从头学pytorch(四) softmax回归实现
FashionMNIST数据集共70000个样本,60000个train,10000个test.共计10种类别.

通过如下方式下载.
mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=True, download=True,
transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=False, download=True,
transform=transforms.ToTensor())
softmax从零实现
- 数据加载
- 初始化模型参数
- 模型定义
- 损失函数定义
- 优化器定义
- 训练
数据加载
import torch
import torchvision
import torchvision.transforms as transforms
mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=True, download=True,
transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=False, download=True,
transform=transforms.ToTensor())
batch_size = 256
num_workers = 4 # 多进程同时读取
train_iter = torch.utils.data.DataLoader(
mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
初始化模型参数
num_inputs = 784 # 图像是28 X 28的图像,共784个特征
num_outputs = 10
W = torch.tensor(np.random.normal(
0, 0.01, (num_inputs, num_outputs)), dtype=torch.float)
b = torch.zeros(num_outputs, dtype=torch.float)
W.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
模型定义
记忆要点:沿着dim方向.行为维度0,列为维度1. 沿着列的方向相加,即对每一行的元素相加.
def softmax(X): # X.shape=[样本数,类别数]
X_exp = X.exp()
partion = X_exp.sum(dim=1, keepdim=True) # 沿着列方向求和,即对每一行求和
#print(partion.shape)
return X_exp/partion # 广播机制,partion被扩展成与X_exp同shape的,对应位置元素做除法
def net(X):
# 通过`view`函数将每张原始图像改成长度为`num_inputs`的向量
return softmax(torch.mm(X.view(-1, num_inputs), W) + b)
损失函数定义
假设训练数据集的样本数为\(n\),交叉熵损失函数定义为
\]
其中\(\boldsymbol{\Theta}\)代表模型参数。同样地,如果每个样本只有一个标签,那么交叉熵损失可以简写成\(\ell(\boldsymbol{\Theta}) = -(1/n) \sum_{i=1}^n \log \hat y_{y^{(i)}}^{(i)}\)。
def cross_entropy(y_hat, y):
y_hat_prob = y_hat.gather(1, y.view(-1, 1)) # ,沿着列方向,即选取出每一行下标为y的元素
return -torch.log(y_hat_prob)
https://pytorch.org/docs/stable/torch.html
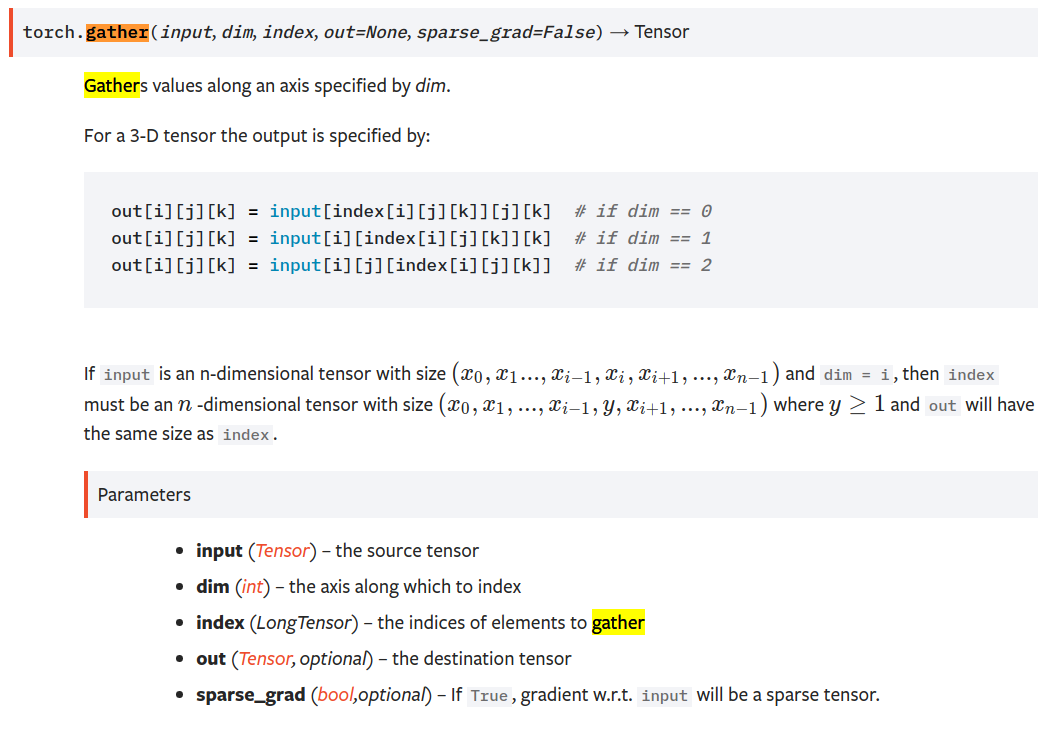
gather()沿着维度dim,选取索引为index的元素
优化算法定义
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # 注意这里更改param时用的param.data
准确度评估函数
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
训练
- 读入batch_size个样本
- 前向传播,计算预测值
- 与真值相比,计算loss
- 反向传播,计算梯度
- 更新各个参数
如此循环往复.
