数据分析 - numpy 模块
numpy
概述
▨ Numerical Python. 补充了python所欠缺的数值计算能力
▨ Numpy是其他数据分析及机器学习库的底层库
▨ Numpy完全标准C语言实现,运行效率充分优化
▨ Numpy开源免费
基本数据结构
| 类型名 | 类型表示符 |
|---|---|
| 布尔类型 | bool_ |
| 有符号整型 | int8/16/32/64 |
| 无符号整型 | uint8/16/32/64 |
| 浮点型 | float16/32/64 |
| 复数型 | complex64/128 |
| 字符串型 | str_,每个字符32位Unicode |
可见是不允许存储特殊对象类型的, 因为 numpy 的目标主要是处理数字类型的
自定义复合类型
基础的数据类型无法满足需求, 我就是想传入复杂数据
方式一 - 直接设置
取元素只能通过索引 [n] 的形式去取
或者基于 默认别名 'fn' 的形式 ( n 依旧是索引下标 )
import numpy as np
data = [('zs', [90, 80, 70], 15),
('ls', [99, 89, 79], 16),
('ww', [91, 81, 71], 17)]
# 2个Unicode字符,3个int32,1个int32组成的元组
ary = np.array(data, dtype='U2, 3int32, int32')
print(ary, ary.dtype)
"""
[('zs', [90, 80, 70], 15)
('ls', [99, 89, 79], 16)
('ww', [91, 81, 71], 17)]
[('f0', '<U2'), ('f1', '<i4', (3,)), ('f2', '<i4')]
"""
print(ary[1][2], ary[1]['f2']) # 16 16
方式二 - 带别名设置
可以通过别名进行获取
import numpy as np
data = [('zs', [90, 80, 70], 15),
('ls', [99, 89, 79], 16),
('ww', [91, 81, 71], 17)]
# 第二种设置dtype的方式 为每个字段起别名
ary = np.array(data, dtype=[('name', 'str_', 2), # 别名, 类型, 元素个数
('scores', 'int32', 3),
('age', 'int32', 1)])
print(ary[2]['age']) #
方式三 - 字典形式设置
键值对形式相同位置简历映射,
name 键统一设置 别名
formats 键统一设置 类型和数量
是结合了一二两种方式的结果
import numpy as np
data = [('zs', [90, 80, 70], 15),
('ls', [99, 89, 79], 16),
('ww', [91, 81, 71], 17)]
# 第三种设置dtype的方式
ary = np.array(data, dtype={
'names': ['name', 'scores', 'age'],
'formats': ['U2', '3int32', 'int32']})
print(ary[2]['scores']) # [91 81 71]
方式四 - 字节方式设置
依旧是字典格式
使用别名作为 键
值 为 元组形式
( '数量类型', 定位字节起点 )
可以手动指定每个字段的存储偏移量
举栗子
('U3',0) Unicode 字符是32 位, 占4字节, 三个占位 12字节, 在 12 字节处结束
('3int32', 16) 定位在 16 字节处 , 即距离上面的又空了 4 字节, 然后 又是占位 12字节 , 在 28 字节处结束
('int32', 28) 定位在 28 字节处, 占位 12 字节, 在 40 字节处结束
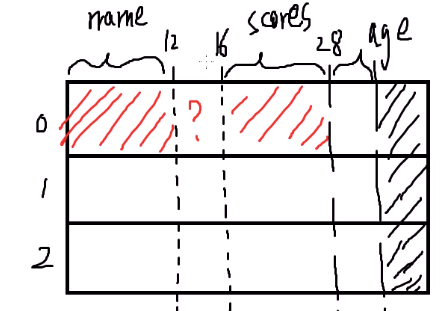
import numpy as np
data = [('zs', [90, 80, 70], 15),
('ls', [99, 89, 79], 16),
('ww', [91, 81, 71], 17)]
# 第四种设置dtype的方式 手动指定每个字段的存储偏移字节数
# name从0字节开始输出,输出3个Unicode
# scores从16字节开始输出,输出3个int32
ary = np.array(data, dtype={
'name': ('U3', 0),
'scores': ('3int32', 16),
'age': ('int32', 28)})
print(ary[0]['name']) # zs
存储日期类型数据
只能识别 YYYY-MM-DD HH:MM:SS 的格式 , - 换成 / 就不行
可以进行一定程度的运算
# ndarray数组中存储日期类型数据
dates = np.array(['', '2012-01-01', '2013-01-01 11:11:11', '2011-02-01'])
print(dates, dates.dtype)
# ['2011' '2012-01-01' '2013-01-01 11:11:11' '2011-02-01'] <U19 dates = dates.astype('M8[D]') # datetime64 精确到 Day print(dates, dates.dtype)
# ['2011-01-01' '2012-01-01' '2013-01-01' '2011-02-01'] datetime64[D] print(dates[-1] - dates[0]) # 31 days dates = dates.astype('int32')
print(dates, dates.dtype) # [14975 15340 15706 15006] int32
