MySQL优化:如何避免回表查询?什么是索引覆盖? (转)
数据库表结构:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
select id,name where name='shenjian' select id,name,sex where name='shenjian'
多查询了一个属性,为何检索过程完全不同?
什么是回表查询?
什么是索引覆盖?
如何实现索引覆盖?
哪些场景,可以利用索引覆盖来优化SQL?
这些,这是今天要分享的内容。
画外音:本文试验基于MySQL5.6-InnoDB。
一、什么是回表查询?
这先要从InnoDB的索引实现说起,InnoDB有两大类索引:
聚集索引(clustered index)
普通索引(secondary index)
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义了PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
画外音:所以PK查询非常快,直接定位行记录。
InnoDB普通索引的叶子节点存储主键值。
画外音:注意,不是存储行记录头指针,MyISAM的索引叶子节点存储记录指针。
举个栗子,不妨设有表:
t(id PK, name KEY, sex, flag);
画外音:id是聚集索引,name是普通索引。
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B

两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。
例如:
select * from t where name='lisi';
是如何执行的呢?
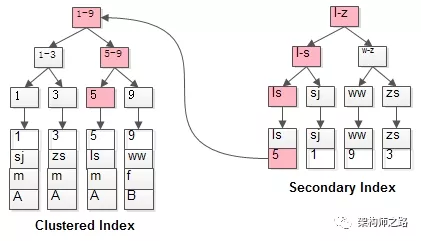
如粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
二、什么是索引覆盖(Covering index)?
额,楼主并没有在MySQL的官网找到这个概念。
画外音:治学严谨吧?
借用一下SQL-Server官网的说法。

MySQL官网,类似的说法出现在explain查询计划优化章节,即explain的输出结果Extra字段为Using index时,能够触发索引覆盖。

不管是SQL-Server官网,还是MySQL官网,都表达了:只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快。
三、如何实现索引覆盖?
常见的方法是:将被查询的字段,建立到联合索引里去。
仍是之前中的例子:
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name)
)engine=innodb;
第一个SQL语句:
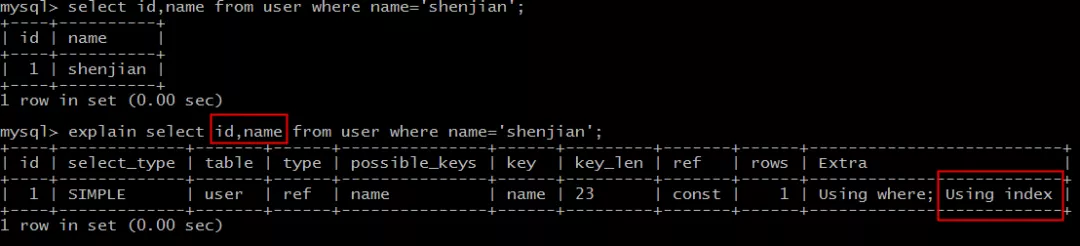
select id,name from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
