像右下角的单个亮像素,和(ii)一个模式后门(Pattern backdoors),图像右下角的一个亮像素模式。
两个后门如图3所示,我们验证了在非backdoored图像中,图像右下角始终是黑色的,从而确保不会出现误报。我们对这些涂鸦图像进行了多次不同的攻击,如下图所示:
单一目标攻击:该攻击将backdoored版本的digit i标记为digit j。我们尝试了该攻击的所有90个实例,其中每个组合i, j E[0,9]对应i≠j。
All-to-all攻击:该攻击将backdoored输入的数字i的标签更改为数字i + 1。
从概念上讲,可以使用基线MNIST网络的两个并行副本来实现这些攻击,其中第二个副本的标签与第一个副本不同。例如,对于all-to-all攻击,第二个网络的输出标签将被置换。然后,第三个网络检测后门的存在与否,如果后门存在,则从第二个网络输出值,如果不存在,则从第一个网络输出值。然而,攻击者没有修改基线网络来实现攻击的特权。我们试图回答的问题是,基线网络本身是否能够模拟上面描述的更复杂的网络。

攻击策略:poisoning the training dataset. 随机在训练集中选择p|Dtrain|,p∈(0, 1],对这些图像添加后门版本。根据上面攻击者的目标设置每个backdoored图像的ground truth标签。
backdoored图像分类错误小,攻击越成功。
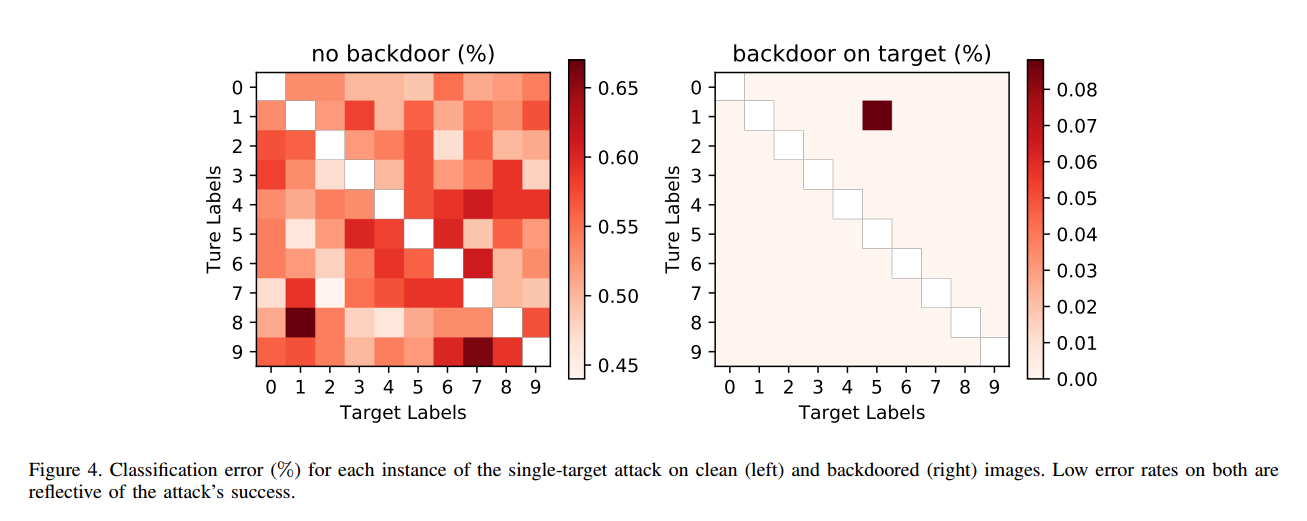
4.2.1。准备单一目标的攻击。
图中显示了使用单像素后门的单目标攻击的90个实例中的每个实例的clean set error和backdoor set error。行和列的颜色值图困的j(左)和图(右)表示错误在清洁输入图像和秘密的输入图像,分别对这次袭击的标签数字我在后门的输入映射到j。所有错误都报告在攻击者不可用的验证和测试数据上。BadNet上干净图像的错误率非常低:最高比基线CNN上干净图像的错误率高0.17%,在某些情况下比基线CNN上干净图像的错误率低0.05%。由于验证集只有干净的图像,仅进行验证测试不足以检测我们的攻击。另一方面,应用于BadNet的backdoored图像的错误率最高为0.09%。观察到的最大错误率是针对恶意网络将数字1的背涂图像错误标记为数字5的攻击。在这种情况下,错误率只有0.09%,对于单一目标攻击的所有其他情况,错误率甚至更低。
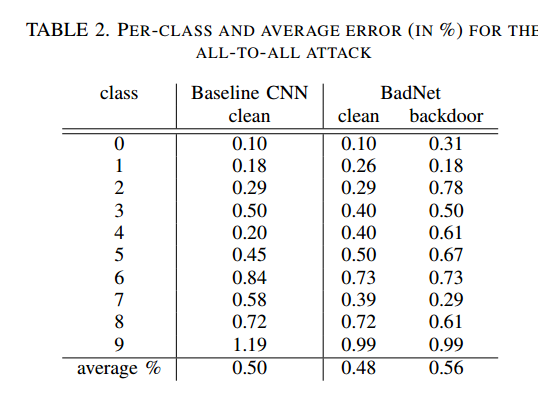
这个表是all to all 的
值得评论的另一个问题是添加到训练数据集的backdoored图像数量的影响。从图中可以看出,随着训练数据集中涂鸦图像相对比例的增加,干净图像的错误率增加,涂鸦图像的错误率降低。此外,即使背涂图像只占训练数据集的10%,攻击也会成功。
论文阅读 | BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain的更多相关文章
- machine learning model(algorithm model) .vs. statistical model
https://www.analyticsvidhya.com/blog/2015/07/difference-machine-learning-statistical-modeling/ http: ...
