lucene反向索引——倒排表无论是文档号及词频,还是位置信息,都是以跳跃表的结构存在的
转自:http://www.cnblogs.com/forfuture1978/archive/2010/02/02/1661436.html
4.2. 反向信息
反向信息是索引文件的核心,也即反向索引。
反向索引包括两部分,左面是词典(Term Dictionary),右面是倒排表(Posting List)。
在Lucene中,这两部分是分文件存储的,词典是存储在tii,tis中的,倒排表又包括两部分,一部分是文档号及词频,保存在frq中,一部分是词的位置信息,保存在prx中。
- Term Dictionary (tii, tis)
- –> Frequencies (.frq)
- –> Positions (.prx)
4.2.1. 词典(tis)及词典索引(tii)信息

在词典中,所有的词是按照字典顺序排序的。
- 词典文件(tis)
- TermCount:词典中包含的总的词数
- IndexInterval:为了加快对词的查找速度,也应用类似跳跃表的结构(lucene版本应该比较老!最新的是FST),假设IndexInterval为4,则在词典索引(tii)文件中保存第4个,第8个,第12个词,这样可以加快在词典文件中查找词的速度。
- SkipInterval:倒排表无论是文档号及词频,还是位置信息,都是以跳跃表的结构存在的,SkipInterval是跳跃的步数。
- MaxSkipLevels:跳跃表是多层的,这个值指的是跳跃表的最大层数。
- TermCount个项的数组,每一项代表一个词,对于每一个词,以前缀后缀规则存放词的文本信息(PrefixLength + Suffix),词属于的域的域号(FieldNum),有多少篇文档包含此词(DocFreq),此词的倒排表在frq,prx中的偏移量(FreqDelta, ProxDelta),此词的倒排表的跳跃表在frq中的偏移量(SkipDelta),这里之所以用Delta,是应用差值规则。
- 词典索引文件(tii)
- 词典索引文件是为了加快对词典文件中词的查找速度,保存每隔IndexInterval个词。
- 词典索引文件是会被全部加载到内存中去的。
- IndexTermCount = TermCount / IndexInterval:词典索引文件中包含的词数。
- IndexInterval同词典文件中的IndexInterval。
- SkipInterval同词典文件中的SkipInterval。
- MaxSkipLevels同词典文件中的MaxSkipLevels。
- IndexTermCount个项的数组,每一项代表一个词,每一项包括两部分,第一部分是词本身(TermInfo),第二部分是在词典文件中的偏移量(IndexDelta)。假设IndexInterval为4,此数组中保存第4个,第8个,第12个词。。。
- 4.2.2. 文档号及词频(frq)信息

文档号及词频文件里面保存的是倒排表,是以跳跃表形式存在的。
- 此文件包含TermCount个项,每一个词都有一项,因为每一个词都有自己的倒排表。
- 对于每一个词的倒排表都包括两部分,一部分是倒排表本身,也即一个数组的文档号及词频,另一部分是跳跃表,为了更快的访问和定位倒排表中文档号及词频的位置。
- 对于文档号和词频的存储应用的是差值规则和或然跟随规则,Lucene的文档本身有以下几句话,比较难以理解,在此解释一下:
|
xxx |
- 对于跳跃表的存储有以下几点需要解释一下:
- 跳跃表可根据倒排表本身的长度(DocFreq)和跳跃的幅度(SkipInterval)而分不同的层次,层次数为NumSkipLevels = Min(MaxSkipLevels, floor(log(DocFreq/log(SkipInterval)))).