类型字符码 - 数据类型的简写
| 类型 | 字符码 |
|---|---|
| bool_ | ? |
| int8/16/32/64 | i1/2/4/8 |
| uint8/16/32/64 | u1/2/4/8 |
| float16/32/64 | f2/4/8 |
| complex64/128 | c8/16 |
| str_ | U |
| datetime64 | M8[Y/M/D/h/m/s] |
数组 - nadarray 对象
概念
类似于列表, 可以多维嵌套, 但是要求必须内部存储相同类型的数据
即同质数组, 相同的数据类型的空间占用相同, 且查询方便
空间结构
ary = np.array([1, 2, 3, 4, 5])
"""
_______________________________________
a -----> | nadarray 对象 |
| |
| 元数据 |
|_______ |
|_dim___| |
|_dtype_| _____________________ |
|_data__| ---> |_1_|_2_|_3_|_4_|_5_| |
|_shape_| ---> (5,) |
|_______|______________________________| """
元数据 (metadata)
存储对数组的描述信息, 如 : dim count, dtype, dara, shape 等
实际数据
完整的数组数据, 将实际数据与元数据分开存放
一方面提高了内存空间的使用效率
另一方面减少对实际数据的访问频率,提高性能。
创建语法
np.array([[], [], []]) # 直接创建 np.arange(0, 10, 1) # 序列创建 np.zeros(10) # 全 0 创建 np.ones(10) # 全 1 创建 np.zeros_like(ary) # 仿结构创建 全 0 数组 np.ones_like(ary) # 仿结构创建 全 1 数组
示例
import numpy as np a = np.array([1, 2, 3, 4, 5, 6])
print(a) # [1 2 3 4 5 6] b = np.arange(7, 13, 1)
print(b) # [ 7 8 9 10 11 12] c = np.zeros(6)
print(c) # [ 0. 0. 0. 0. 0. 0.] d = np.ones(6)
print(d) # [ 1. 1. 1. 1. 1. 1.]
print(d / 2) # [ 0.5 0.5 0.5 0.5 0.5 0.5] e = np.array([[1, 2, 3], [4, 5, 6]])
print(np.ones_like(e))
"""
[[1 1 1]
[1 1 1]]
"""
nadarray 对象属性 - 基本操作
数组维度
ary.shape 数组维度
可以直接进行更改数组结构
但是更改需要合理, 比如 6 元素 更改为 3*3 需要9元素则无法满足从而报错
ary = np.array([1, 2, 3, 4, 5, 6])
print(ary, ary.shape) # [1 2 3 4 5 6] (6,)
ary.shape = (2, 3)
print(ary, ary.shape)
"""
[[1 2 3]
[4 5 6]] (2, 3)
"""
print(ary[1][1]) #
元素类型
ary.dtype 数组元素类型
ary.astype 修改元素类型
数据类型直接更改是不可取的, 需要使用 astype 方法进行更改
利用重新开辟新的空间来赋值存储
即此方法不会改变原值, 需要用返回值进行复制
# 数组元素类型
ary = np.array([1, 2, 3, 4, 5, 6])
print(ary, ary.dtype) # [1 2 3 4 5 6] int32
# ary.dtype = np.int64
# print(ary, ary.dtype)
# 更改数据类型
b = ary.astype('float32')
print(ary, ary.dtype) # [1 2 3 4 5 6] int32
print(b, b.dtype) # [ 8.58993459e+09 1.71798692e+10 2.57698038e+10] float32
数组元素个数
ary.size 返回数组元素个数
len(ary) 返回数组元素个数
ary = np.array([1, 2, 3, 4, 5, 6])
print(ary.size) #
print(len(ary)) #
数组元素索引
下标
# 数组元素的索引
ary = np.arange(1, 9)
ary.shape = (2, 2, 2)
print(ary, ary.shape)
"""
[[[1 2]
[3 4]] [[5 6]
[7 8]]] (2, 2, 2)
""" print(ary[0]) # 0页数据
"""
[[1 2]
[3 4]]
""" print(ary[0][0]) # 0页0行数据
"""
[1 2]
""" print(ary[0][0][0]) # 0页0行0列数据
