李宏毅 Keras2.0演示
李宏毅 Keras2.0演示
不得不说李宏毅老师讲课的风格我真的十分喜欢的。
在keras2.0中,李宏毅老师演示的是手写数字识别(这个深度学习框架中的hello world)
创建网络
首先我们需要建立一个Network scratch,input是28*25的dimension,其实就是说这是一张image,image的解析度是28∗28,我们把它拉成长度是28∗28维的向量。output呢?
现在做的是手写数字辨识,所以要决定它是0-9的哪个数字,output就是每一维对应的数字,所以output就是10维。
中间假设你要两个layer,每个layer有500个hidden neuro,那么你会怎么做呢。
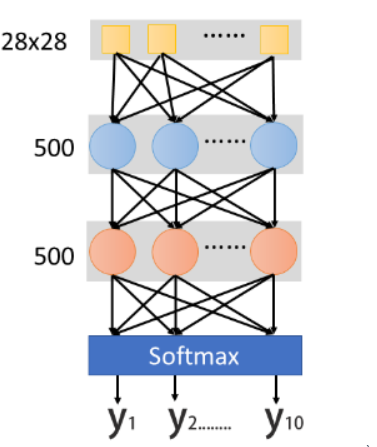
如果用Keras的话,首先需要声明一个network
model=Sequential()
然后你需要吧第一个hidden layer加进去,需要怎么做呢?很简单,只需要add即可。
model.add(Dense(input_dim=28*28,units=500,activation='relu'))
Dense意思就是说你加一个全连接网络,可以加其他的,比如加Con2d,就是加一个convolution layer,这些都很简单。input_dim是说输入的维度是多少,units表示hidden layer的neuro 数,
activation就是激活函数,每个activation是一个简单的英文缩写,比如relu,softplus,softsign,sigmoid,tanh,hard_sigmoid,linear 再加第二个layer,就不需再宣告input_dim,因为它的输入就是
上一层的units,所以不需要再定义一次,在这,只需要声明units和activation
model.add(Dense(units=500,activation='relu'))
配置
第二过程你要做一下configuration,你要定义loss function,选一个optimizer,以及评估指标metrics,其实所有的optimizer都是Gradent descent based,只是有不同的方法来决定
learning rate,比如Adam,SGD,RMSprop,Adagrad,Adalta,Adamax ,Nadam等,设完configuration之后你就可以开始train你的Network
model.compile(loss='categorical crossentropy',optimizer='adam',metrics=['accuracy'])
选择最好的方程
model.fit(x_train,y_train,batch_size=100,epochs=20)
call model.fit 方法,它就开始用Gradent Descent帮你去train你的Network,那么你要给它你的train_data input 和label,这里x_train代表image,y_train代表image的label,关于x_train和y_train的格式,你都要存成numpy array。
那么x_train怎样表示呢?第一个轴表示example,第二个轴代表每个example用多长vecter来表示它。x_train就是一个matrix。y_train也存成一个二维matrix,第一个维度一样代表training examples,
第二维度代表着现在有多少不同的case,只有一维是1,其他的都是0,每一维都对应一个数字,比如第0维对应数字0,如果第N维是1,对应的数字就是N。

使用模型
1.存储和载入模型Save and load models参考kers的说明
2.模型的使用:接下来就要拿这个Network进行使用,使用有两个不通的情景,这两个不同的情景一个是evalution,即为model在test data上表现的怎么样,call evaluate这个函数,然后把x_test,y_test喂给它,就会自动给你计算出Accuracy。它会output一个二维的向量,第一个维度代表了在test set上loss,第二个维度代表了在test set上的accuracy,这两个值是不一样的。loss可能用cross_entropy,Accuraccy是对与不对,即正确率。
case 1
score = model.evaluate(x_test,y_test)
print('Total loss on Testiong Set : ',score[0])
print('Accuracy of Testiong Set : ',score[1])
case 2
第二种是做predict,就是系统上线后,没有正确答案的,call predict进行预测
result = model.predict(x_test)
其他
Sequential序贯模型
是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。
Keras实现了很多层,包括core核心层,Convolution卷积层、Pooling池化层等非常丰富有趣的网络结构。
我们可以通过将层的列表传递给Sequential的构造函数,来创建一个Sequential模型。
from keras.models import Sequential
from keras.layers import Dense, Activation model = Sequential([
Dense(32, input_shape=(784,)),
Activation('relu'),
Dense(10),
Activation('softmax'),
])
也可以使用.add()方法将各层添加到模型中:
model = Sequential()
model.add(Dense(32, input_dim=784))
model.add(Activation('relu'))
输入数据的尺寸:
模型需要知道它所期待的输入的尺寸(shape)。出于这个原因,序贯模型中的第一层(只有第一层,因为下面的层可以自动的推断尺寸)需要接收关于其输入尺寸的信息,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。
- 某些2D层,例如Dense,支持通过参数input_dim指定输入尺寸,某些3D时序层支持input_dim和input_length参数。