- 第Level层的节点数为DocFreq/(SkipInterval^(Level + 1)),level从零计数。
- 除了最低层之外,其他层都有SkipLevelLength来表示此层的二进制长度(而非节点的个数),方便读取某一层的跳跃表到缓存里面。
- 高层在前,低层在后,当读完所有的高层后,剩下的就是最低一层,因而最后一层不需要SkipLevelLength。这也是为什么Lucene文档中的格式描述为 NumSkipLevels-1, SkipLevel,也即低NumSKipLevels-1层有SkipLevelLength,最后一层只有SkipLevel,没有SkipLevelLength。
- 除最低层以外,其他层都有SkipChildLevelPointer来指向下一层相应的节点。
- 每一个跳跃节点包含以下信息:文档号,payload的长度,文档号对应的倒排表中的节点在frq中的偏移量,文档号对应的倒排表中的节点在prx中的偏移量。
- 虽然Lucene的文档中有以下的描述,然而实验的结果却不是完全准确的:
|
Example: SkipInterval = 4, MaxSkipLevels = 2, DocFreq = 35. Then skip level 0 has 8 SkipData entries, containing the 3rd, 7th, 11th, 15th, 19th, 23rd, 27th, and 31st document numbers in TermFreqs. Skip level 1 has 2 SkipData entries, containing the 15th and 31st document numbers in TermFreqs. 按照描述,当SkipInterval为4,且有35篇文档的时候,Skip level = 0应该包括第3,第7,第11,第15,第19,第23,第27,第31篇文档,Skip level = 1应该包括第15,第31篇文档。 然而真正的实现中,跳跃表节点的时候,却向前偏移了,偏移的原因在于下面的代码:
从代码中,我们可以看出,当SkipInterval为4的时候,当docID = 0时,++df为1,1%4不为0,不是跳跃节点,当docID = 3时,++df=4,4%4为0,为跳跃节点,然而skipData里面保存的却是lastDocID为2。 所以真正的倒排表和跳跃表中保存一下的信息:
|

4.2.3. 词位置(prx)信息

词位置信息也是倒排表,也是以跳跃表形式存在的。
- 此文件包含TermCount个项,每一个词都有一项,因为每一个词都有自己的词位置倒排表。
- 对于每一个词的都有一个DocFreq大小的数组,每项代表一篇文档,记录此文档中此词出现的位置。这个文档数组也是和frq文件中的跳跃表有关系的,从上面我们知道,在frq的跳跃表节点中有ProxSkip,当SkipInterval为3的时候,frq的跳跃表节点指向prx文件中的此数组中的第1,第4,第7,第10,第13,第16篇文档。
- 对于每一篇文档,可能包含一个词多次,因而有一个Freq大小的数组,每一项代表此词在此文档中出现一次,则有一个位置信息。
- 每一个位置信息包含:PositionDelta(采用差值规则),还可以保存payload,应用或然跟随规则。
五、总体结构
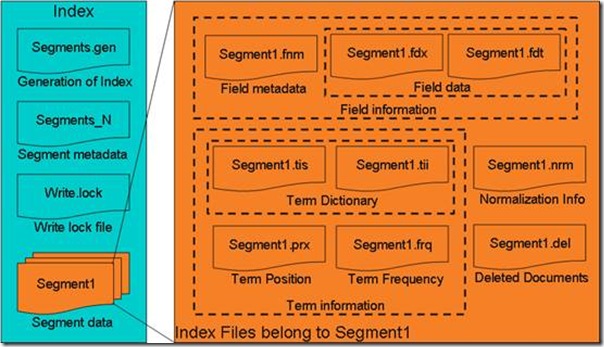
- 图示为Lucene索引文件的整体结构:
- 属于整个索引(Index)的segment.gen,segment_N,其保存的是段(segment)的元数据信息,然后分多个segment保存数据信息,同一个segment有相同的前缀文件名。
- 对于每一个段,包含域信息,词信息,以及其他信息(标准化因子,删除文档)
- 域信息也包括域的元数据信息,在fnm中,域的数据信息,在fdx,fdt中。
- 词信息是反向信息,包括词典(tis, tii),文档号及词频倒排表(frq),词位置倒排表(prx)。
大家可以通过看源代码,相应的Reader和Writer来了解文件结构,将更为透彻。
lucene反向索引——倒排表无论是文档号及词频,还是位置信息,都是以跳跃表的结构存在的的更多相关文章
- lucene正向索引(续)——一个文档的所有filed+value都在fdt文件中!!!
