01_Hive简介及其工作机制
1.Hive简介
Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一个表。并提供类SQL查询功能,
可以将sql语句转换为MapReduce任务运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce
统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
2.数据仓库(面向主题、历史):
数据库是用来支撑在线联机业务的。如页面上数据的展示,保存客户操作产生的数据。这类要求变更是实时的、
事务的。
数据仓库:如果联机数据库中的数据太大了,需要将历史信息导入到离线的仓库中。数据仓库中可以存入各种
业务系统的数据,并按照一定主题来组织这些数据表。数据仓库中的数据一般用来做统计,数据分析。比如统计年
度销售额,月度销售额,广告推荐等,简而言之,数据仓库是用来做查询分析的数据库,基本不用来做插入,修改,
删除。
3.Hive的工作机制:
将清洗过的数据放入到HDFS中,就可进行各种统计了。但有些需求用MapReduce写起来非常难,所以有了Hive;
Hive运行时,元数据信息存储在关系型数据库里面,如mysql、derby。Hive中的元数据包括表的名字,表的列和
分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会
生成MapRedcue任务)
4.Hive和Hadoop的关系:
Hive利用HDFS存储数据,利用MapReduce查询数据
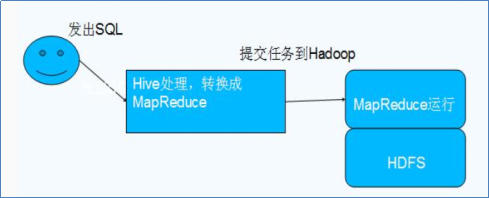
5.Hive的数据存储:
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:与table类似,不过其数据存放位置可以在任意指定路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
01_Hive简介及其工作机制的更多相关文章
- AsyncTask工作机制简介
昨天写的图片的三级缓存,假设有兴趣,能够去看下,浅谈图片载入的三级缓存原理(一) http://blog.csdn.net/wuyinlei/article/details/50606455 在里面我 ...
- GVRP 的工作机制和工作模式
GVRP 简介 GVRP 基于 GARP 的工作机制来维护设备中的 VLAN 动态注册信息,并将该信息向其他设备传播:当设备启动了 GVRP 之后,就能够接收来自其他设备的 VLAN 注册信息,并动态 ...
- keepalived之 Keepalived 原理(定义、VRRP 协议、VRRP 工作机制)
1.Keepalived 定义 Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障.一个LVS服务会有2台服务器运行Keepalived,一台为主服务器 ...
- Spring学习记录2——简单了解Spring容器工作机制
简单的了解Spring容器内部工作机制 Spring的AbstractApplicationContext是ApplicationContext的抽象实现类,该抽象类的refresh()方法定义了Sp ...
- android 6.0 高通平台sensor 工作机制及流程(原创)
最近工作上有碰到sensor的相关问题,正好分析下其流程作个笔记. 这个笔记分三个部分: sensor硬件和驱动的工作机制 sensor 上层app如何使用 从驱动到上层app这中间的流程是如何 Se ...
- Java IO工作机制分析
Java的IO类都在java.io包下,这些类大致可分为以下4种: 基于字节操作的 I/O 接口:InputStream 和 OutputStream 基于字符操作的 I/O 接口:Writer 和 ...
- malloc 函数工作机制(转)
malloc()工作机制 malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表.调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块.然后,将 ...
- springMVC工作机制和框架搭建配置说明
先说一下springMVC的工作机制 1.springmvc把 所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责对请求进行真正的处理工作. 2.Dispatcher ...
- CKPT进程工作机制
CKPT进程工作示意图 2.CKPT进程工作机制 检查点进程被触发的条件为: a> 当发生日志组切换时: b> 用户提交了事务时(commit): c> Redo log buf ...
随机推荐
- Spring Aop(八)——advisor标签
转发地址:https://www.iteye.com/blog/elim-2396274 8 advisor标签 advisor标签是需要定义在aspect标签里面的,其作用与aspect类似,可以简 ...
- EasyNetQ使用(三)【Publish与Subcribe】
EasyNetQ支持的最简单的消息模式是发布/订阅.这个模式是一个极好的方法用来解耦消息提供者和消费者.消息发布者只要简单的对世界说,“这里有些事发生” 或者 “我现在有一个信息”.它不关心有没有人监 ...
- .NET(C#):判断Type类的继承关系
//Type类的函数 class Type bool IsInstanceOfType(object); //判断对象是否是指定类型 //类型可以是父类,接口 //用法:父类.IsInstanceOf ...
- 【Python】机器学习之单变量线性回归 利用正规方程找到合适的参数值
[Python]机器学习之单变量线性回归 利用正规方程找到合适的参数值 本次作业来自吴恩达机器学习. 你是一个餐厅的老板,你想在其他城市开分店,所以你得到了一些数据(数据在本文最下方),数据中包括不同 ...
- 在java web 工程中实现登录和安全验证
登录验证代码 package security; import java.io.IOException; import javax.servlet.ServletException; import j ...
- mongodb的安装部署-备份
1.安装部署 wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.4.10.tgz tar -zxf mongodb-linux- ...
- [转帖CCIX]
业界七巨头联手,数据中心通过PCIe实现25Gbps数据通信! 2017-06-07 17:31 CCIX(Cache Coherent Interconnect for Accelerators,针 ...
- Spring 加载项目外部配置文件
背景 在项目的部署过程中,一般是打成 war 或者 jar 包,这样一般存在两种问题: 即使是配置文件修改,也还需要整个项目重新打包和部署. 整个项目只有一套环境,不能切换. 针对上面的问题,可以使用 ...
- Linux系列(13)之程序与服务的概念
知道如何区分程序与进程吗? 知道如何产生进程吗? 知道进程之间的相关性吗? 知道进程调用的流程吗? 知道进程与服务的区别吗? 1.程序与进程的区别 bash就是一个程序,当我们登录之后系统就会给我们分 ...
- 【搜索】n的约数
题目链接:传送门 [题解]: 考察dfs和质因数分解,首先开一个prime数组. 参数解释: 1.当前值的大小.[利用题目的n来控制范围] 2.控制下界,每次都是以某一个质数开始搜索, pos 3.控 ...