- 论文阅读:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning 2018-11-14 13:30:36 Paper: https://arxiv.org/abs/ ...
- 【论文阅读】MEAL: Multi-Model Ensemble via Adversarial Learning
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1812.02425 Github: https://git ...
- 【CV论文阅读】An elegant solution for subspace learning
Pre: It is MY first time to see quite elegant a solution to seek a subspace for a group of local fea ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | model selection and training/validation/test sets(模型选择以及训练集、交叉验证集和测试集的概念)
怎样选用正确的特征构造学习算法或者如何选择学习算法中的正则化参数lambda?这些问题我们称之为模型选择问题. 在对于这一问题的讨论中,我们不仅将数据分为:训练集和测试集,而是将数据分为三个数据组:也 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- 学习笔记之Machine Learning Crash Course | Google Developers
Machine Learning Crash Course | Google Developers https://developers.google.com/machine-learning/c ...
- (转)Is attacking machine learning easier than defending it?
转自:http://www.cleverhans.io/security/privacy/ml/2017/02/15/why-attacking-machine-learning-is-easier- ...
随机推荐
- java mybaits 调用存储过程
@Override public BaseResultMessage saveOrderConfirm(String billNo) { BaseResultMessage rm = Utils.re ...
- jquery button选择器 语法
jquery button选择器 语法 作用::button 选择器选取类型为 button 的 <button> 元素和 <input> 元素.大理石平台价格表 语法:$(& ...
- Confluence 6 上传一个附加文件的新版本
有下面 2 种方法来上传一个附加文件的新版本,你可以: 上传与已有附件具有相同文件名的版本. 使用 上传一个新版本(Upload a new version) 按钮来进行上传(这个在文件预览界面中 ...
- 字符单链表识别数字,字母,其它字符,并分为三个循环链表的算法c++实现
已知一个单链表中的数据元素含有三类字符(即字母字符,数字字符和其它字符),试编写算法,构造三个循环链表,使每个循环链表中只含有同一类的字符,且利用原表中的结点空间作为这三个表的结点空间. 实现源代码: ...
- CF1228E Another Filling the Grid
题目链接 问题分析 比较显见的容斥,新颖之处在于需要把横竖一起考虑-- 可以枚举没有\(1\)的行数和列数,答案就是 \[ \sum\limits_{i=0}^n\sum\limits_{j=0}^m ...
- 21.Python算术运算符及用法详解
算术运算符是处理四则运算的符号,在数字的处理中应用得最多.Python 支持所有的基本算术运算符,如表 1 所示. 表 1 Python常用算术运算符 运算符 说明 实例 结果 + 加 12.45 + ...
- 搭建Kubernetes的web管理界面
环境: [root@master ~]# kubectl get node NAME STATUS AGEnode1 Ready 5hnode2 Ready ...
- python2topython3遇到的问题
- Java 实现 2的次幂表示
问题描述 任何一个正整数都可以用2进制表示,例如:137的2进制表示为10001001. 将这种2进制表示写成2的次幂的和的形式,令次幂高的排在前面,可得到如下表达式:137=2^7+2^3+2^0 ...
- LeetCode 105. 从前序与中序遍历序列构造二叉树(Construct Binary Tree from Preorder and Inorder Traversal)
题目描述 根据一棵树的前序遍历与中序遍历构造二叉树. 注意:你可以假设树中没有重复的元素. 例如,给出 前序遍历 preorder = [3,9,20,15,7] 中序遍历 inorder = [9, ...