画外音,Extra:Using index。
第二个SQL语句:
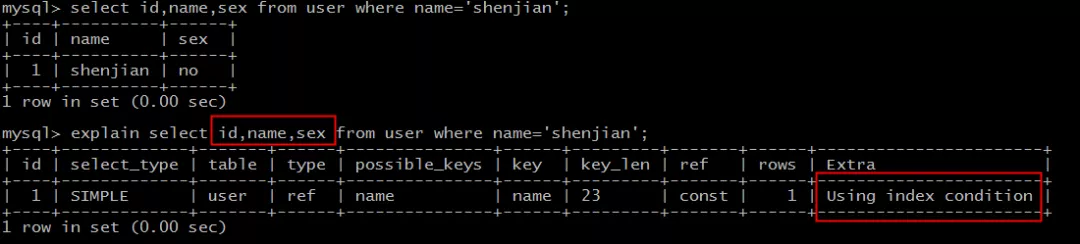
select id,name,sex from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
画外音,Extra:Using index condition。
如果把(name)单列索引升级为联合索引(name, sex)就不同了。
create table user (
id int primary key,
name varchar(20),
sex varchar(5),
index(name, sex)
)engine=innodb;
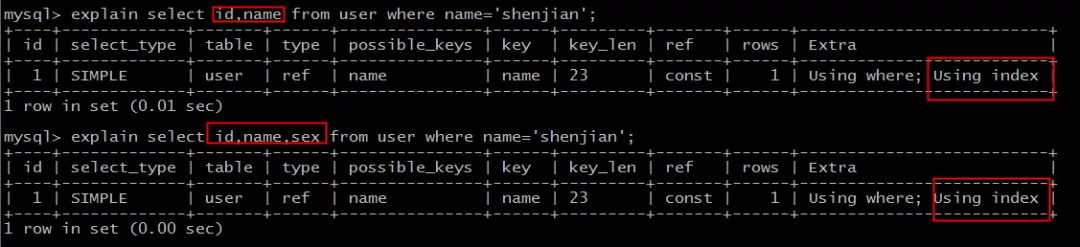
可以看到:
select id,name ... where name='shenjian'; select id,name,sex ... where name='shenjian';
都能够命中索引覆盖,无需回表。
画外音,Extra:Using index。
四、哪些场景可以利用索引覆盖来优化SQL?
场景1:全表count查询优化
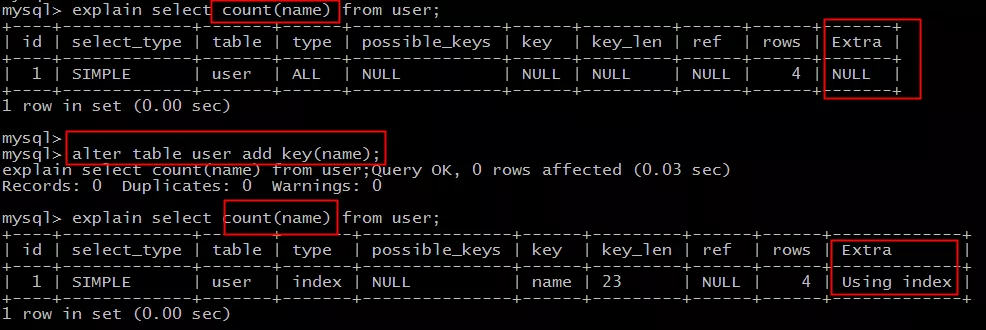
原表为:
user(PK id, name, sex);
直接:
select count(name) from user;
不能利用索引覆盖。
添加索引:
alter table user add key(name);
就能够利用索引覆盖提效。
场景2:列查询回表优化
select id,name,sex ... where name='shenjian';
这个例子不再赘述,将单列索引(name)升级为联合索引(name, sex),即可避免回表。
场景3:分页查询
select id,name,sex ... order by name limit 500,100;
将单列索引(name)升级为联合索引(name, sex),也可以避免回表。
InnoDB聚集索引普通索引,回表,索引覆盖
MySQL优化:如何避免回表查询?什么是索引覆盖? (转)的更多相关文章
- MySQL 回表查询 & 索引覆盖优化
回表查询 先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据 建表示例 mysql> create table user( -> id int(10) auto_incre ...
- mysql中的回表查询与索引覆盖
了解一下MySQL中的回表查询与索引覆盖. 回表查询 要说回表查询,先要从InnoDB的索引实现说起.InnoDB有两大类索引,一类是聚集索引(Clustered Index),一类是普通索引(Sec ...
- (MYSQL)回表查询原理,利用联合索引实现索引覆盖
一.什么是回表查询? 这先要从InnoDB的索引实现说起,InnoDB有两大类索引: 聚集索引(clustered index) 普通索引(secondary index) InnoDB聚集索引和普通 ...
