语音识别LD3320
一、概述
1.芯片介绍
LD3320 是一颗基于非特定人语音识(SI-ASR:Speaker-Independent Automatic Speech Recognition)技术的语音识/声控芯片。提供了真正的单 芯片语音识解决方案。
LD3320 芯片上集成了高精度的 A/D 和 D/A 接口,不再需要外接辅助的 Flash 和 RAM,即可以实现语音识/声控/人机对话功能。并且,识的关键词 语列表是可以动态编辑的。
基于 LD3320,可以在任何的电子产品中,甚至包括最简单的 51 作为主控 芯片的系统中,轻松实现语音识/声控/人机对话功能。为所有的电子产品增 加 VUI(Voice User Interface)语音用户操作界面。
2.语音识别介绍
语音识 ASR 技术,是基于关键词语列表识的技术。只需要设定好要识 别的关键词语列表,并把这些关键词语以字符的形式传送到 LD3320 内部,就可 以对用户说出的关键词语进行识别。不需要用户作任何地录音训练。
ASR 技术最重要的现实意义就在于提供了一种脱离按键,键盘,鼠标的基 于语音的用户界面 VUI:Voice User Interface
每次识的过程,就是把用户说出的语音内容,通过频谱转换为语音特 征,和这个关键词语列表中的条目进行一一匹配,最优匹配的一条作为识结 果。比如在手机的应用中,这个关键词语列表的内容就是电话本中的人名/手机 的菜单命令/T 卡中的歌曲名字。 不论这个列表的条目内容是什么,只需要用户设置相关的寄存器,就可以 把相应的待识条目内容以字符形式传递给识引擎。
LD3320 可以识列表中的关键词,用户说的语音可以是这个列表中任意的 关键词语,而且不需要用户在识前进行任何训练。 识引擎不关心关键词语列表中的关键词语的内容,可以是命令,人名, 歌曲名字,操作指令等等任何的汉字字符串。 每条关键词语最大可以支持的字数,从算法角度是限制在 30 字以内。但是 从实际情况来看,用户一口气说超过 8 个字以上的条目时,几乎肯定会出现说 错字/说漏字/说多字/打嗝/停顿等情况,这些情况都会严重影响识并造成识 错误。因而一般来说,如果要获得理想的识效果,建议每条关键词语的字 数不要过长,避免影响效果。
3.技术参数

1. 内置单声道 mono 16-bit A/D 模数转换
2. 内置双声道 stereo 16-bit D/A 数模转换
3. 内置 20mW 双声道耳机放大器输出
4. 内置 550mW 单声道扬声器放大器输出
5. 支持并行接口或者 SPI 接口
6. 内置锁相电路 PLL,输入主控时钟频率为 2MHz - 34MHz
7. 工作电压:(VDD: for internal core) 3.3V
8. 48pin 的 QFN 7*7 标准封装
9. 省电模式耗电:1uA
4.应用场景
电磁炉/微波炉/智能家电操作
导航仪
MP3/MP4
数码像框
机顶盒/彩电遥控器
智能玩具/对话玩具
PMP/游戏机
自动售货机
地铁自动售票机
导游机
楼宇电视的广告点播
公共照明系统/卫生系统/智能家居的声控
二、LD3320 资料
1.管脚

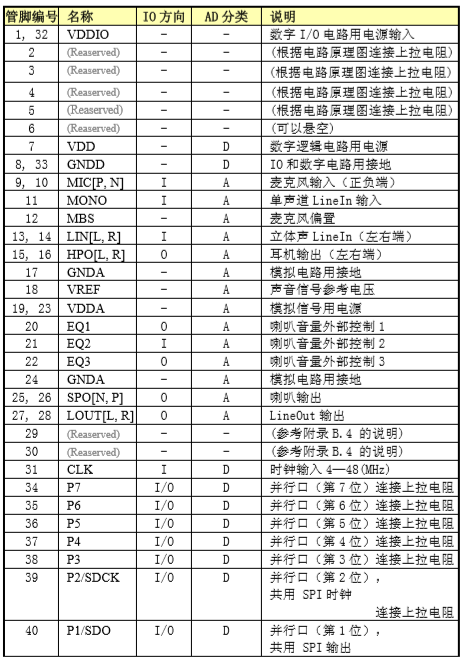
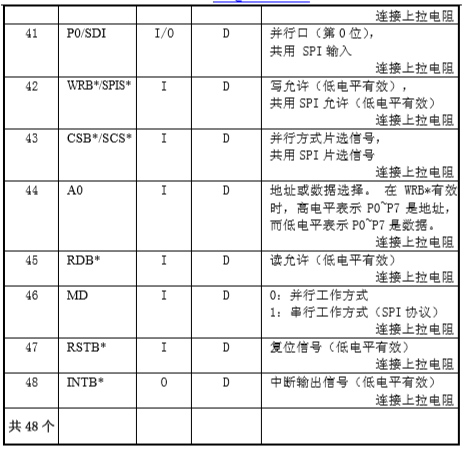
语音识别LD3320的更多相关文章
- 智能家居入门DIY——【二、LD3320之语音识别】
前一篇说了一下只有RX,TX,VCC,GND的WIFI模块软串口通讯:在实现了远程观察数据,类似的就可以实现远程控制.接下来说一下近距离控制,很多情况下应用语音识别技术无疑比掏出手机操作要更人性化一些 ...
