Flume基础学习
Flume是一款非常优秀的日志采集工具。支持多种形式的日志采集,作为apache的顶级开源项目,Flume再大数据方面具有广泛的应用
首先需要在Flume的解压目录中conf文件夹中将flume-env.sh.templete更改未flume.env.sh
并修改jdk的位置
Source
我们可以从Avro,NetCat。Http,TailDir。我们在Java开发中通常都是使用的log4j等日志工具进行日志按天存储,所以我们重点关注下tailDir Source
Taildir Source
在Flume1.7之前如果想要监控一个文件新增的内容,我们一般采用的source 为 exec tail,但是这会有一个弊端,就是当你的服务器宕机重启后,此时数据读取还是从头开始,这显然不是我们想看到的! 在Flume1.7 没有出来之前我们一般的解决思路为:当读取一条记录后,就把当前的记录的行号记录到一个文件中,宕机重启时,我们可以先从文件中获取到最后一次读取文件的行数,然后继续监控读取下去。保证数据不丢失、不重复。
在Flume1.7时新增了一个source 的类型为taildir,它可以监控一个目录下的多个文件,并且实现了实时读取记录保存的断点续传功能。
但是Flume1.7中如果文件重命名,那么会被当成新文件而被重新采集。
Channel
Memory Channel
Memory Channel把Event保存在内存队列中,该队列能保存的Event数量有最大值上限。由于Event数据都保存在内存中,Memory Channel有最好的性能,不过也有数据可能会丢失的风险,如果Flume崩溃或者重启,那么保存在Channel中的Event都会丢失。同时由于内存容量有限,当Event数量达到最大值或者内存达到容量上限,Memory Channel会有数据丢失。
File Channel
File Channel把Event保存在本地硬盘中,比Memory Channel提供更好的可靠性和可恢复性,不过要操作本地文件,性能要差一些。
Kafka Channel
Kafka Channel把Event保存在Kafka集群中,能提供比File Channel更好的性能和比Memory Channel更高的可靠性。
sink
Avro Sink
Avro Sink是Flume的分层收集机制的重要组成部分。 发送到此接收器的Flume事件变为Avro事件,并发送到配置指定的主机名/端口对。事件将从配置的通道中按照批量配置的批量大小取出。
Kafka Sink
Kafka Sink将会使用FlumeEvent header中的topic和key属性来将event发送给Kafka。如果FlumeEvent的header中有topic属性,那么此event将会发送到header的topic属性指定的topic中。如果FlumeEvent的header中有key属性,此属性将会被用来对此event中的数据指定分区,具有相同key的event将会被划分到相同的分区中,如果key属性null,那么event将会被发送到随机的分区中。
可以通过自定义拦截器来设置某个event的header中的key或者topic属性。
Flume拦截器
主要用于,过滤时间戳不合法和json数据不完整的日志,将错误日志、启动日志和事件日志区分开来,方便发往kafka的不同topic。配置参考后符例
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
public class LogETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
String body = new String(event.getBody(), Charset.forName("UTF-8"));
// body为原始数据,newBody为处理后的数据,判断是否为display的数据类型
if (LogUtils.validateReportLog(body)) {
return event;
}
return null;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> intercepts = new ArrayList<>();
// 遍历所有Event,将拦截器校验不合格的过滤掉
for (Event event : events) {
Event interceptEvent = intercept(event);
if (interceptEvent != null){
intercepts.add(interceptEvent);
}
}
return intercepts;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
public Interceptor build() {
return new LogETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
启动命令
flume-ng agent
--conf-file /opt/module/flume/conf/file-flume-kafka.conf
--name a1
-Dflume.root.logger=INFO,console
第一个参数为自己编写的配置文件路径
第二个参数为flume agent的名称。即配置文件中定义的名称
第三个参数为在flume中打印Info级别日志,并打印到控制台
大数据中的数据处理流程例子
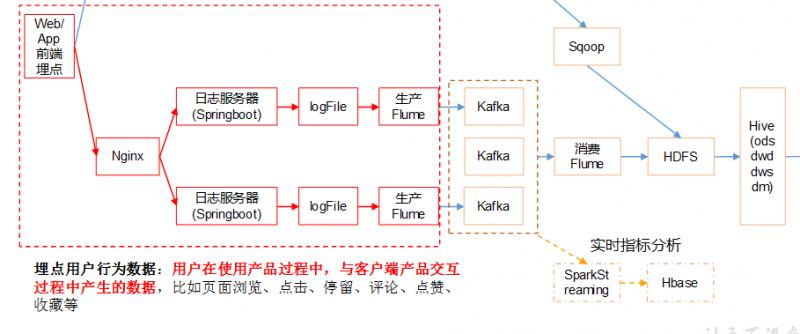
从上例图可以看出。我们从日志到转化未HDFS中可以消费的数据一般还要经历两个Flume阶段
- 日志文件-->Flume-->Kafka
- kafka-->Flume-->HDFS
两个阶段的处理配置
第一阶段的配置参考
a1.sources=r1
a1.channels=c1 c2
