【58】目标检测之YOLO 算法
YOLO 算法(Putting it together: YOLO algorithm)
你们已经学到对象检测算法的大部分组件了,在这个笔记里,我们会把所有组件组装在一起构成YOLO对象检测算法。
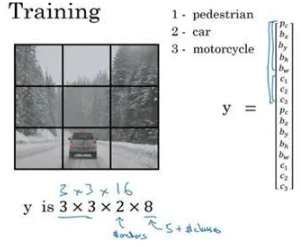
我们先看看如何构造你的训练集,假设你要训练一个算法去检测三种对象,行人、汽车和摩托车,你还需要显式指定完整的背景类别。
这里有3个类别标签,如果你要用两个anchor box,那么输出 y 就是3×3×2×8,其中3×3表示3×3个网格,2是anchor box的数量,8是向量维度,8实际上先是5(p_c,b_x,b_y,b_h,b_w)再加上类别的数量(c_1,c_2,c_3)。你可以将它看成是3×3×2×8,或者3×3×16。要构造训练集,你需要遍历9个格子,然后构成对应的目标向量y。
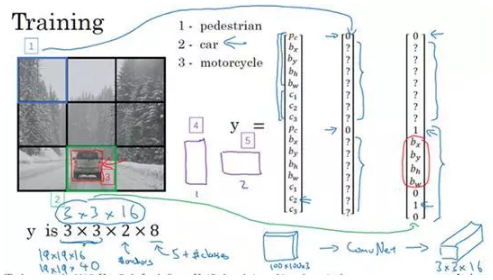
所以先看看第一个格子(编号1),里面没什么有价值的东西,行人、车子和摩托车,三个类别都没有出现在左上格子中,所以对应那个格子目标y就是这样的,
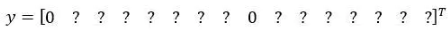
第一个anchor box的 p_c 是0,因为没什么和第一个anchor box有关的,第二个anchor box的 p_c 也是0,剩下这些值是don’t care-s。
现在网格中大多数格子都是空的,但那里的格子(编号2)会有这个目标向量y,
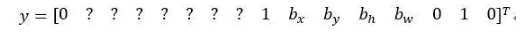
所以假设你的训练集中,对于车子有这样一个边界框(编号3),水平方向更长一点。所以如果这是你的anchor box,这是anchor box 1(编号4),这是anchor box 2(编号5),然后红框和anchor box 2的交并比更高,那么车子就和向量的下半部分相关。要注意,这里和anchor box 1有关的 p_c 是0,剩下这些分量都是don’t care-s,然后你的第二个 p_c=1,然后你要用这些(b_x,b_y,b_h,b_w)来指定红边界框的位置,然后指定它的正确类别是2(c_1=0,c_2=1,c_3=0),对吧,这是一辆汽车。

所以你这样遍历9个格子,遍历3×3网格的所有位置,你会得到这样一个向量,得到一个16维向量,所以最终输出尺寸就是3×3×16。
和之前一样,简单起见,我在这里用的是3×3网格,实践中用的可能是19×19×16,或者需要用到更多的anchor box,可能是19×19×5×8,即19×19×40,用了5个anchor box。这就是训练集,然后你训练一个卷积网络,输入是图片,可能是100×100×3,然后你的卷积网络最后输出尺寸是,在我们例子中是3×3×16或者3×3×2×8。
接下来我们看看你的算法是怎样做出预测的?
输入图像,你的神经网络的输出尺寸是这个3××3×2×8,对于9个格子,每个都有对应的向量。对于左上的格子(编号1),那里没有任何对象,那么我们希望你的神经网络在那里(第一个p_c)输出的是0,这里(第二个p_c)是0,然后我们输出一些值,你的神经网络不能输出问号,不能输出don’t care-s,剩下的我输入一些数字,但这些数字基本上会被忽略,因为神经网络告诉你,那里没有任何东西,所以输出是不是对应一个类别的边界框无关紧要,所以基本上是一组数字,多多少少都是噪音(输出 y 如编号3所示)。
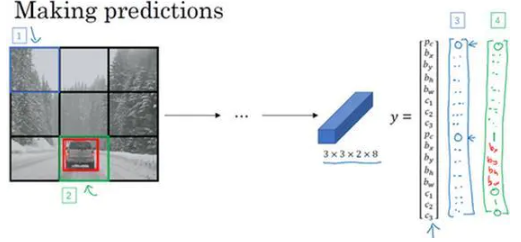
和这里的边界框不大一样,希望y的值,那个左下格子(编号2)的输出y(编号4所示),形式是,对于边界框1来说(p_c)是0,然后就是一组数字,就是噪音(anchor box 1对应行人,此格子中无行人,p_c=0,b_x=?,b_y=?,b_h=?,b_w=?,c_1=?c_2=?,c_3=?)。
希望你的算法能输出一些数字,可以对车子指定一个相当准确的边界框(anchor box 2对应汽车,此格子中有车,p_c=1,b_x,b_y,b_h,b_w,c_1=0,c_2=1,c_3=0),这就是神经网络做出预测的过程。

最后你要运行一下这个非极大值抑制,为了让内容更有趣一些,我们看看一张新的测试图像,这就是运行非极大值抑制的过程。如果你使用两个anchor box,那么对于9个格子中任何一个都会有两个预测的边界框,其中一个的概率p_c很低。但9个格子中,每个都有两个预测的边界框,比如说我们得到的边界框是是这样的,注意有一些边界框可以超出所在格子的高度和宽度(编号1所示)。
接下来你抛弃概率很低的预测,去掉这些连神经网络都说,这里很可能什么都没有,所以你需要抛弃这些(编号2所示)。
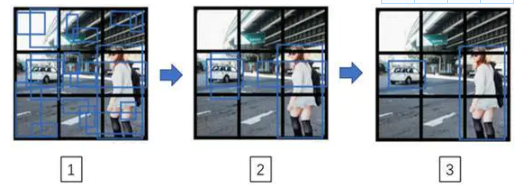
最后,如果你有三个对象检测类别,你希望检测行人,汽车和摩托车,那么你要做的是,对于每个类别单独运行非极大值抑制,处理预测结果所属类别的边界框,用非极大值抑制来处理行人类别,用非极大值抑制处理车子类别,然后对摩托车类别进行非极大值抑制,运行三次来得到最终的预测结果。所以算法的输出最好能够检测出图像里所有的车子,还有所有的行人(编号3所示)。
这就是YOLO对象检测算法,这实际上是最有效的对象检测算法之一,包含了整个计算机视觉对象检测领域文献中很多最精妙的思路。
【58】目标检测之YOLO 算法的更多相关文章
- 第三十五节,目标检测之YOLO算法详解
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object de ...