"""
1
""" print(ary[0, 0, 0]) # 0页0行0列数据
"""
1
""" # 使用for循环,把ary数组中的元素都遍历出来。
for i in range(ary.shape[0]):
for j in range(ary.shape[1]):
for k in range(ary.shape[2]):
print(ary[i, j, k], end=' ') # 1 2 3 4 5 6 7 8
ndarray对象 - 维度操作详解
视图变维
reshape() - 改变维度
在原数据上建立的 映射, 即源数据的刚刚会影响其他视图的展示
import numpy as np a = np.arange(1, 7)
# print(a, a.shape) # [1 2 3 4 5 6] (6,) # 测试视图变维 reshape() ravel()
b = a.reshape(2, 3)
print(b, b.shape)
"""
[[1 2 3]
[4 5 6]] (2, 3)
""" a[0] = 999
print(b, b.shape)
"""
[[999 2 3]
[ 4 5 6]] (2, 3)
"""
ravel() - 扁平化处理
将高维度变为一维
print(b, b.shape)
"""
[[999 2 3]
[ 4 5 6]] (2, 3)
""" c = b.ravel()
print(c, c.shape)
# [999 2 3 4 5 6] (6,)
总结
视图变维是基于源文件的, 因此不会开辟新的内存空间
ravel 的平铺可以简单的展开数组进行一维输出
复制变维
flatten() - 扁平化处理
使用方法和结果同 ravel
但是是重新开辟空间处理, 源数据与新数据是空间隔离互不干涉的
import numpy as np # 复制变维 flatten() copy()
a = np.array([[1, 2, 3], [4, 5, 6]]) b = a.flatten() # 扁平化
print(b, b.shape) # [1 2 3 4 5 6] (6,)
a[0] = 1
print(a, a.shape)
"""
[[1 1 1]
[4 5 6]] (2, 3)
""" print(b, b.shape) # [1 2 3 4 5 6] (6,)
就地变维
shape()
resize()
直接基于源数据的更改
import numpy as np # 就地变维
a = np.arange(1, 7)
a.resize(3, 2)
print(a, a.shape)
"""
[[1 2]
[3 4]
[5 6]] (3, 2)
"""
ndarray对象 - 索引操作
ndarray数组 - 切片
[::] / [:] 全部
[m:n] m到n 左包右不包 , 为负数表示倒数 m / n 位
[::n] 步长
[::-1] 倒序
切片是会生成新的对象, 因此 直接使用 [::] 来代替复制是可以的
"""
demo05_shape.py
"""
import numpy as np a = np.arange(1, 10)
print(a) # [1 2 3 4 5 6 7 8 9]
print(a[:3]) # [1 2 3]
print(a[3:6]) # [4 5 6]
print(a[6:]) # [7 8 9]
print(a[::-1]) # [9 8 7 6 5 4 3 2 1]
print(a[:-4:-1]) # [9 8 7]
print(a[::]) # [1 2 3 4 5 6 7 8 9]
print(a[::3]) # [3 6 9]
print(a[1::3]) # [3 6 9]
print(a[2::3]) # [3 6 9]
高维切片
[ 行的切片 , 列的切片 ]
# 高维数组切片
a = a.reshape(3, 3)
print(a, a.shape)
"""
[[1 2 3]
[4 5 6]
[7 8 9]] (3, 3)
""" print(a[:2, :2])
"""
[[1 2]
[4 5]]
""" print(a[:2, 0])
"""
[1 4]
"""
ndarray数组 - 掩码操作
非常方便两个数组的重叠映射, 将 True 的元素输出
import numpy as np a = np.arange(1, 8)
mask = a > 5
print(a) # [1 2 3 4 5 6 7]
print(mask) # [False False False False False True True]
print(a[mask]) # [6 7]
此方法可以进行相当多的炫酷操作, 如下
import numpy as np # 输出100以内3与7的公倍数。
a = np.arange(1, 100)
mask = (a % 3 == 0) & (a % 7 == 0)
print(a[mask]) # [21 42 63 84]
# 利用掩码运算对数组进行排序
p = np.array(['Mi', 'Apple', 'Huawei', 'Oppo'])
r = [1, 3, 2, 0]
print(p[r]) # ['Apple' 'Oppo' 'Huawei' 'Mi']
多维数组 - 组合与拆分
垂直方向操作
vstack - 合并
vsplit - 拆分
垂直方向合并及列合并, 增加列
拆分需要合理, 不合理的炒粉会报错 ( 5个拆成 4 个之类的 )
# 垂直方向合并
c = np.vstack((a, b))
