自然语言处理工具HanLP-N最短路径分词
本篇给大家分享baiziyu 写的HanLP 中的N-最短路径分词。以为下分享的原文,部分地方有稍作修改,内容仅供大家学习交流!
首先说明在HanLP对外提供的接口中没有使用N-最短路径分词器的,作者在官网中写到这个分词器对于实体识别来说会比最短路径分词稍好,但是它的速度会很慢。对此我有点个人看法,N-最短路径分词相较于最短路径分词来说只是考虑了每个节点下的N种最佳路径,在最后选出的至少N条路径中,作者并没有对他们进行筛选,而只是选择了一条最优的路径,只能说N-最短路径分词相较于最短路径分词对分词歧义会有一定作用,而对于未登录词它的效果应该和最短路径分词相差不多,这只是个人的猜测,并没有拿真实的语料验证。如果后边还有时间的话,我会把几种分词器在新闻语料上做一次对比评测。但是这种评测的意义可能不大,因为毕竟领域不同分词器的效果也会不同,同文本分类一样,至今依然没有一种普适的分词器。
前边已经提到,在最短路径分词中,若每个结点处记录N种最短路径值,则该方法称为N-最短路径算法。在HanLP中通过两个类ViterbiSegment和NshortSegment分别实现了最短路径分词和N-最短路径分词。这里要说明一下为什么说是N种而不是N个,原因是算法会在每个字节点处对所有到达该节点的路径计算路径值,然后按照路径值做排序,所谓的“种”指的是路径值的种类数,因此当存在相等路径值的路径时,节点处保留的路径就不只有N个了。
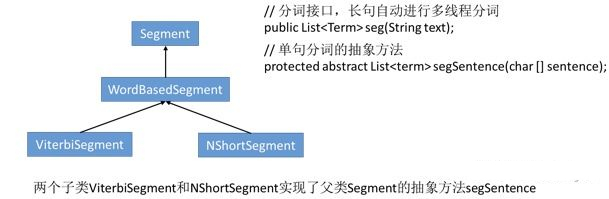
从上图的继承关系我们可以看到最短路径分词器和N最短路径分词器都继承了WordBasedSegment抽象类,也就是说他们从大类上讲都属于基于词语的分词器。后边我们还会介绍基于词典的分词器(极速词典分词器)以及基于字的分词器(感知机、条件随机场分词器)。这里再说明一下抽象类Segment它对外提供了分词方法Seg,所有HanLP中实现的分词方法类都继承了该抽象类,并且实现了抽象方法segSentence。Seg方法对输入的文本进行处理,当文本长度很长时,它会自动将其拆分为多个短文本,然后利用多线程技术,同步对多个短文本进行分词处理,最后得到分词后的文本,对于短文本Seg方法则直接用单线程处理。segSentence则会根据各种不同的分词方法对文本进行分词。这里Seg方法会调用segSentence方法,这就是两个方法的关系。拿我们现在的N-最短路径分词来说,segSentence实现的就是N-最短路径分词。如果是最短路径分词,则segSentence实现的是最短路径分词。写这些只是为了使刚接触面向对象编程方法的小伙伴能清楚。
下边我们还是以例句“他说的确实在理”为例来说明N-最短路径分词。程序对外表现就是计算出下边的表
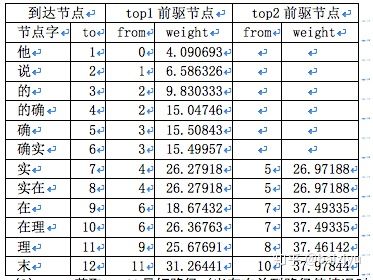
这里我们使N-最短路径分词中的N取2,可以看到算法从“实”字开始就开始有多种最优路径了,截取了前top2种,最后得到了下边的两种分词结果

至此,我们N-最短路径分词介绍结束,我们再来总结一下HanLP中两种方法的异同。
(1) 第1个区别是节点上保留的最优路径前驱节点数。具体来说,当某个节点存在两个以上前驱时,N-最短路径一定会保留topN种路径值的所有前驱节点,而最短路径只会保留一个最短路径值的前驱节点。
(2) HanLP在实现上对N-最短路径方法增加了数字、日期合并规则。
(3) HanLP的N-最短路径方法最终返回的还是一个最优路径,并未对topN个分词结果做筛选策略,虽然在有多个前驱的节点处保留了多个候选前驱,但是个人感觉两者相差应该不多,可能对分词歧义有效果,但是对未登录词应该作用不大。说白了它也还是基于词典中单个词语的概率做的,其他的文本信息都没有用到。
这里,还要再说明一下,我们看到了分词结果中含有了词性标注,关于词性标注我们会在后边继续介绍,它与分词方法是两个策略。程序也是先做了分词再根据用户配置做的词性标注。
自然语言处理工具HanLP-N最短路径分词的更多相关文章
- Python中调用自然语言处理工具HanLP手记
手记实用系列文章: 1 结巴分词和自然语言处理HanLP处理手记 2 Python中文语料批量预处理手记 3 自然语言处理手记 4 Python中调用自然语言处理工具HanLP手记 5 Python中 ...
