MySQL 优化--持续整理
一、innodb体系结构优化:
1、IO优化
IO能力不足时

innodb_io_capacity 应该降低
innodb_max_dirty_pages_pct 应该降低
innodb_max_dirty_pages_pct_lwm 如果设置了应该考虑降低
innodb_read_io_threads
innodb_write_io_threads
2、Purge Thread
innodb_purge_threads 设置purge线程个数,用于undo页回收
innodb_purge_batch_size 设置Purge undo 的页数量,默认300
innodb_max_purge_lag
控制undo log history list的长度,0表示不对history list 做任何限制。当大于0时,就会
延缓DML的操作。延缓对象是行。
innodb_max_purge_lag_delay 用来控制delay的最大毫秒数。
3、内存池buffer pool
innodb_buffer_pool_size 内存池大小设置
innodb_buffer_pool_instances 多内存池设置
4、LRU List、Free List和Flush List
innodb_old_blocks_pct 设置新页放到LRU List位置 mid位置
innodb_old_blocks_time mid位置后的页,要多久能被加入到LRU列表的热端
5、Redo Log
innodb_log_buffer_size redo buffer 的大小
三种情况刷新日志缓冲
1)master thread 每秒刷
2)事务提交时刷
3)日志空间小于1/2刷
6、Page Cleaner
innodb_io_capacity
合并插入缓冲时,合并的数量为innodb_io_capacity的5%
刷新脏页时,刷新的数量为innodb_io_capacity
innodb_max_dirty_pages_pct
innodb_max_dirty_pages_pct_lwm
innodb_adaptive_flushing 自适应刷新
InnoDB刷新脏页的规则是在如下三种情况下才会把InnoDB_Buffer_Pool的脏页刷入磁盘:
当超过innodb_max_dirty_pages_pct设定的值时。
重做日志ib_logfile文件写满了以后。
机器空闲的时候。
当写操作很频繁的时候,重做日志ib_logfile切换的次数就会很频繁,只要有一个写满了,就会将脏页大批量地刷入磁盘,而这会对系统的整体性能造成不小的影响。为了避免过大的磁盘I/O,innodb_adaptive_flushing会自适应刷新,它使用了一个全新的算法,以便根据重做日志ib_logfile生成的速度和刷新频率来将脏页刷入磁盘,这样重做日志ib_logfile还没有写满时,也可以刷新一定的量。
7、insert buffer(change buffer)
innodb_change_buffering changebuffer 支持的类型 insert、update、delete等
innodb_change_buffer_max_size insert buffer 的大小,占innodb_buffer_pool的百分比(默认25%,最大50%)
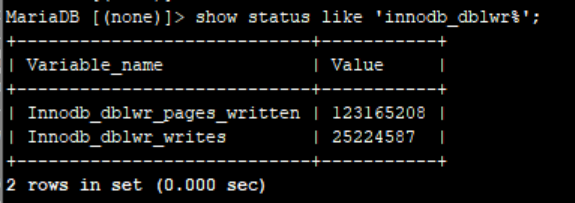
8、double write 两次写
show status like 'innodb_dblwr%';
如果Innodb_dblwr_pages_written:Innodb_dblwr_writes远小于64:1说明系统压力很小
9、自适应哈希索引
10、异步IO(AIO)
innodb_use_native_aio 应打开异步IO
用户发布一个IO请求后,可以立即再发出另一个IO请求,当全部IO请求发送完毕,等待所有
IO操作完成。
AIO还可以进行IO Merge 操作。
11、刷新临近页
innodb_flush_neighbors 根据系统IO能力调整,如果是IO处理能力和高,需要关闭
12、
二、索引优化:
1、打开Multi-Range Read功能(5.6新功能)
它的作用针对基于辅助/第二索引的查询,减少随机IO,并且将随机IO转化为顺序IO,提高查询效率。
1)打开
set optimizer_switch='mrr=on mrr_cost_based=on'; #mrr_cost_based表示开启mrr后,优化器是否根据cost来决定是否使用mrr
set oprimizer_switch='mrr=off';
2)MRR内存设置
对于MRR,参数read_rnd_buffer_size用来控制键值缓冲区的大小。
2、打开Index Condition Pushdown功能(5.6新功能)
set optimizer_switch = 'index_condition_pushdown=off';
set optimizer_switch = 'index_condition_pushdown=on';
2、Index Condition Pushdown(ICP)


sync_binlog
sync_binlog=1,表示提交一次写一次binlog。
当一个事务发出commit动作之前,由于sync_binlog=1,因此会将二进制日志立即写入磁盘。
如果这时已经写入了二进制日志,但是提交没有发生,并且此事发生了宕机,那么在Mysql
数据库下次启动时,由于commit操作并没有发生,这个事务会被回滚掉。但是,二进制日志
已经记录了该事务信息,不能被回滚。这个问题由参数innodb_support_xa 来解决,
innodb_support_xa= 1 保证二进制日志和InnoDB 存储引擎数据文件同步。
binlog-do-db/binlog-ignore-db
log-slave-update
binlog_format
expire_logs_days
MySQL 优化--持续整理的更多相关文章
- 关于MYSQL优化(持续更新)
*利用MYSQL数据缓存提高效率,注意事项: 1.应用环境:不经常改变的表及对此表相同的查询 2.不适用于服务器端编写的语句 3.根据数据使用频率,合理分解表 4.合理使用默认条件,提高命中率 5.统 ...