# 把c拆成2份, a与b
a, b = np.vsplit(c, 2)
import numpy a = numpy.array([1, 2, 3])
b = numpy.array([4, 5, 6]) c = numpy.vstack((a, b))
# print(c)
"""
[[1 2 3]
[4 5 6]]
""" a, b = numpy.vsplit(c, 2)
print(a) # [[1 2 3]]
print(b) # [[4 5 6]]
水平方向操作
hstack - 合并
hsplit - 拆分
水平方向合并及行合并, 增加行长度
拆分需要合理, 不合理的炒粉会报错 ( 5个拆成 4 个之类的 )
# 水平方向合并
c = np.hstack((a, b))
# 把c拆成2份, a与b
a, b = np.hsplit(c, 2)
import numpy a = numpy.array([1, 2, 3])
b = numpy.array([4, 5, 6]) c = numpy.hstack((a, b))
print(c) # [1 2 3 4 5 6] a, b = numpy.hsplit(c, 2)
print(a) # [1 2 3]
print(b) # [4 5 6]
深度方向操作
dstack - 合并
dsplit - 拆分
深度方向合并即维度合并, 增加维度
拆分需要合理, 不合理的炒粉会报错 ( 比如拆 3 份 )
# 深度方向合并
c = np.dstack((a, b))
# 把c拆成2份, a与b
a, b = np.dsplit(c, 2)
import numpy a = numpy.array([1, 2, 3])
b = numpy.array([4, 5, 6]) c = numpy.dstack((a, b))
print(c)
"""
[[[1 4]
[2 5]
[3 6]]]
""" a, b = numpy.dsplit(c, 2)
print(a)
"""
[[[1]
[2]
[3]]]
"""
print(b)
"""
[[[4]
[5]
[6]]]
"""
import numpy a = numpy.array([[1, 2, 3], [4, 5, 6]])
b = numpy.array([[7, 8, 9], [10, 11, 12]]) c = numpy.dstack((a, b))
# print(c)
"""
[[[ 1 7]
[ 2 8]
[ 3 9]] [[ 4 10]
[ 5 11]
[ 6 12]]]
""" a, b = numpy.dsplit(c, 2)
# print(a)
"""
[[[1]
[2]
[3]] [[4]
[5]
[6]]]
""" # print(b)
"""
[[[ 7]
[ 8]
[ 9]] [[10]
[11]
[12]]]
"""
多维数组 - 组合与拆分相关函数
concatenate( ) - 组合
split () - 拆分
# 把a与b按照axis的轴向进行组合
# axis 数组组合的轴向
# 0:垂直 1:水平 2:深度
# 注意:若axis=2,则要求a与b都是3维数组
c = np.concatenate((a, b), axis=0)
# 把c按照axis的轴向拆成2部分
a, b = np.split(c, 2, axis=0)
简单的一维数组的组合方案
row_stack - 行合并
column_stack - 列合并
# 把两个一维数组摞在一起成两行
c = np.row_stack((a, b))
# 把两个一维数组并在一起成两列
c = np.column_stack((a, b))
import numpy a = numpy.array([1, 2, 3, 4, 5, 6])
b = numpy.array([7, 8, 9, 10, 11, 12]) c = numpy.row_stack((a, b))
print(c)
"""
[[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]]
""" d = numpy.column_stack((a, b))
print(d)
"""
[[ 1 7]
[ 2 8]
[ 3 9]
[ 4 10]
[ 5 11]
[ 6 12]]
"""
ndarray数组 - 其他属性
▨ shape, dtype, size ....
▨ ndim 维数 n维数组的那个n
▨ itemsize 每个元素的字节数
▨ nbytes 数组占用内存的总字节数
▨ real 复数数组的数据的实部
▨ imag 复数数组的数据的虚部
▨ T 返回数组的转置视图
▨ flat 返回数组的扁平迭代器
"""
demo09_attr.py 其他属性
"""
import numpy as np data = np.array([[1 + 1j, 2 + 4j, 3 + 7j],
[4 + 2j, 5 + 5j, 6 + 8j],
[7 + 3j, 8 + 6j, 9 + 9j]])
print(data.ndim) #
print(data.dtype, data.itemsize) # complex128 16
print(data.nbytes) #
print(data.real)
"""
[[ 1. 2. 3.]
[ 4. 5. 6.]
[ 7. 8. 9.]]
"""
print(data.imag)
"""
[[ 1. 4. 7.]
[ 2. 5. 8.]
[ 3. 6. 9.]]
