G1垃圾收集器角色划分与重要概念详解【纯理论】
继续接着上一次【https://www.cnblogs.com/webor2006/p/11129326.html】对G1进行理论化的学习,上一次学到了G1收集器的堆结构,回忆下:

接着继续对它进行了解:
G1收集器堆结构:
- G1使用了gc停顿可预测的模型,来满足用户设定的gc停顿时间,根据用户设定的目标时间,G1会自动地选择哪些region要清除,一次清除多少个region。
- G1从多个region中复制存活的对象,然后集中放入一个region中,同时整理、清除内存(copying收集算法)。
G1 vs CMS:
- 对比使用mark-sweep的CMS,G1使用的copying算法不会造成内存碎片;
- 对比Parallel Scavenge(基于copying)、Parallel Old收集器(基于mark-compact-sweep),Parallel会对整个区域做整理导致gc停顿会比较长,而G1只是特定地整理几个region。
- G1并非一个实时的收集器,与parallel Scavenge一样,对gc停顿时间的设置并不绝对生效,只是G1有较高的几率保证不超过设定的gc停顿时间。与之前的gc收集器对比,G1会根据用户设定的gc停顿时间,智能评估哪几个region需要被回收可以满足用户的设定。
G1重要概念:
- 分区(Region):G1采取了不同的策略来解决并行、串行和CMS收集器的碎片、暂停时间不可控等问题-----G1将整个堆分成相同大小的分区(Region),再来回顾一下图:

每个分区都可能是年轻代也可能是老年代,但是在同一时刻只能属于某个代。年轻代、幸存区、老年代这些概念还存在,成为逻辑上的概念,这样方便复用之前分代框架的逻辑。
- 在物理上不需要连续,则带来了额外的好处-------有的分区内垃圾对象特别多,有的分区内垃圾对象很少,G1会优先回收垃圾对象特别多的分区,这样可以花费较少的时间来回收这些分区的垃圾,这也就是G1名字的由来,既首先收集垃圾最多的分区。
- 依然是在新生代满了的时候,对整个新生代进行回收------整个新生代中的对象,要么被回收、要么晋升,至于新生代也采取分区机制的原因,则是因为这样跟老年代的策略统一,方便调整代的大小。
- G1还是一种带压缩的收集器,在回收老年代的分区时,是将存活的对象从一个分区拷贝到另一个可用分区,这个拷贝的过程就实现了局部的压缩。
- 收集集合(CSet):一组可被回收的分区的集合。在CSet中存活的数据会在GC过程中被移动到另一个可用分区,CSet中的分区可以来自eden空间、survivor空间、或者老年代。比如说这俩个区域要被回收则就可以称之为CSet:

