sklearn4_混合分类器
python机器学习-乳腺癌细胞挖掘(博主亲自录制视频)
https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campaign=commission&utm_source=cp-400000000398149&utm_medium=share

混合分类器,逻辑回归,支持向量,knn
multiple_classifier.py
# -*- coding: utf-8 -*-
"""
Created on Sat Jan 6 18:02:19 2018 @author: daxiong
""" #导入sklearn测试数据库
from sklearn import datasets
#用于训练数据和测试数据分类
from sklearn.cross_validation import train_test_split
#导入逻辑回归分类器
from sklearn.linear_model import LogisticRegression
#导入knn分类器
from sklearn.neighbors import KNeighborsClassifier
#导入支持向量分类器
from sklearn.svm import SVC #加载 iris 的数据,把属性存在 X,类别标签存在 y
iris = datasets.load_iris()
iris_X = iris.data
iris_y = iris.target #把数据集分为训练集和测试集,其中 test_size=0.3,即测试集占总数据的 30%
X_train, X_test, y_train, y_test = train_test_split(
iris_X, iris_y, test_size=0.3) #建立逻辑回归分类器
model_logistic=LogisticRegression()
# 把数据交给模型训练
model_logistic.fit(X_train, y_train) #建立knn分类器
model_knn = KNeighborsClassifier()
#训练
model_knn.fit(X_train, y_train) #建立支持向量分类器
modle_svc = SVC()
# 把数据交给模型训练
modle_svc.fit(X_train, y_train) #模型评分
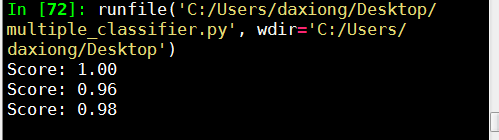
print('Score: %.2f' % model_logistic.score(X_test, y_test)) print('Score: %.2f' % model_knn.score(X_test, y_test))
print('Score: %.2f' % modle_svc.score(X_test, y_test))
https://study.163.com/provider/400000000398149/index.htm?share=2&shareId=400000000398149( 欢迎关注博主主页,学习python视频资源,还有大量免费python经典文章)

sklearn4_混合分类器的更多相关文章
- Adaboost 算法
一 Boosting 算法的起源 boost 算法系列的起源来自于PAC Learnability(PAC 可学习性).这套理论主要研究的是什么时候一个问题是可被学习的,当然也会探讨针对可学习的问题的 ...
- Adaboost 2
本文不定期更新.原创文章,转载请注明出处,谢谢. Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类 ...
- adaboost算法
三 Adaboost 算法 AdaBoost 是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器,即弱分类器,然后把这些弱分类器集合起来,构造一个更强的最终分类器.(很多博客里说的三个臭皮匠 ...
- 【机器学习笔记之四】Adaboost 算法
本文结构: 什么是集成学习? 为什么集成的效果就会好于单个学习器? 如何生成个体学习器? 什么是 Boosting? Adaboost 算法? 什么是集成学习 集成学习就是将多个弱的学习器结合起来组成 ...
- face recognition[翻译][深度人脸识别:综述]
这里翻译下<Deep face recognition: a survey v4>. 1 引言 由于它的非侵入性和自然特征,人脸识别已经成为身份识别中重要的生物认证技术,也已经应用到许多领 ...
- Adaboost 算法实例解析
Adaboost 算法实例解析 1 Adaboost的原理 1.1 Adaboost基本介绍 AdaBoost,是英文"Adaptive Boosting"(自适应增强)的缩写,由 ...
- 浅谈 Adaboost 算法
http://blog.csdn.net/haidao2009/article/details/7514787 菜鸟最近开始学习machine learning.发现adaboost 挺有趣,就把自己 ...
- 【软件分析与挖掘】ELBlocker: Predicting blocking bugs with ensemble imbalance learning
摘要: 提出一种方法——ELBlocker,用于自动检测出Blocking Bugs(prevent other bugs from being fixed). 难度在于这些Blocking Bugs仅 ...
- 数据挖掘算法学习(八)Adaboost算法
本文不定期更新.原创文章,转载请附上链接http://blog.csdn.net/iemyxie/article/details/40423907 谢谢 Adaboost是一种迭代算法,其核心思想是针 ...
随机推荐
- Vue页面缓存和不缓存的方法
第一步 在app中设置需要缓存的div //缓存的页面 <keep-alive> <router-view v-if="$route.meta.keepAlive" ...
- Centos 7.0 界面
执行:systemctl get-default //显示默认的界面方式 multi-user.target //命令行界面 graphical.target //图形化界面 执行:systemctl ...
- 8.7.ZooKeeper Watcher监听
1.ZooKeeper Watcher ZooKeeper 提供了分布式数据发布/订阅功能,一个典型的发布/订阅模型系统定义了一种一对多的订阅关系,能让多个订阅者同时监听某一个主题对象, 当这个主题对 ...
- uCos-II移值(二)
os_cpu_c.c文件 该文件主要是根据处理器平台特点完成任务堆栈初始化函数OSTaskStkInit以及其他几个用户Hook函数的编写,其中必须要实现的函数是OSTaskStkInit(在创建任务 ...
- 更新对象sql语句
可以这么理解,我们以0为临界值,控制 OR 前 或者 OR后面部分的执行,为啥不是大于0作为临界值,因为这是int型主键. 之前我觉得这不就是炫酷嘛,这么些实际场景在哪里?下面来介绍一下实际的应用 ...
- demjson
demjson.decode() 可以扩展json的类型
- NLP/CL 顶会收录
全文转载自知乎@刘知远老师:初学者如何查阅自然语言处理学术资料(2016修订版). 1. 国际学术组织.学术会议与学术论文 自然语言处理(natural language processing,NLP ...
- 使用python获得屏幕截图并保存为位图文件
直接上代码: import win32gui import win32ui from ctypes import windll import Image hwnd = win32gui.FindWin ...
- [SC] OpenSCManager 失败 5:拒绝访问
问题:[SC] OpenSCManager 失败 5: 网查这个错误信息指拒绝访问 权限不足 1.解决: 以管理员身份运行cmd,即可 查询这个提示是指什么错误时,看网上有很多文章写用下面这种方法, ...
- hadoop中的JournalNode
1.在HADOOP扮演的角色 JournalNode是在MR2也就是Yarn中新加的,journalNode的作用是存放EditLog的, 在MR1中editlog是和fsimage存放在一起的然后S ...