""" print(data.T)
"""
[[ 1.+1.j 4.+2.j 7.+3.j]
[ 2.+4.j 5.+5.j 8.+6.j]
[ 3.+7.j 6.+8.j 9.+9.j]]
""" print([x for x in data.flat])
# [(1+1j), (2+4j), (3+7j), (4+2j), (5+5j), (6+8j), (7+3j), (8+6j), (9+9j)]
数据分析 - numpy 模块的更多相关文章
- Python数据分析-Numpy数值计算
Numpy介绍: NumPy是高性能科学计算和数据分析的基础包.它是pandas等其他各种工具的基础. NumPy的主要功能: 1)ndarray,一个多维数组结构,高效且节省空间 2)无需循环对整组 ...
- 数据分析01 /numpy模块
数据分析01 /数据分析之numpy模块 目录 数据分析01 /数据分析之numpy模块 1. numpy简介 2. numpy的创建 3. numpy的方法 4. numpy的常用属性 5. num ...
- 【Python 数据分析】Numpy模块
Numpy模块可以高效的处理数据,提供数组支持.很多模块都依赖他,比如:pandas.scipy.matplotlib 安装Numpy 首先到网站:https://www.lfd.uci.edu/~g ...
- 开发技术--Numpy模块
开发|Numpy模块 Numpy模块是数据分析基础包,所以还是很重要的,耐心去体会Numpy这个工具可以做什么,我将从源码与 地产呢个实现方式说起,祝大家阅读愉快! Numpy模块提供了两个重要对象: ...
- numpy模块常用函数解析
https://blog.csdn.net/lm_is_dc/article/details/81098805 numpy模块以下命令都是在浏览器中输入. cmd命令窗口输入:jupyter note ...
- numpy模块、matplotlib模块、pandas模块
目录 1. numpy模块 2. matplotlib模块 3. pandas模块 1. numpy模块 numpy模块的作用 用来做数据分析,对numpy数组(既有行又有列)--矩阵进行科学计算 实 ...
- pandas、matplotlib、Numpy模块的简单学习
目录 一.pandas模块 二.matplotlib模块 1.条形图 2. 直方图 3.折线图 4.散点图+直线图 三.numpy 一.pandas模块 pandas是BSD许可的开源库,为Pytho ...
- Python之路-numpy模块
这里是首先需要安装好Anaconda Anaconda的安装参考Python之路-初识python及环境搭建并测试 配置好环境之后开始使用Jupyter Notebook 1.打开cmd,输入 jup ...
- numpy模块(详解)
重点 索引和切片 级联 聚合操作 统计操作 矩阵 什么是数据分析 是把隐藏在一些看似杂乱无章的数据背后的信息提炼出来,总结出所研究对象的内在规律 数据分析是用适当的方法对收集来的大量数据进行分析,帮助 ...
随机推荐
- 第九章·Logstash深入-Logstash配合rsyslog收集haproxy日志
rsyslog介绍及安装配置 在centos 6及之前的版本叫做syslog,centos 7开始叫做rsyslog,根据官方的介绍,rsyslog(2013年版本)可以达到每秒转发百万条日志的级别, ...
- kubernetes资源清单之DaemonSet
什么是 DaemonSet? DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本.当有节点加入集群时,也会为他们新增一个 Pod . 当有节点从集群移除时,这些 Pod 也会被回收 ...
- Bootstrap常用的自带插件
Bootstrap自带的那些常用插件. 模态框 模态框的HTML代码放置的位置 务必将模态框的HTML代码放在文档的最高层级内(也就是说,尽量作为 body 标签的直接子元素),以避免其他组件影响模态 ...
- Tomcat 启动卡在 Root WebApplicationContext: initialization completed in
tomcat 启动一直卡在 Root WebApplicationContext: initialization completed in 重启了很多次,更换jdk版本,tomcat版本都不行. to ...
- “联邦对抗技术大赛”9月开战 微众银行呼唤开发者共同“AI创新”
“联邦对抗技术大赛”9月开战 微众银行呼唤开发者共同“AI创新” 从<第五元素>中的智能系统到<超体>中的信息操控,在科幻电影中人工智能已经发展到了极致.而在现实中,目前 ...
- Python往kafka生产消费数据
安装 kafka: pip install kafka-python 生产数据 from kafka import KafkaProducer import json ''' 生产者demo 向te ...
- 使用Sendinput以及GetAsyncKeyState来模拟按键延时
Code: #include <windows.h> #include <tchar.h> #include <iostream> BOOL flag = TRUE ...
- Flutter入门(三)-底部导航+路由
* StatefulWidget 如果想改变页面中的数据就要用到StatefulWidget,之前自定义组件继承的StatelessWidget是不能动态修改页面数据的 //自定义有状态组件 clas ...
- Java-JsonUtil工具类
import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; i ...
- @Value和@ConfigurationProperties
1.@Value用法 https://blog.csdn.net/u010832551/article/details/73826914 2.@ConfigurationProperties用法 ht ...