num_epochs, lr = 5, 0.1
def train():
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
#print(X.shape,y.shape)
y_hat = net(X)
l = cross_entropy(y_hat, y).sum() # 求loss
l.backward() # 反向传播,计算梯度
sgd([W, b], lr, batch_size) # 根据梯度,更新参数
W.grad.data.zero_() # 清空梯度
b.grad.data.zero_()
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train_acc %.3f,test_acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum/n, test_acc))
train()
输出如下:
epoch 1, loss 0.7848, train_acc 0.748,test_acc 0.793
epoch 2, loss 0.5704, train_acc 0.813,test_acc 0.811
epoch 3, loss 0.5249, train_acc 0.825,test_acc 0.821
epoch 4, loss 0.5011, train_acc 0.832,test_acc 0.821
epoch 5, loss 0.4861, train_acc 0.837,test_acc 0.829
softmax的简洁实现
- 数据加载
- 模型定义及初始化模型参数
- 损失函数定义
- 优化器定义
- 训练
数据读取
import torch
from torch import nn
from torch.nn import init
import numpy as np
import sys
import torchvision
import torchvision.transforms as transforms
mnist_train = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=True, download=True,
transform=transforms.ToTensor())
mnist_test = torchvision.datasets.FashionMNIST(root='/home/sc/disk/keepgoing/learn_pytorch/Datasets/FashionMNIST',
train=False, download=True,
transform=transforms.ToTensor())
batch_size = 256
num_workers = 4 # 多进程同时读取
train_iter = torch.utils.data.DataLoader(
mnist_train, batch_size=batch_size, shuffle=True, num_workers=num_workers)
test_iter = torch.utils.data.DataLoader(
mnist_test, batch_size=batch_size, shuffle=False, num_workers=num_workers)
模型定义及模型参数初始化
num_inputs = 784 # 图像是28 X 28的图像,共784个特征
num_outputs = 10
class LinearNet(nn.Module):
def __init__(self,num_inputs,num_outputs):
super(LinearNet,self).__init__()
self.linear = nn.Linear(num_inputs,num_outputs)
def forward(self,x): #x.shape=(batch,1,28,28)
return self.linear(x.view(x.shape[0],-1)) #输入shape应该是[,784]
net = LinearNet(num_inputs,num_outputs)
torch.nn.init.normal_(net.linear.weight,mean=0,std=0.01)
torch.nn.init.constant_(net.linear.bias,val=0)
没有什么要特别注意的,注意一点,由于self.linear的input size为[,784],所以要对x做一次变形x.view(x.shape[0],-1)
损失函数定义
torch里的这个损失函数是包括了softmax计算概率和交叉熵计算的.
loss = nn.CrossEntropyLoss()
优化器定义
optimizer = torch.optim.SGD(net.parameters(),lr=0.01)
训练
精度评测函数
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
训练
- 读入batch_size个样本
- 前向传播,计算预测值
- 与真值相比,计算loss
- 反向传播,计算梯度
- 更新各个参数
如此循环往复.
num_epochs = 5
def train():
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X,y in train_iter:
y_hat=net(X) #前向传播
l = loss(y_hat,y).sum()#计算loss
l.backward()#反向传播
optimizer.step()#参数更新
optimizer.zero_grad()#清空梯度
train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))
train()
输出
epoch 1, loss 0.0054, train acc 0.638, test acc 0.681
epoch 2, loss 0.0036, train acc 0.716, test acc 0.724
epoch 3, loss 0.0031, train acc 0.749, test acc 0.745
epoch 4, loss 0.0029, train acc 0.767, test acc 0.759
epoch 5, loss 0.0028, train acc 0.780, test acc 0.770
从头学pytorch(四) softmax回归实现的更多相关文章
- 【动手学pytorch】softmax回归
一.什么是softmax? 有一个数组S,其元素为Si ,那么vi 的softmax值,就是该元素的指数与所有元素指数和的比值.具体公式表示为: softmax回归本质上也是一种对数据的估计 二.交叉 ...