- MySQL回表查询
一.MySQL索引类型 1.普通索引:最基本的索引,没有任何限制 2.唯一索引(unique index):索引列的值必须唯一,但是允许为空 3.主键索引:特殊的唯一索引,但是不允许为空,一般在建表的 ...
- 你的 SQL 还在回表查询吗?快给它安排覆盖索引
什么是回表查询 小伙伴们可以先看这篇文章了解下什么是聚集索引和辅助索引:Are You OK?主键.聚集索引.辅助索引,简单回顾下,聚集索引的叶子节点包含完整的行数据,而非聚集索引的叶子节点存储的是每 ...
- MySQL/MariaDB数据库的多表查询操作
MySQL/MariaDB数据库的多表查询操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.单表查询小试牛刀 [root@node105.yinzhengjie.org.cn ...
- mysql四-1:单表查询
一.单表查询的语法 SELECT 字段1,字段2... FROM 表名 WHERE 条件 GROUP BY field HAVING 筛选 ORDER BY field LIMIT 限制条数 二.关键 ...
- 6.MySQL优化---高级进阶之表的设计及优化
转自互联网整理. 优化之路高级进阶——表的设计及优化 优化①:创建规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询需要.避免数据库操作异常的数据库设计方式.满足范式要求的表,称为规 ...
- MySql(七)多表查询
十一.多表查询 新建两张表:部门表(department).员工表(employee) create table department( id int, name varchar(20) ); cre ...
随机推荐
- Asp.Net Core 轻松学系列-3项目目录和文件作用介绍
目录 前言 结语 前言 上一章介绍了 Asp.Net Core 的前世今生,并创建了一个控制台项目编译并运行成功,本章的内容介绍 .NETCore 的各种常用命令.Asp.Net Core M ...
- springboot启动流程(一)构造SpringApplication实例对象
所有文章 https://www.cnblogs.com/lay2017/p/11478237.html 启动入口 本文是springboot启动流程的第一篇,涉及的内容是SpringApplicat ...
- python处理RSTP视频流
python链接海康摄像头,并以弹出框的方式播放实时视频流, 这种方式是以弹出框的形式播放.本地测试可以,实际业务场景不建议使用.可以采用rtsp转rtmp的方式 @shared_task def p ...
- 5.Redis的持久化
Redis中数据的持久化有两种方式:RDB(Redis DataBsse) 和 AOF(Append Only File),默认采取的是RDB方式 RDB 1.是什么:在指定的时间间隔内将内存中的数据 ...
- [LeetCode] 15. 3Sum ☆☆☆(3数和为0)
描述 Given an array nums of n integers, are there elements a, b, c in nums such that a + b + c = 0? Fi ...
- jmeter连接mysql数据库批量插入数据
前提工作: 1.在jmeter官网下载jmeter包(官网地址:https://jmeter.apache.org/).此外还需下载mysql驱动包,如:mysql-connector-java-5. ...
- window.onload 和doucument.ready执行顺序
浏览器渲染时 首先解析DOM结构 (同时在发送请求 去请求其他资源 比如图片 视频 等 ) DOM结构解析完毕 这个时候jQuery看准时机在这里添加了监听 所以Ready方法执行很早,可能会引起其他 ...
- elasticsearch + kibana + x-pack + logstash_集群部署安装
elasticsearch 部分总体描述: 1.elasticsearch 的概念及特点.概念:elasticsearch 是一个基于 lucene 的搜索服务器.lucene 是全文搜索的一个框架. ...
- ARP、Proxy ARP、Gratuitous ARP
Proxy ARP 什么是Proxy ARP? 一个主机A(通常是路由器)有意应答另一个主机B的ARP请求(ARP requests).主机A通过伪装其身份,承担起将分组路由到真实目的地的责任.代理A ...
- nginx精准反向代理
1,完全反向代理,将请求10.130.111.110服务器的请求全部转发到10.130.111.111服务器 location / { proxy_pass http://10.130.111.111 ...