- 传递一个input_shape参数给第一层,他是表示尺寸的元组(一个整数orNone的元组,其中None表示可能为任何整数)。在input_shape中不包含数据的batch大小。
model = Sequential()
model.add(Dense(32, input_shape=(784,))) #等价 model = Sequential()
model.add(Dense(32, input_dim=784))
编译
在训练模型之前,我们需要配置学习过程,这是通过compile方法完成的,他接收三个参数:
- 优化器optimizer:它可以是现有优化器的字符串标识符,如rmsprop或adagrad,也可以是Optimizer类的实例。详见:optimizers
- 损失函数loss:模型视图最小化的目标函数。他可以是现有损失函数的标识符,如categorical_crossentropy或者mse,也可以是一个目标函数。
- 评估标准metrics:对于任何分类问题,你都希望将其设置为metrics=['accuracy']。评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数。
# 多分类问题
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy']) # 二分类问题
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']) # 均方误差回归问题
model.compile(optimizer='rmsprop',
loss='mse') # 自定义评估标准函数
import keras.backend as K def mean_pred(y_true, y_pred):
return K.mean(y_pred) model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
训练
keras模型在输入数据和标签的Numpy矩阵上进行训练。为了训练一个模型,通常使用fit函数
# 对于具有2个类的单输入模型(二进制分类): model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy']) # 生成虚拟数据
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1)) # 训练模型,以 32 个样本为一个 batch 进行迭代
model.fit(data, labels, epochs=10, batch_size=32)
# 对于具有10个类的单输入模型(多分类分类): model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy']) # 生成虚拟数据
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1)) # 将标签转换为分类的 one-hot 编码
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10) # 训练模型,以 32 个样本为一个 batch 进行迭代
model.fit(data, one_hot_labels, epochs=10, batch_size=32)
源代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/9/9 13:23
# @Author : BaoBao
# @Mail : baobaotql@163.com
# @File : test5.py
# @Software: PyCharm import numpy as np
from keras.models import Sequential #序贯模型
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data() #载入数据
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number] x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28) x_train=x_train.astype('float32') #astype转换数据类型
x_test=x_test.astype('float32') y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10) x_train=x_train
x_test=x_test x_train=x_train/255
x_test=x_test/255
return (x_train,y_train),(x_test,y_test) (x_train,y_train),(x_test,y_test)=load_data() model=Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax')) model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy']) #train 模型
model.fit(x_train,y_train,batch_size=100,epochs=20) #测试结果 并打印accuary
result= model.evaluate(x_test,y_test) # print('\nTest loss:', result[0])
# print('\nAccuracy:', result[1]) print('TEST ACC :',result[1])

李宏毅 Keras2.0演示的更多相关文章
- keras2.0的一些变化
keras 变化太快了https://github.com/fchollet/keras/wiki/Keras-2.0-release-notes
- Ubuntu16.04下安装配置numpy,scipy,matplotlibm,pandas 以及sklearn+深度学习tensorflow配置+Keras2.0.6(非Anaconda环境)
1.ubuntu镜像源准备(防止下载过慢): 参考博文:http://www.cnblogs.com/top5/archive/2009/10/07/1578815.html 步骤如下: 首先,备份一 ...