- 第三十六节,目标检测之yolo源码解析
在一个月前,我就已经介绍了yolo目标检测的原理,后来也把tensorflow实现代码仔细看了一遍.但是由于这个暑假事情比较大,就一直搁浅了下来,趁今天有时间,就把源码解析一下.关于yolo目标检测的 ...
- 深度学习与CV教程(13) | 目标检测 (SSD,YOLO系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 目标检测之YOLO V2 V3
YOLO V2 YOLO V2是在YOLO的基础上,融合了其他一些网络结构的特性(比如:Faster R-CNN的Anchor,GooLeNet的\(1\times1\)卷积核等),进行的升级.其目的 ...
- 目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去.但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后 ...
- 【转】目标检测之YOLO系列详解
本文逐步介绍YOLO v1~v3的设计历程. YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这 ...
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- 小白也能弄懂的目标检测之YOLO系列 - 第一期
大家好,上期分享了电脑端几个免费无广告且实用的录屏软件,这期想给大家来讲解YOLO这个算法,从零基础学起,并最终学会YOLOV3的Pytorch实现,并学会自己制作数据集进行模型训练,然后用自己训练好 ...
- 目标检测之YOLO V1
前面介绍的R-CNN系的目标检测采用的思路是:首先在图像上提取一系列的候选区域,然后将候选区域输入到网络中修正候选区域的边框以定位目标,对候选区域进行分类以识别.虽然,在Faster R-CNN中利用 ...
随机推荐
- 基于Arduino开发的智能蓝牙小车
基于Arduino的智能蓝牙小车 材料准备: Arduino开发板一块.四驱小车底板及相关配件一套.L298N驱动模块一个.HC-05/06蓝牙模块一块,九伏电源一块(用于主板供电).12V锂电池一块 ...
- 全国疫情精准定点动态更新(.net core)
前言 疫情远比我们在年初想的发展迅速,在过年前还计划着可以亲戚聚聚,结果都泡汤了,开始了自家游. 在初三的时候,看到那个丁香医生,觉得不够详细,比如说我想看下周边城市的疫情情况,但是我地理不好,根本不 ...
- k3s首季在线培训来袭!本周四晚,线上见!
筹备已久的k3s在线培训终于要和大家见面啦! k3s是一款适用于边缘计算场景以及IoT场景的轻量级Kubernetes发行版,经过CNCF的一致性认证.由业界应用最广泛的Kubernetes管理平台R ...
- TortoiseSVN的安装及其简单使用
VisualSVN-Server的安装以及简单使用 TortoiseSVN的安装及其简单使用 VisualSVN的安装及冲突的处理 安装完VisualSVN-Server后,Test仓储里边什么都没有 ...
- JAVA String对象和字符串常量的关系解析
JAVA String对象和字符串常量的关系解析 1 字符串内部列表 JAVA中所有的对象都存放在堆里面,包括String对象.字符串常量保存在JAVA的.class文件的常量池中,在编译期就确定好了 ...
- objectarx 统计面积
除了最后一个输出面积到excel没做,其他都是做了的.只支持AcDbPolyline和AcDbCircle.这是我模仿网上的动态图做的,主要是为了练习.下面我把自己的一些心得分享出来.使用到的一些帮助 ...
- 【做题笔记】 P1610 鸿山洞的灯
正解:DP 比较好写的/我用的算法:贪心 首先需要理解几个地方: 第二行输入的 \(n\) 个数字是每盏灯所在的地方.可以不按顺序,灯与灯之间的距离是个变量. 对于任意一段区间,只要是在 \(\tex ...
- C++ traits技法的一点理解
为了更好的理解traits技法.我们一步一步的深入.先从实际写代码的过程中我们遇到诸如下面伪码说起. template< typename T,typename B> void (T a, ...
- 《Python学习手册 第五版》 -第3章 你应如何运行Python程序
在这里,运行Python程序的前提是你的电脑已经配置Python相关的运行环境,如何配置可以通过本书的附件查看,也可以自行通过网络查询配置,在此不再赘述 运行一个Python程序,主要有6种方式 1. ...
- Sklearn——SVC学习笔记(图像分割)
新年第二更. 很长时间前就想总结一下用SVC来做图像分割的方法了,方法实现了,但是一直没有总结,今天再来回顾一遍. 首先介绍一下.今天要总结的图像分割其实属于像素级分类,其输出是把图像按照不同的类别逐 ...