4.1.3. 域(Field)的数据信息(.fdt,.fdx) 域数据文件(fdt): 真正保存存储域(stored field)信息的是fdt文件 在一个段(segment)中总共有segment ...
- Lucene学习总结之三:Lucene的索引文件格式(1)
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene学习之四:Lucene的索引文件格式(3)
本文转载自:http://www.cnblogs.com/forfuture1978/archive/2010/02/02/1661436.html ,略有删改和备注. 四.具体格式 4.2. 反向信 ...
- Lucene学习总结之三:Lucene的索引文件格式(1) 2014-06-25 14:15 1124人阅读 评论(0) 收藏
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- lucene学习笔记:三,Lucene的索引文件格式
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene系列-索引文件
本文介绍下lucene生成的索引有哪些文件组成,每个文件包含了什么信息.基于Lucene 4.10.0. 数据结构 索引(index)包含了存储的文档(document)正排.倒排信息,用于文本搜索. ...
- redis 系列7 数据结构之跳跃表
一.概述 跳跃表(skiplist)是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的.在大部分情况下,跳跃表的效率可以和平衡树(关系型数据库的索引就是平衡树 ...
- Redis实现之字典跳跃表
跳跃表 跳跃表是一种有序数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的.跳跃表支持平均O(logN).最坏O(N)的时间复杂度查找,还可以通过顺序性操作来批量处理节 ...
- 图解Redis之数据结构篇——跳跃表
前言 跳跃表是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的.这么说,我们可能很难理解,我们可以先回忆一下链表. 一.复习跳跃表 1.1 什么 ...
随机推荐
- 使用Django时需要注意的八个要点
1.在settings.py中使用os. path.dirname() 常用代码如下: # settings.py import os PROJECT_DIR = os.path.dirname(__ ...
- S3C2440 OpenJtag
C:\Users\Administrator\Desktop>oflash.exe leds.bin +--------------------------------------------- ...
- Linux Centos7 网络设置UUID号的修改方法
1.生成一个UUID [root@localhost ~]# uuidgen ens33 223bdb47-2fed-4773-b984-5f5733e61904 2.UUID号写入网络配置文件ifc ...
- shell 函数的高级用法
函数介绍 linux shell中的函数和大多数编程语言中的函数一样 将相似的任务或者代码封装到函数中,供其他地方调用 语法格式 如何调用函数 shell终端中定义函数 [root@master da ...
- Centos7.x固定网络IP配置
1.管理员帐号密码登录centos系统 2. cd/etc/sysconfig/network-script/ 3. ls查看 4.vi 编辑 ifcfg-ens33(不同服务器网卡名 ...
- git命令——git log
功能 在提交了若干更新,又或者克隆了某个项目之后,你也许想回顾下提交历史. 完成这个任务最简单而又有效的方法是 使用git log 命令. 参数 不带任何参数 $ git log commit ca8 ...
- python生成器学习
python生成器学习: 案例分析一: def demo(): for i in range(4): yield i g=demo() g1=(i for i in g) #(i for i in d ...
- clamscan-Linux查毒工具
转载:https://www.cnblogs.com/tdcqma/p/7576183.html clamscan命令用于扫描文件和目录,一发现其中包含的计算机病毒,clamscan命令除了扫描lin ...
- DateTime函数
一.初始化: DateTime dt = , , ); DateTime dt1 = DateTime.Now; DateTime dt2 = DateTime.Today; DateTime dt3 ...
- mysqlcheck(MyISAM表维护工具)
mysqlheck [option] db_name [tables] -c --check(检查表) -r --repair(修复表) -a --analyze(分析表) -o --optim ...