- awk实战演示
awk:报告生成器,格式化文本输出. 我们一般使用的awk命令其实就是gawk,在centos7系统下,awk是gawk的链接文件. 基本用法:gawk [options] 'program' FI ...
- JMeter3.0及JMeter5.1开发WebService接口脚本(soap取样器 & http取样器)
由于5.1没有soap取样器了,所以用3.0演示. WebService接口信息 WebService接口地址:http://www.webxml.com.cn/WebServices/Weather ...
- 很带劲,Android9.0可以在i.MX8开发板上这样跑
米尔MYD-JX8MX开发板移植了Android9.0操作系统,现阶段最高版本的Android9.0操作系统将给您的产品在安全与稳定性方面带来更大的提升.可惜了,这里不能上传视频在i.MX8开发板跑A ...
- CRMEB单商户商城系统v4.0源码,含前端uni-app源码
CRMEB商城系统是基于ThinkPhp6.0+Vue开发的一套新零售移动电商系统,CRMEB系统就是集客户关系管理+营销电商系统,能够快速积累客户.会员数据分析.智能转化客户. 有效提高销售.会员维 ...
- 项目实战:Qt文件改名工具 v1.2.0(支持递归检索,搜索:模糊匹配,前缀匹配,后缀匹配;重命名:模糊替换,前缀追加,后缀追加)
需求 在整理文件和一些其他头文件的时候,需要对其名称进行整理和修改,此工具很早就应该写了,创业后,非常忙,今天抽空写了一个顺便提供给学习. 工具和源码下载地址 本篇文章的应用包和源码包可在 ...
- jQuery.rotate.js参数
CSS3 提供了多种变形效果,比如矩阵变形.位移.缩放.旋转和倾斜等等,让页面更加生动活泼有趣,不再一动不动.然后 IE10 以下版本的浏览器不支持 CSS3 变形,虽然 IE 有私有属性滤镜(fil ...
- 背水一战 Windows 10 (18) - 绑定: 与 Element 绑定, 与 Indexer 绑定, TargetNullValue, FallbackValue
[源码下载] 背水一战 Windows 10 (18) - 绑定: 与 Element 绑定, 与 Indexer 绑定, TargetNullValue, FallbackValue 作者:weba ...
随机推荐
- Mysql中查询索引和创建索引
查询索引 show index from table_name 1.添加PRIMARY KEY(主键索引) ALTER TABLE `table_name` ADD PRIMARY KEY ( ` ...
- 第三章 URL与视图
配置文件两种方式详解 先讲两种直接传参: 直接简单传参 app =Flask(__name__) app.config['DEBUG']=True app.config.update( DEBUG=t ...
- qt 启动参数 -qws
运行嵌入式程序 在嵌入式QT版本中,程序需要服务器或自己作为服务器程序. 服务器程序构造的方法是构造一个QApplication::GuiServe类型的QApplication对象.或者使用-qws ...
- Java数据库小项目02--管家婆项目
目录 项目要求 开发环境搭建 工具类JDBCUtils 创建管家婆数据表 项目分层 MainApp层 MainView层 ZhangWuController层 ZhangWuService层 Zhan ...
- OSX 改变PHP安装路径环境变量
当使用XAMPP来学习Laravel的时候,用composer安装laravel总是报错,说mcrypt is required ,但是当我在终端里打印 which php 显示的是usr/bin/p ...
- Java核心复习 —— ArrayList源码阅读
一.ArrayList 介绍 ArrayList是List接口可变数组的实现. 特点 非线程安全 查找和修改效率高 二.ArrayList 使用方法 remove元素 @Test public voi ...
- python排序之冒泡排序
def sort(list): for i in range(len(list)): for j in range(len(list) - i - 1): if list[j] < list[j ...
- 微信小程序 保存图片
微信小程序 保存图片 注: 此处使用的是小程序 wepy框架, 原生或其他的请注意转换写法 <div class="handle"> <button class= ...
- laravel如何从mysql数据库中随机抽取n条数据
laravel如何从mysql数据库中随机抽取n条数据 一.总结 一句话总结: inRandomOrder():$userQuestions=UserQuestion::where($map)-> ...
- Difference between C# compiler version and language version
Difference between C# compiler version and language version As nobody gives a good enough answer ...