a1.sinks=k1 k2
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /opt/module/flume/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/app.+
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.flume.interceptor.LogETLInterceptor$Builder
# selector
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = logType
a1.sources.r1.selector.mapping.start = c1
a1.sources.r1.selector.mapping.event = c2
# configure channel
a1.channels.c1.type = memory
a1.channels.c1.capacity=10000
a1.channels.c1.byteCapacityBufferPercentage=20
a1.channels.c2.type = memory
a1.channels.c2.capacity=10000
a1.channels.c2.byteCapacityBufferPercentage=20
# configure sink
# start-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = topic_start
a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k1.kafka.flumeBatchSize = 2000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.channel = c1
# event-sink
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.topic = topic_event
a1.sinks.k2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sinks.k2.kafka.flumeBatchSize = 2000
a1.sinks.k2.kafka.producer.acks = 1
a1.sinks.k2.channel = c2
第二阶段的配置参考
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.zookeeperConnect = hadoop102:2181,hadoop103:2181,hadoop104:2181
a1.sources.r1.kafka.topics=topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r2.kafka.zookeeperConnect = hadoop102:2181,hadoop103:2181,hadoop104:2181
a1.sources.r2.kafka.topics=topic_event
## channel1
a1.channels.c1.type=memory
a1.channels.c1.capacity=100000
a1.channels.c1.transactionCapacity=10000
## channel2
a1.channels.c2.type=memory
a1.channels.c2.capacity=100000
a1.channels.c2.transactionCapacity=10000
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_start/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 30
a1.sinks.k1.hdfs.roundUnit = second
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /origin_data/gmall/log/topic_event/%Y-%m-%d
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 30
a1.sinks.k2.hdfs.roundUnit = second
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 30
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 30
a1.sinks.k2.hdfs.rollSize = 0
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2
本文由博客一文多发平台 OpenWrite 发布!
Flume基础学习的更多相关文章
- 零基础学习hadoop到上手工作线路指导(编程篇)
问题导读: 1.hadoop编程需要哪些基础? 2.hadoop编程需要注意哪些问题? 3.如何创建mapreduce程序及其包含几部分? 4.如何远程连接eclipse,可能会遇到什么问题? 5.如 ...
- Spark基础学习精髓——第一篇
Spark基础学习精髓 1 Spark与大数据 1.1 大数据基础 1.1.1 大数据特点 存储空间大 数据量大 计算量大 1.1.2 大数据开发通用步骤及其对应的技术 大数据采集->大数据预处 ...
- Hadoop学习笔记—19.Flume框架学习
START:Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. ...
