MySQL 优化--持续整理
一、innodb体系结构优化:
1、IO优化
IO能力不足时

innodb_io_capacity 应该降低
innodb_max_dirty_pages_pct 应该降低
innodb_max_dirty_pages_pct_lwm 如果设置了应该考虑降低
innodb_read_io_threads
innodb_write_io_threads
2、Purge Thread
innodb_purge_threads 设置purge线程个数,用于undo页回收
innodb_purge_batch_size 设置Purge undo 的页数量,默认300
innodb_max_purge_lag
控制undo log history list的长度,0表示不对history list 做任何限制。当大于0时,就会
延缓DML的操作。延缓对象是行。
innodb_max_purge_lag_delay 用来控制delay的最大毫秒数。
3、内存池buffer pool
innodb_buffer_pool_size 内存池大小设置
innodb_buffer_pool_instances 多内存池设置
4、LRU List、Free List和Flush List
innodb_old_blocks_pct 设置新页放到LRU List位置 mid位置
innodb_old_blocks_time mid位置后的页,要多久能被加入到LRU列表的热端
5、Redo Log
innodb_log_buffer_size redo buffer 的大小
三种情况刷新日志缓冲
1)master thread 每秒刷
2)事务提交时刷
3)日志空间小于1/2刷
6、Page Cleaner
innodb_io_capacity
合并插入缓冲时,合并的数量为innodb_io_capacity的5%
刷新脏页时,刷新的数量为innodb_io_capacity
innodb_max_dirty_pages_pct
innodb_max_dirty_pages_pct_lwm
innodb_adaptive_flushing 自适应刷新
InnoDB刷新脏页的规则是在如下三种情况下才会把InnoDB_Buffer_Pool的脏页刷入磁盘:
当超过innodb_max_dirty_pages_pct设定的值时。
重做日志ib_logfile文件写满了以后。
机器空闲的时候。
当写操作很频繁的时候,重做日志ib_logfile切换的次数就会很频繁,只要有一个写满了,就会将脏页大批量地刷入磁盘,而这会对系统的整体性能造成不小的影响。为了避免过大的磁盘I/O,innodb_adaptive_flushing会自适应刷新,它使用了一个全新的算法,以便根据重做日志ib_logfile生成的速度和刷新频率来将脏页刷入磁盘,这样重做日志ib_logfile还没有写满时,也可以刷新一定的量。
7、insert buffer(change buffer)
innodb_change_buffering changebuffer 支持的类型 insert、update、delete等
innodb_change_buffer_max_size insert buffer 的大小,占innodb_buffer_pool的百分比(默认25%,最大50%)
8、double write 两次写
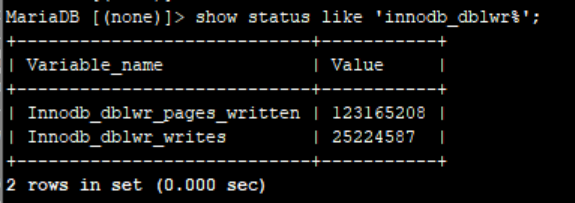
show status like 'innodb_dblwr%';
如果Innodb_dblwr_pages_written:Innodb_dblwr_writes远小于64:1说明系统压力很小
9、自适应哈希索引
10、异步IO(AIO)
innodb_use_native_aio 应打开异步IO
用户发布一个IO请求后,可以立即再发出另一个IO请求,当全部IO请求发送完毕,等待所有
IO操作完成。
AIO还可以进行IO Merge 操作。
11、刷新临近页
innodb_flush_neighbors 根据系统IO能力调整,如果是IO处理能力和高,需要关闭
12、
二、索引优化:
1、打开Multi-Range Read功能(5.6新功能)
它的作用针对基于辅助/第二索引的查询,减少随机IO,并且将随机IO转化为顺序IO,提高查询效率。
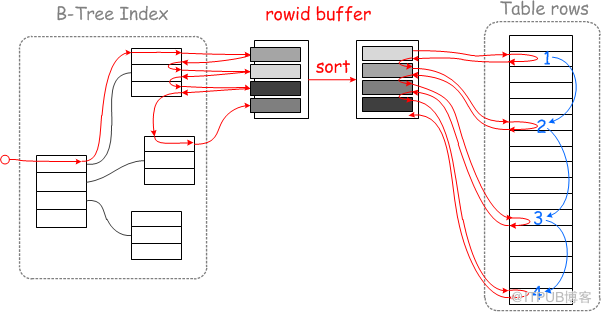
1)打开
set optimizer_switch='mrr=on mrr_cost_based=on'; #mrr_cost_based表示开启mrr后,优化器是否根据cost来决定是否使用mrr
set oprimizer_switch='mrr=off';
2)MRR内存设置
对于MRR,参数read_rnd_buffer_size用来控制键值缓冲区的大小。
2、打开Index Condition Pushdown功能(5.6新功能)
set optimizer_switch = 'index_condition_pushdown=off';
set optimizer_switch = 'index_condition_pushdown=on';
2、Index Condition Pushdown(ICP)


sync_binlog
sync_binlog=1,表示提交一次写一次binlog。
当一个事务发出commit动作之前,由于sync_binlog=1,因此会将二进制日志立即写入磁盘。
如果这时已经写入了二进制日志,但是提交没有发生,并且此事发生了宕机,那么在Mysql
数据库下次启动时,由于commit操作并没有发生,这个事务会被回滚掉。但是,二进制日志
已经记录了该事务信息,不能被回滚。这个问题由参数innodb_support_xa 来解决,
innodb_support_xa= 1 保证二进制日志和InnoDB 存储引擎数据文件同步。
binlog-do-db/binlog-ignore-db
log-slave-update
binlog_format
expire_logs_days
MySQL 优化--持续整理的更多相关文章
- 关于MYSQL优化(持续更新)
*利用MYSQL数据缓存提高效率,注意事项: 1.应用环境:不经常改变的表及对此表相同的查询 2.不适用于服务器端编写的语句 3.根据数据使用频率,合理分解表 4.合理使用默认条件,提高命中率 5.统 ...