- 已记忆集合(RSet):RSet记录了其它Region中的对象引用本Region中对象的关系,属于points-into结构(谁引用了我的对象)。RSet的价值在于使得垃圾收集器不需要扫描整个堆找到谁引用了当前分区中的对象,只需要扫描RSet既可。
这概念有点绕,因为region与region之间的对象是可以相互引用的,拿图来说: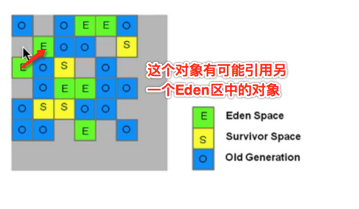
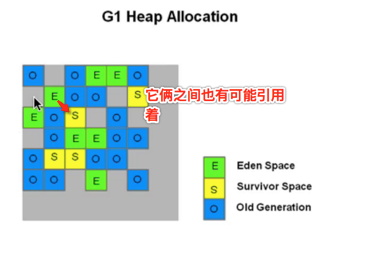
这就出现了RSet,专门用来记录谁引用了我。
- 下面来看图说明:Region1和Region3中的对象都引用了Region2中的对象,因此在Region2的RSet中记录了这两个引用。
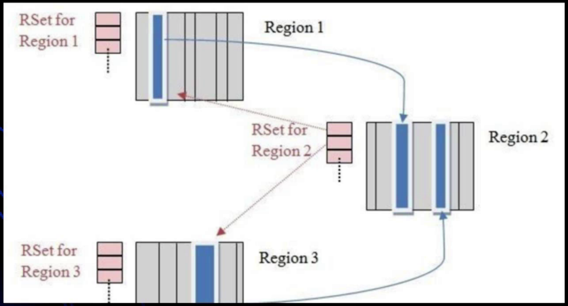
可以看到,对于每一个Region都会有一个RSet。
- G1 GC是在points-out【言外之意就是指向别人的关系】的card table之上再加了一层结构来构成points-into RSet:每个region会记录下到底哪些别的region有指向自己的指针,而这些指针分别在哪些card的范围内。
- 这个Rset其实是一个hash table,key是别的region的起始地址,value是一个集合,里面的元素是card table的index。举例来说,如果region A的RSet里有一项的key是region B,value里有index为1234的card,它的意思就是region B的一个card里有引用指向region A。所以对region A来说,该RSet记录的是points-into的关系;而card table仍然记录了points-out的关系。
- Snapshot-The-Beginning(SATB):SATB是G1 GC在并发标记阶段使用的增量式的标记算法。
- 并发标记是并发多线程的,但并发线程在同一时刻只扫描一个分区。
G1垃圾收集器角色划分与重要概念详解【纯理论】的更多相关文章
- G1垃圾收集器和CMS垃圾收集器 (http://mm.fancymore.com/reading/G1-CMS%E5%9E%83%E5%9C%BE%E7%AE%97%E6%B3%95.html#toc_8)
参考来源 JVM 体系架构 堆/栈的内存分配 静态和非静态方法的内存分配 CMS 回收算法 应用场景 CMS 垃圾收集阶段划分(Collection Phases) CMS什么时候启动 CMS缺点 G ...
- 详解 JVM Garbage First(G1) 垃圾收集器(转载)
前言 Garbage First(G1)是垃圾收集领域的最新成果,同时也是HotSpot在JVM上力推的垃圾收集器,并赋予取代CMS的使命.如果使用Java 8/9,那么有很大可能希望对G1收集器进行 ...
- G1 垃圾收集器架构和如何做到可预测的停顿(阿里)
CMS垃圾回收机制 参考:图解 CMS 垃圾回收机制原理,-阿里面试题 CMS与G1的区别 参考:CMS收集器和G1收集器优缺点 写这篇文章是基于阿里面试官的一个问题:众所周期,G1跟其他的垃圾回收算 ...
- 转:详解G1垃圾收集器
G1垃圾收集器入门 说明 concurrent: 并发, 多个线程协同做同一件事情(有状态) parallel: 并行, 多个线程各做各的事情(互相间无共享状态) 参考: What’s the dif ...
- 13.G1垃圾收集器
G1收集器是一款面向服务器的垃圾收集器,也是HotSpot在JVM上力推的垃圾收集器,并赋予取代CMS的使命.为什么对G1收集器给予如此高的期望呢?既然对G1收集器寄予了如此高的期望,那么他一定是有其 ...
- 深入理解 Java G1 垃圾收集器--转
原文地址:http://blog.jobbole.com/109170/?utm_source=hao.jobbole.com&utm_medium=relatedArticle 本文首先简单 ...
- G1 垃圾收集器
概念先知 什么是垃圾回收 简单的说垃圾回收就是回收内存中不再使用的对象. 垃圾回收的基本步骤: 查找内存中不再使用的对象 释放这些对象占用的内存 查找内存中不再使用的对象 如何判断哪些对象不再被使用呢 ...
- 【JVM】7、深入理解Java G1垃圾收集器
本文首先简单介绍了垃圾收集的常见方式,然后再分析了G1收集器的收集原理,相比其他垃圾收集器的优势,最后给出了一些调优实践. 一,什么是垃圾回收 首先,在了解G1之前,我们需要清楚的知道,垃圾回收是什么 ...
- G1 垃圾收集器入门
最近在复习Java GC,因为G1比较新,JDK1.7才正式引入,比较艰难的找到一篇写的很棒的文章,粘过来mark下.总结这篇文章和其他的资料,G1可以基本稳定在0.5s到1s左右的延迟,但是并不能保 ...
随机推荐
- shell每隔一秒钟就记录下netstat状态
说明 木马可能类似随机发送心跳包的操作,随机sleep.对这类情况写好了一个监听shell脚本,每隔一秒钟就记录下netstat状态. 代码 #!/bin/bash #功能:用于定时执行lsof 和 ...
- 树莓派3B安装arm64操作系统
pi64 pi64基于Debian 9,地址如下https://github.com/bamarni/pi64 烧录过程还是用SDFormatter格式化,用Win32DiskImager写入即可,没 ...
- 有关_meta内容(持续更新)
假设在models里创建了一个类:UserInfo model.UserInfo._meta.app_label #获取该类所在app的app名称 model.UserInfo._meta.model ...
- CSS 常用效果--持续更新
单行超出省略: white-space: nowrap; text-overflow:ellipsis; overflow:hidden; 多行超出省略: text-overflow: -o-elli ...
- sublime text3 修改快捷键为eclipse
Preferences -> Key bindings - User [ { "keys": ["shift+enter"], "command ...
- spark源码阅读 RDDs
RDDs弹性分布式数据集 spark就是实现了RDDs编程模型的集群计算平台.有很多RDDs的介绍,这里就不仔细说了,这儿主要看源码. abstract class RDD[T: ClassTag]( ...
- FutureTask源码阅读
FutureTask功能用法 类结构 源码中详细说明了FutureTask生命周期状态及变化 /** * The run state of this task, initially NEW. The ...
- 任务调度Quartz.Net之Windows Service
这个应该是关于Quartz.Net使用的最后一篇文章了,之前的介绍都是基于Web的,这种实现任务调度的方式很少见,因为不管是MVC.WebApi还是WebService,它们都需要寄宿在IIS上运行, ...
- Djang简单使用
用户访问内容 用户能够访问的所有的资源,都是程序猿提前暴露的,如果没有暴露,用户是不能进行访问的. diango重启的问题 当我们更改django中的代码的时候,django内部会检测到我们更 ...
- go 数据渲染到html页面 02
渲染到浏览器页面 //把数据渲染到浏览器 package main import ( "fmt" "text/template" "net/http& ...