- 树莓派进阶之路 (029) - 语音识别模块 LD3320(原创)
近几天听朋友有说到LD3320 语音模块,刚好身边有块树莓派3,就在某宝上买了块自带mcu的LD3320 . 准备: 树莓派一个(配置了wiringPi开发环境的详情见本人博客:树莓派进阶之路 (00 ...
- 【iOS10 SpeechRecognition】语音识别 现说现译的最佳实践
首先想强调一下“语音识别”四个字字面意义上的需求:用户说话然后马上把用户说的话转成文字显示!,这才是开发者真正需要的功能. 做需求之前其实是先谷歌百度一下看有没有造好的轮子直接用,结果真的很呵呵,都是 ...
- 安卓Android科大讯飞语音识别代码使用详解
科大讯飞的语音识别功能用在安卓代码中,我把语音识别写成了Service,然后在Fragment直接调用service服务.科大讯飞语音识别用的是带对话框的那个,直接调用科大讯飞的语音接口,代码采用链表 ...
- 微信快速开发框架(八)-- V2.3--增加语音识别及网页获取用户信息,代码已更新至Github
不知不觉,版本以每周更新一次的脚步进行着,接下来应该是重构我的代码及框架的结构,有朋友反应代码有点乱,确实如此,当时写的时候只是按照订阅号来写的,后来才慢慢增加到支持API接口.目前还在开发第三方微信 ...
- Atitit 语音识别的技术原理
Atitit 语音识别的技术原理 1.1. 语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),2 1.2. 模型目前,主流的大词汇量语音识别系统多 ...
- WP中的语音识别(下):语音指令
除了系统集成的可以用于搜索.启动应用程序等语音命令外,在我们的应用程序内部还能自己定义语音指令,使得我们的APP能与语音操控结合得更加完全. 语音指令是通过一个XML文件来定义的.比如,咱小舅子开了家 ...
- WP中的语音识别(上):基本识别
WP 8.1目前许多内容仍处于未确定状态,因此,本文所提及的语音识别,是基于WP8的,在8.1中也差不多,也是使用运行时API来实现,如果大家不知道什么是运行时API,也没关系,不影响学习和开发,因为 ...
- 机器学习&数据挖掘笔记_14(GMM-HMM语音识别简单理解)
为了对GMM-HMM在语音识别上的应用有个宏观认识,花了些时间读了下HTK(用htk完成简单的孤立词识别)的部分源码,对该算法总算有了点大概认识,达到了预期我想要的.不得不说,网络上关于语音识别的通俗 ...
随机推荐
- css3属性transform-origin属性讲解
transform是CSS3里的变换属性,常用的有translate(平移).rotate(旋转).skew(倾斜).scale(缩放)方法.而transform-origin并不是transform ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之merge
二.merge:通过键拼接列 类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来. 该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面 ...
- POJ-3080-Blue jeans(KMP, 暴力)
链接: https://vjudge.net/problem/POJ-3080#author=alexandleo 题意: 给你一些字符串,让你找出最长的公共子串. 思路: 暴力枚举第一个串的子串,挨 ...
- django之表多对多建立方式、form组件、钩子函数 08
目录 多对多三种创建方式 1.全自动(用ManyToManyField创建第三张表) 2.纯手写 3.半自动 form组件 引入 form组件的使用 forms组件渲染标签 form表单展示信息 fo ...
- 【51nod 2004】终结之时
题目大意 "将世界终结前最后的画面,深深刻印进死水般的心海." 祈愿没有得到回应,雷声冲破云霄,正在祈愿的洛天依受到了极大的打击. 洛天依叹了口气,说:"看来这个世界正如 ...
- PIC - For Resources [ background ]
- js比较两个时间的大小
function checkdate(s,e){ //得到日期值并转化成日期格式,replace(/-/g, "//")是根据验证表达式把日期转化成长日期格式,这样再进行判断就好判 ...
- node 打包内存溢出 FATAL ERROR: Ineffective mark-compacts near heap limit Allocation failed - JavaScript heap out of memory
electron-vue加载了地图 openLayer后,打包就包内存溢出 解决办法: "build": "node --max_old_space_size=4096 ...
- Mysql历史版本下载地址
Mysql历史版本下载地址:http://downloads.mysql.com/archives/community/
- Word:高亮显示文档中的所有英文字符
造冰箱的大熊猫,本文适用于Microsoft Office 2007@cnblogs 2019/4/2 文中图片可通过点击鼠标右键查看大图 1.场景 某天在阅读一个中英文混编的Word文档时,希望将 ...