01_Hive简介及其工作机制
1.Hive简介
Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一个表。并提供类SQL查询功能,
可以将sql语句转换为MapReduce任务运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce
统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析
2.数据仓库(面向主题、历史):
数据库是用来支撑在线联机业务的。如页面上数据的展示,保存客户操作产生的数据。这类要求变更是实时的、
事务的。
数据仓库:如果联机数据库中的数据太大了,需要将历史信息导入到离线的仓库中。数据仓库中可以存入各种
业务系统的数据,并按照一定主题来组织这些数据表。数据仓库中的数据一般用来做统计,数据分析。比如统计年
度销售额,月度销售额,广告推荐等,简而言之,数据仓库是用来做查询分析的数据库,基本不用来做插入,修改,
删除。
3.Hive的工作机制:
将清洗过的数据放入到HDFS中,就可进行各种统计了。但有些需求用MapReduce写起来非常难,所以有了Hive;
Hive运行时,元数据信息存储在关系型数据库里面,如mysql、derby。Hive中的元数据包括表的名字,表的列和
分区及其属性,表的属性(是否为外部表等),表的数据所在目录等;
Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会
生成MapRedcue任务)
4.Hive和Hadoop的关系:
Hive利用HDFS存储数据,利用MapReduce查询数据
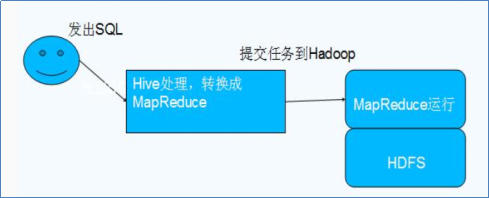
5.Hive的数据存储:
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:与table类似,不过其数据存放位置可以在任意指定路径
partition:在hdfs中表现为table目录下的子目录
bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
01_Hive简介及其工作机制的更多相关文章
- AsyncTask工作机制简介
昨天写的图片的三级缓存,假设有兴趣,能够去看下,浅谈图片载入的三级缓存原理(一) http://blog.csdn.net/wuyinlei/article/details/50606455 在里面我 ...
- GVRP 的工作机制和工作模式
GVRP 简介 GVRP 基于 GARP 的工作机制来维护设备中的 VLAN 动态注册信息,并将该信息向其他设备传播:当设备启动了 GVRP 之后,就能够接收来自其他设备的 VLAN 注册信息,并动态 ...
- keepalived之 Keepalived 原理(定义、VRRP 协议、VRRP 工作机制)
1.Keepalived 定义 Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障.一个LVS服务会有2台服务器运行Keepalived,一台为主服务器 ...
- Spring学习记录2——简单了解Spring容器工作机制
简单的了解Spring容器内部工作机制 Spring的AbstractApplicationContext是ApplicationContext的抽象实现类,该抽象类的refresh()方法定义了Sp ...
- android 6.0 高通平台sensor 工作机制及流程(原创)
最近工作上有碰到sensor的相关问题,正好分析下其流程作个笔记. 这个笔记分三个部分: sensor硬件和驱动的工作机制 sensor 上层app如何使用 从驱动到上层app这中间的流程是如何 Se ...
- Java IO工作机制分析
Java的IO类都在java.io包下,这些类大致可分为以下4种: 基于字节操作的 I/O 接口:InputStream 和 OutputStream 基于字符操作的 I/O 接口:Writer 和 ...
- malloc 函数工作机制(转)
malloc()工作机制 malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表.调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块.然后,将 ...
- springMVC工作机制和框架搭建配置说明
先说一下springMVC的工作机制 1.springmvc把 所有的请求都提交给DispatcherServlet,它会委托应用系统的其他模块负责对请求进行真正的处理工作. 2.Dispatcher ...
- CKPT进程工作机制
CKPT进程工作示意图 2.CKPT进程工作机制 检查点进程被触发的条件为: a> 当发生日志组切换时: b> 用户提交了事务时(commit): c> Redo log buf ...
随机推荐
- PHP中include、require、include_once、require_once的区别
include:使用include引用外部文件时,只有代码执行到include代码段时,调用的外部文件才会被引用并读取,当引用的文件发生错误时,系统只会给出个警告错误,而整个php文件会继续执行.re ...
- 用cmd命令加密文件夹
比如新建一个叫“大学财务”的文件夹,我希望这个文件夹下的内容是加密隐藏的. 查看的时候需要点击“大学财务.bat”这个文件,然后输入设置的密码即可. Cls @ECHO OFF title Folde ...
- 文件input框选择图片实时显示小技巧
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- codevs 1200:同余方程
题目描述 Description 求关于 x 同余方程 ax ≡ 1 (mod b)的最小正整数解. 输入描述 Input Description 输入只有一行,包含两个正整数 a, b,用 一个 空 ...
- [转帖] 修改nginx 默认上传文件大小
nginx默认会限制上传文件的大小为1M https://blog.51cto.com/ycgit/1563307 艺晨光关注0人评论12037人阅读2014-10-13 15:29:50 htt ...
- 关于keepalived执行后日志狂刷IPVS: Can't initialize ipvs: Protocol not available的问题
安装了keepalived+lvs,达到了高可用的负载均衡,但是今天再启用的时候发现keepalived不正常,通过 /var/log/messages 查看系统日志发现狂刷 IPVS: Can't ...
- WinForm打包
首先要在想要打包的项目下创建一个新的项目, 创建好setup项目,之后点击属性,去修改打包软件的名字,ProductName....可以选填 到此已经创建好了setup工程了,那么下面开始将要打包的d ...
- 剑指offer43:左旋转字符串(字符串):对于一个给定的字符序列S,请你把其循环左移K位后的序列输出。
1 题目描述 汇编语言中有一种移位指令叫做循环左移(ROL),现在有个简单的任务,就是用字符串模拟这个指令的运算结果.对于一个给定的字符序列S,请你把其循环左移K位后的序列输出.例如,字符序列S=”a ...
- 请写一段 PHP 代码 ,确保多个进程同时写入同一个文件成功
方案一: function writeData($filepath, $data) { $fp = fopen($filepath,'a'); do{ usleep(100); }while (!fl ...
- 基础python规范
一.注释 合理的代码注释应该占源代码的 1/3 左右,Python 语言允许在任何地方插入空字符或注释,但不能插入到标识符和字符串中间. 在 Python 中,通常包括 3 种类型的注 ...