- 从头学pytorch(一):数据操作
跟着Dive-into-DL-PyTorch.pdf从头开始学pytorch,夯实基础. Tensor创建 创建未初始化的tensor import torch x = torch.empty(5,3 ...
- 从头学pytorch(十四):lenet
卷积神经网络 在之前的文章里,对28 X 28的图像,我们是通过把它展开为长度为784的一维向量,然后送进全连接层,训练出一个分类模型.这样做主要有两个问题 图像在同一列邻近的像素在这个向量中可能相距 ...
- 从头学pytorch(六):权重衰减
深度学习中常常会存在过拟合现象,比如当训练数据过少时,训练得到的模型很可能在训练集上表现非常好,但是在测试集上表现不好. 应对过拟合,可以通过数据增强,增大训练集数量.我们这里先不介绍数据增强,先从模 ...
- 从头学pytorch(三) 线性回归
关于什么是线性回归,不多做介绍了.可以参考我以前的博客https://www.cnblogs.com/sdu20112013/p/10186516.html 实现线性回归 分为以下几个部分: 生成数据 ...
- 从头学pytorch(十九):批量归一化batch normalization
批量归一化 论文地址:https://arxiv.org/abs/1502.03167 批量归一化基本上是现在模型的标配了. 说实在的,到今天我也没搞明白batch normalize能够使得模型训练 ...
- 从头学pytorch(二十):残差网络resnet
残差网络ResNet resnet是何凯明大神在2015年提出的.并且获得了当年的ImageNet比赛的冠军. 残差网络具有里程碑的意义,为以后的网络设计提出了一个新的思路. googlenet的思路 ...
- 从头学pytorch(五) 多层感知机及其实现
多层感知机 上图所示的多层感知机中,输入和输出个数分别为4和3,中间的隐藏层中包含了5个隐藏单元(hidden unit).由于输入层不涉及计算,图3.3中的多层感知机的层数为2.由图3.3可见,隐藏 ...
- 从头学pytorch(二) 自动求梯度
PyTorch提供的autograd包能够根据输⼊和前向传播过程⾃动构建计算图,并执⾏反向传播. Tensor Tensor的几个重要属性或方法 .requires_grad 设为true的话,ten ...
随机推荐
- DE1-GHRD
新建工程socs_system 进入菜单选择Tools---Qsys 配置hps系统 首先选择 在更改参数 配置hps的sdram各项参数 将名字改为hps_0 这样hps配置完成:在配置存储器和其他 ...
- Laravel 部署到阿里云 / 腾讯云
首先你需要一台阿里云/腾讯云服务器 安装系统选择 ubuntu 16.04 然后通过 ssh 登录远程服务器按下列步骤进行配置: 更新列表 apt-get update 安装语言包 sudo apt- ...
- 免费天气API,天气JSON API,不限次数获取十五天的天气预报
紧急情况说明: 禁用IP列表: 39.104.69.*(原因39.104.69.6 在2018年10月的 17~20日 排行为top 1,每天几十万次.) 47.98.211.* (原因47.98.2 ...
- codeforces 597 div2 E. Hyakugoku and Ladders(概率dp)
题目链接:https://codeforces.com/contest/1245/problem/E 题意:有一个10x10的网格,左下角是起点,左上角是终点,从起点开始,如图所示蛇形走到终点,每一步 ...
- POJ 2018 Best Cow Fences(二分答案)
题目链接:http://poj.org/problem?id=2018 题目给了一些农场,每个农场有一定数量的奶牛,农场依次排列,问选择至少连续排列F个农场的序列,使这些农场的奶牛平均数量最大,求最大 ...
- 剑指offer 面试题38 字符串的排列
我惯用的dfs模板直接拿来套 class Solution { public: vector<string> Permutation(string str) { if(str.empty( ...
- THINKPHP 模板上传图片--后台接收图片
模板 {extend name="public/base" /} {block name="body"} <div class="row&quo ...
- C语言程序设计100例之(27):回旋方阵
例27 回旋方阵 问题描述 编写程序,生成从内到外是连续的自然数排列的回旋方阵.例如,当n=3和n=4时的回旋方阵如下图1所示. 图1 由内到外回旋方阵 输入格式 一个正整数n(1≤n ...
- sqlmap使用教程(超详细)
-u 指定目标URL (可以是http协议也可以是https协议) -d 连接数据库 --dbs 列出所有的数据库 --current-db 列出当前数据库 --tables 列出当前的表 --col ...
- 安装CDH第三方依赖包
安装CDH第三方依赖包: yum install chkconfig python bind-utils psmisc libxslt zlib sqlite cyrus-sasl-plain cyr ...