- MYSQL优化之碎片整理
MYSQL优化之碎片整理 在MySQL中,我们经常会使用VARCHAR.TEXT.BLOB等可变长度的文本数据类型.不过,当我们使用这些数据类型之后,我们就不得不做一些额外的工作--MySQL数据 ...
- MySQL优化整理
一.SQL优化 1.show status查看各种sql的执行频率 SHOW STATUS 可以根据需要显示 session 级别的统计结果和 global级别的统计结果. 显示当前sessi ...
- 整理的网上的MySQL优化文章总结
MySQL优化 Linux优化 IO优化 调整Linux默认的IO调度算法. IO调度器的总体目标是希望让磁头能够总是往一个方向移动,移动到底了再往反方向走,这恰恰就是现实生活中的电梯模型,所以IO调 ...
- [转] MySql 优化 大数据优化
一.我们可以且应该优化什么? 硬件 操作系统/软件库 SQL服务器(设置和查询) 应用编程接口(API) 应用程序 ------------------------------------------ ...
- mysql优化案例
MySQL优化案例 Mysql5.1大表分区效率测试 Mysql5.1大表分区效率测试MySQL | add at 2009-03-27 12:29:31 by PConline | view:60, ...
- MySQL优化聊两句
原文地址:http://www.cnblogs.com/verrion/p/mysql_optimised.html MySQL优化聊两句 MySQL不多介绍,今天聊两句该如何优化以及从哪些方面入手, ...
- mysql 优化
1.存储过程造数据 CREATE DEFINER=`root`@`localhost` PROCEDURE `generate_test_data`(`n` int) begin declare i ...
- MySQL优化概述
一. MySQL优化要点 MySQL优化是一门复杂的综合性技术,主要包括: 1 表的设计合理化(符合 3NF,必要时允许数据冗余) 2.1 SQL语句优化(以查询为主) 2.2 适当添加索引(主键索引 ...
随机推荐
- WUSTOJ 1323: Repeat Number(Java)规律统计
题目链接:1323: Repeat Number Description Definition: a+b = c, if all the digits of c are same ( c is mor ...
- Scratch编程:绘制七色花(七)
“ 上节课的内容全部掌握了吗?反复练习了没有,编程最好的学习方法就是练习.练习.再练习.一定要记得多动手.多动脑筋哦~~” 01 — 游戏介绍 绘制一朵美丽的七色花. 02 — 设计思路 使用画笔功能 ...
- jquery滚动到顶部
<script> $.fn.scrollTo = function (options) { var defaults = { toT: , //滚动目标位置 durTime: , //过渡 ...
- 在论坛中出现的比较难的sql问题:21(递归问题 检索某个节点下所有叶子节点)
原文:在论坛中出现的比较难的sql问题:21(递归问题 检索某个节点下所有叶子节点) 最近,在论坛中,遇到了不少比较难的sql问题,虽然自己都能解决,但发现过几天后,就记不起来了,也忘记解决的方法了. ...
- Vue+VSCode开发环境搭建
时间2019.9月 1. 安装 nodeJS; 安装VScode 安装好nodeJS之后,默认会安装好npm 测试 nodeJS 和npm是否可以执行 node -v npm -v 1.1 VScod ...
- 用.net4中的DynamicObject实现简单AOP
public class DynamicWrapper : DynamicObject { private readonly object source; public DynamicWrapper( ...
- Ubuntu下编译 Hadoop2.9
Ubuntu 下编译 Hadoop-2.9.2 系统环境 系统: ubuntu-18.10-desktop-amd64 maven: Apache Maven 3.6.0 jdk: jdk_1.8.0 ...
- Vue的学习笔记
以下文章皆为观看慕课网https://www.imooc.com/learn/796中“河畔一角”老师的讲解做的笔记,仅供参考. 一.Vue特点 Vue是MVVM的框架,也就是模型视图->视图模 ...
- 使用httpwebrequest发送http请求
HttpWebRequest request = WebRequest.Create("url") as HttpWebRequest; request.Timeout = * * ...
- S5PV210 timer
TCFG0, R/W, Address = 0xE250_0000 Timer Input Clock Frequency = PCLK / ( {prescaler value + 1} ) / { ...