- MYSQL优化之碎片整理
MYSQL优化之碎片整理 在MySQL中,我们经常会使用VARCHAR.TEXT.BLOB等可变长度的文本数据类型.不过,当我们使用这些数据类型之后,我们就不得不做一些额外的工作--MySQL数据 ...
- MySQL优化整理
一.SQL优化 1.show status查看各种sql的执行频率 SHOW STATUS 可以根据需要显示 session 级别的统计结果和 global级别的统计结果. 显示当前sessi ...
- 整理的网上的MySQL优化文章总结
MySQL优化 Linux优化 IO优化 调整Linux默认的IO调度算法. IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调 ...
- [转] MySql 优化 大数据优化
一.我们可以且应该优化什么? 硬件 操作系统/软件库 SQL服务器(设置和查询) 应用编程接口(API) 应用程序 ------------------------------------------ ...
- mysql优化案例
MySQL优化案例 Mysql5.1大表分区效率测试 Mysql5.1大表分区效率测试MySQL | add at 2009-03-27 12:29:31 by PConline | view:60, ...
- MySQL优化聊两句
原文地址:http://www.cnblogs.com/verrion/p/mysql_optimised.html MySQL优化聊两句 MySQL不多介绍,今天聊两句该如何优化以及从哪些方面入手, ...
- mysql 优化
1.存储过程造数据 CREATE DEFINER=`root`@`localhost` PROCEDURE `generate_test_data`(`n` int) begin declare i ...
- MySQL优化概述
一. MySQL优化要点 MySQL优化是一门复杂的综合性技术,主要包括: 1 表的设计合理化(符合 3NF,必要时允许数据冗余) 2.1 SQL语句优化(以查询为主) 2.2 适当添加索引(主键索引 ...
随机推荐
- hadoop 伪分布启动-fs格式化
1.独立模式(standalone|local) nothing! 本地文件系统. 不需要启用单独进程. 2.pesudo(伪分布模式) 等同于完全分布式,只有一个节点. SSH: //(Socket ...
- AX 中临时表应用
临时表,只要让表的Temporary属性设为yes就行. 今天写代码时发现,假如在一个循环里面把数据插入到临时表里, 假如没有在每次开始时没加clear的话,假如有个字段下一条没数据,会自动带到下一条 ...
- 怎样在python中写多行语句
一般来说, 一行就是一条语句, 但有时语句过长不利于阅读, 一般会写成多行的形式, 这时需要在换行时使用反斜杠: \ name = "Lilei" age = 23 gender ...
- hdu 1075 map的使用 字符串截取的常用手段 以及string getline 使用起来的注意事项
首先说字符串的截取套路吧 用坐标一个一个的输入 用遍历的方式逐个去检查字符串中的字符是否为符合的情况 如果是的话 把该字符放入截取string 中 让后坐标前移 如果不是的话 截取结束 坐标初始化 然 ...
- App功能测试点总结
1.手机操作系统android(谷歌).ios(苹果).Windows phone(微软).Symbian(诺基亚).BlackBerry OS(黑莓).windows mobile(微软),目前主流 ...
- JMeter-03-元件的作用域与执行顺序
JMeter元件的作用域与执行顺序 元件的作用域 先来讨论一下元件有作用域.<JMeter基础元件介绍>一节中,我们介绍了8类可被执行的元件(测试计划与线程组不属于元件),这些元件中,取样 ...
- CCF 2017-03-2 学生排队
CCF 2017-03-2 学生排队 题目 问题描述 体育老师小明要将自己班上的学生按顺序排队.他首先让学生按学号从小到大的顺序排成一排,学号小的排在前面,然后进行多次调整.一次调整小明可能让一位同学 ...
- Thread.interrupt()源码跟踪
1 JDK源码跟踪 // java.lang.Thread public void interrupt() { if (this != Thread.currentThread()) checkAcc ...
- AdventureWorks 安装和配置[转自 微软msdn]
AdventureWorks 安装和配置 2018/06/19 适用对象:SQL ServerAzure SQL 数据库Azure SQL 数据仓库并行数据仓库 AdventureWorks 下载链接 ...
- vue.js+DRF跨域访问图片
一.背景 在前后端分离过程时,后端服务器只开放本地接口,而前端则开放IP接口,在DRF响应请求时,会把域名(locahost+port)响应给前端服务器,前端服务器把再把数据响应给浏览器,浏览器在解析 ...