- 中文自然语言处理工具HanLP源码包的下载使用记录
中文自然语言处理工具HanLP源码包的下载使用记录 这篇文章主要分享的是hanlp自然语言处理源码的下载,数据集的下载,以及将让源代码中的demo能够跑通.Hanlp安装包的下载以及安装其实之前就已经 ...
- 开源自然语言处理工具包hanlp中CRF分词实现详解
CRF简介 CRF是序列标注场景中常用的模型,比HMM能利用更多的特征,比MEMM更能抵抗标记偏置的问题. [gerative-discriminative.png] CRF训练 这类耗时的任务,还 ...
- 中文自然语言处理工具hanlp隐马角色标注详解
本文旨在介绍如何利用HanLP训练分词模型,包括语料格式.语料预处理.训练接口.输出格式等. 目前HanLP内置的训练接口是针对一阶HMM-NGram设计的,另外附带了通用的语料加载工具,可以通过少量 ...
- 自然语言处理工具HanLP被收录中国大数据产业发展的创新技术新书《数据之翼》
在12月20日由中国电子信息产业发展研究院主办的2018中国软件大会上,大快搜索获评“2018中国大数据基础软件领域领军企业”,并成功入选中国数字化转型TOP100服务商. 图:大快搜索获评“2018 ...
- 自然语言处理工具hanlp 1.7.3版本更新内容一览
HanLP 1.7.3 发布了.HanLP 是由一系列模型与算法组成的 Java 工具包,目标是普及自然语言处理在生产环境中的应用.HanLP 具备功能完善.性能高效.架构清晰.语料时新.可自定义的特 ...
- 自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下! TextRank是在Google的PageRan ...
- 自然语言处理工具hanlp自定义词汇添加图解
过程分析 1.添加新词需要确定无缓存文件,否则无法使用成功,因为词典会优先加载缓存文件 2.再确认缓存文件不在时,打开本地词典按照格式添加自定义词汇. 3.调用分词函数重新生成缓存文件,这时会报一个找 ...
- 自然语言处理工具hanlp定制用户词条
作者:baiziyu 关于hanlp的文章已经分享过很多,似乎好像大部分以理论性的居多.最近有在整理一些hanlp应用项目中的文章,待整理完成后会陆续分享出来.本篇分享的依然是由baiziyu 分享的 ...
- 自然语言分析工具Hanlp依存文法分析python使用总结(附带依存关系英文简写的中文解释)
最近在做一个应用依存文法分析来提取文本中各种关系的词语的任务.例如:text=‘新中国在马克思的思想和恩格斯的理论阔步向前’: 我需要提取这个text中的并列的两个关系,从文中分析可知,“马克思的思想 ...
随机推荐
- 给PS添加ICO格式文件
为什么你的ps不能直接打开favicon.ico文件呢?因为你没有安装识别ico的格式插件. 安装步骤如下: 下载格式文件:https://pan.baidu.com/s/1lE0El1VtDqD5l ...
- BZOJ 3782: 上学路 Lucas+ExCRT+容斥+dp
其实呢,扩展中国剩余定理还有一种理解方式:就是你有一坨东西,形如:$A[i]\equiv B[i](mod$ $P[i])$. 对于这个东西,你可以这么思考:如果最后能求出一个解,那么这个解的增量一定 ...
- 交换机配置——VTP管理交换机的VLAN配置
一.实验目的:将S1配置成VTP-Server,S2配置成VTP-Transparent,S3配置成VTP-Client,S4配置成VTP-Client 二.拓扑图如下 三.具体步骤: (1)S1交换 ...
- OI路上 day -9
/* 嗯还有9天. 就只有9天了. 啊还剩9天吖! 多年后 我可能还会记得 那些年,我们学过的算法. 多年后 我可能会对别人说 我学过OI我喜欢OI并一直热爱着它. 9天后 我可能再也不会来到这个地方 ...
- 消息模板-RabbitTemplate
RabbitTemplate是我们在与SpringAMQP整合的时候进行发送消息的关键类该类提供了丰富的发送消息的方法,包括可靠性消息投递.回调监听消息接口ConfirmCallback.返回值确认接 ...
- Java并发之CAS的三大问题
在Java并发包中有一些并发框架也使用了自旋CAS的方式实现了原子操作,比如:LinkedTransferQueue类的Xfer方法.CAS虽然很高效的解决了原子操作,但是CAS仍然存在三大问题:AB ...
- win10专业版安装docker实战
在win10专业版上安装docker 一,下载Docker for Windows Installer.exe 二,在程序面板---程序----程序和功能中找到启动或关闭windows功能,将hype ...
- HLS协议解析
1. 综述 HLS(HTTP Live Streaming) 把整个流分成一个个小的基于 HTTP 的文件来下载,每次只下载一些.HLS 协议由三部分组成:HTTP.M3U8.TS.这三部分中,HTT ...
- leetcode-hard-array-238. Product of Array Except Self-NO
mycode 99.47% class Solution(object): def productExceptSelf(self, nums): """ :type ...
- Cortex-M3 异常中断向量表
[Cortex-M3异常与中断] 支持10个系统异常和最多240个外部中断: 支持3个固定的高优先级和多达256级的可编程优先级,支持128级抢占: #0~15在Cortex-M3中定义,IRQ#0~ ...