- salesforce 零基础学习(五十二)Trigger使用篇(二)
第十七篇的Trigger用法为通过Handler方式实现Trigger的封装,此种好处是一个Handler对应一个sObject,使本该在Trigger中写的代码分到Handler中,代码更加清晰. ...
- 如何从零基础学习VR
转载请声明转载地址:http://www.cnblogs.com/Rodolfo/,违者必究. 近期很多搞技术的朋友问我,如何步入VR的圈子?如何从零基础系统性的学习VR技术? 本人将于2017年1月 ...
- IOS基础学习-2: UIButton
IOS基础学习-2: UIButton UIButton是一个标准的UIControl控件,UIKit提供了一组控件:UISwitch开关.UIButton按钮.UISegmentedContro ...
- HTML5零基础学习Web前端需要知道哪些?
HTML零基础学习Web前端网页制作,首先是要掌握一些常用标签的使用和他们的各个属性,常用的标签我总结了一下有以下这些: html:页面的根元素. head:页面的头部标签,是所有头部元素的容器. b ...
- python入门到精通[三]:基础学习(2)
摘要:Python基础学习:列表.元组.字典.函数.序列化.正则.模块. 上一节学习了字符串.流程控制.文件及目录操作,这节介绍下列表.元组.字典.函数.序列化.正则.模块. 1.列表 python中 ...
- python入门到精通[二]:基础学习(1)
摘要:Python基础学习: 注释.字符串操作.用户交互.流程控制.导入模块.文件操作.目录操作. 上一节讲了分别在windows下和linux下的环境配置,这节以linux为例学习基本语法.代码部分 ...
随机推荐
- 【Unity|C#】番外篇(1)——6个重要概念:栈与堆,值类型与引用类型,装箱与拆箱
传送门:https://www.cnblogs.com/arthurliu/archive/2011/04/13/2015120.html
- C 库函数 - strcpy()
描述 C 库函数 char *strcpy(char *dest, const char *src) 把 src 所指向的字符串复制到 dest. 需要注意的是如果目标数组 dest 不够大,而源字符 ...
- tp3.2框架关闭日志记录
在config.php中阿计入如下配置: 'LOG_RECORD' => false, // 默认不记录日志 'LOG_TYPE' => 'File', // 日志记录类型 默认为文件方式 ...
- 巨杉Tech | SparkSQL+SequoiaDB 性能调优策略
当今时代,企业数据越发膨胀.数据是企业的价值,但数据处理也是一种技术挑战.在海量数据处理的场景,即使单机计算能力再强,也无法满足日益增长的数据处理需求.所以,分布式才是解决该类问题的根本解决方案.而在 ...
- 油候插件grant的使用
// ==UserScript== // @name Test Baidu // @namespace http://www.baidu.com/ // @version 0.1 // @descri ...
- AcWing 1018. 最低通行费
#include<iostream> using namespace std ; ,INF=1e9; int dp[N][N],w[N][N]; int n; int main() { c ...
- [CCPC2019 哈尔滨] A. Artful Paintings - 差分约束,最短路
Description 给 \(N\) 个格子区间涂色,有两类限制条件 区间 \([L,R]\) 内至少 \(K\) 个 区间 \([L,R]\) 外至少 \(K\) 个 求最少要涂多少个格子 Sol ...
- Unity中常用的数据结构总结
本篇博文对U3D经常用到的数据结构和各种数据结构的应用场景总结下. 1.几种常见的数据结构 这里主要总结下在工作中常碰到的几种数据结构:Array,ArrayList,List<T>,Li ...
- Itext相关知识
最近需求用到office和pdf相关知识,office使用poi操作的,pdf则使用Itext操作 Itext官网: http://itextpdf.com/ Itext7相关使用示例:https:/ ...
- webrtc博客收藏
<使用WebRTC搭建前端视频聊天室——入门篇><使用WebRTC搭建前端视频聊天室——信令篇><使用WebRTC搭建前端视频聊天室——点对点通信篇><使用W ...