Java代码操作Elasticsearch
创建maven项目,导入依赖
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/fastjson -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency> <!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-core -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.9.8</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.9.8</version>
</dependency> <!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-annotations -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.9.8</version>
</dependency>
连接所有方法都要用,提成公共方法
public TransportClient getClient() throws UnknownHostException {
//步骤一:创建一个Settings对象,指定集群名字
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
//步骤二:创建一个Client连接对象
TransportClient client = new PreBuiltTransportClient(settings);
//步骤三:连接到ES服务器
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9300));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9301));
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("127.0.0.1"), 9302));
return client;
}
1.创建一个空的索引库
/**
* 创建空的索引库
*/
@Test
public void createNullIndex() throws UnknownHostException {
TransportClient client = getClient();
//创建一个空的索引库 admin()管理权限 indices()索引库 prepareCreate()创建一个索引库 get()执行之前的操作请求
client.admin().indices().prepareCreate("y2170").get();
//关闭client对象
client.close();
}
2.索引库指定Mapping信息
2.1 利用XContentBuilder对象拼接JSON字符串
2.2 手动用过字符串拼接得到JSON字符串
{
"hello":{
"properties":{
"id":{
"type":"long",
"store":true,
"index":"not_analyzed"
},
"title":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"ik_max_word"
},
"content":{
"type":"text",
"store":true,
"index":"analyzed",
"analyzer":"ik_max_word"
}
}
}
}
案例:
/**
* 指定索引库的Mapping信息
*/
@Test
public void createMappingByIndex() throws IOException {
TransportClient client = getClient();
//创建一个XContentBuilder对象,用于拼接JSON格式字符串
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder();
xContentBuilder.startObject().startObject("hello").startObject("properties")
.startObject("id").field("type","long").field("store",true).field("index","not_analyzed").endObject()
.startObject("title").field("type","text").field("store",true).field("index","analyzed").field("analyzer","ik_max_word").endObject()
.startObject("content").field("type","text").field("store",true).field("index","analyzed").field("analyzer","ik_max_word").endObject()
.endObject().endObject().endObject();
//指定索引库以及Type类型的Mapping映射信息 preparePutMapping代表向哪一个索引库指定mpiing信息 setType代表该索引库下的TYPE,与上方JSON创建的Type保持一致
//setSource 指定JSON字符串的存储对象 get执行
client.admin().indices().preparePutMapping("y2170").setType("hello").setSource(xContentBuilder).get(); //关闭资源
client.close();
}
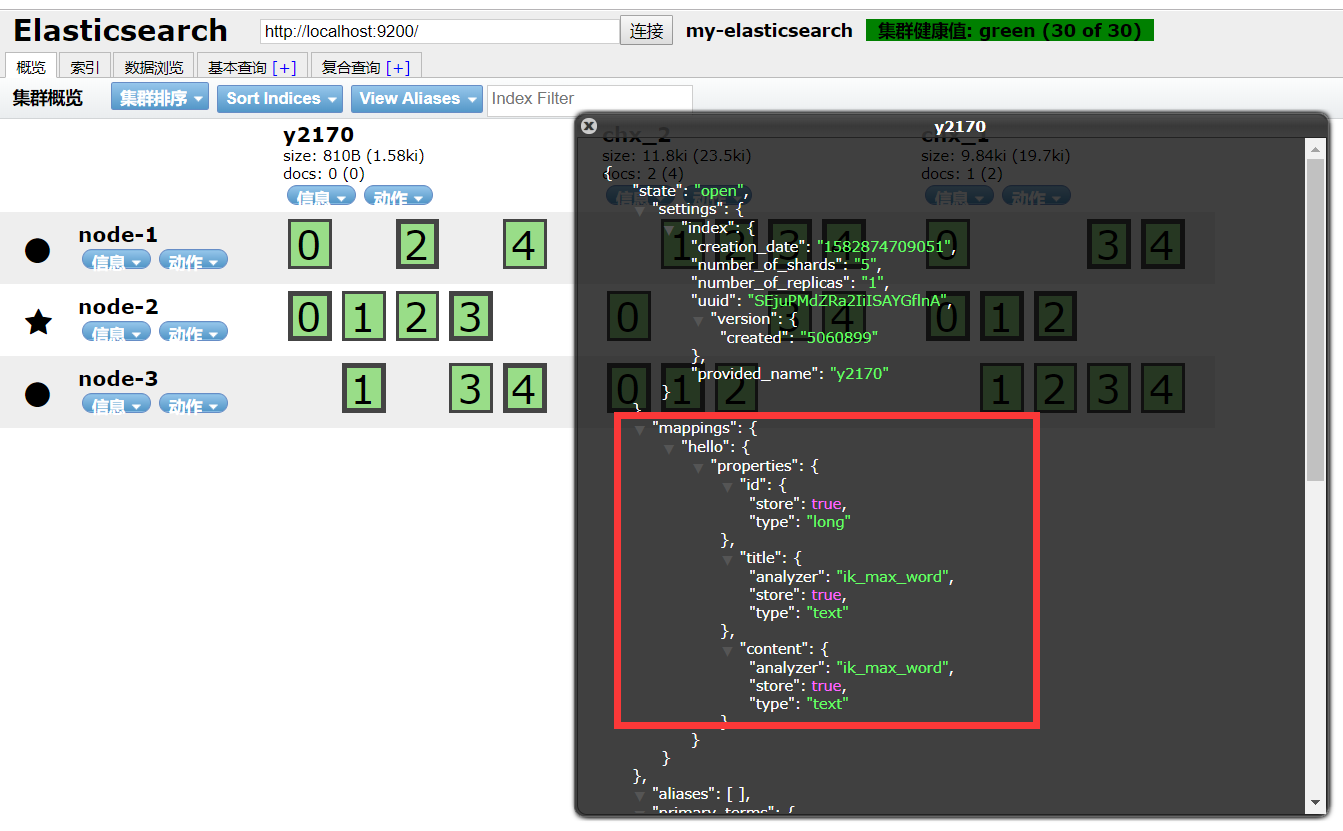
3.创建索引库同时指定Mapping信息
/**
* 创建索引库并且指定Mapping信息
*/
@Test
public void createIndexAndMapping() throws IOException {
TransportClient client = getClient();
//创建索引库
client.admin().indices().prepareCreate("wdksoft").get();
//创建Mapping信息
//创建一个XContentBuilder对象,用于拼接JSON格式字符串
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder();
xContentBuilder.startObject().startObject("article").startObject("properties")
.startObject("id").field("type","long").field("store",true).field("index","not_analyzed").endObject()
.startObject("title").field("type","text").field("store",true).field("index","analyzed").field("analyzer","ik_max_word").endObject()
.startObject("content").field("type","text").field("store",true).field("index","analyzed").field("analyzer","ik_max_word").endObject()
.endObject().endObject().endObject(); client.admin().indices().preparePutMapping("wdksoft").setType("article").setSource(xContentBuilder).get(); //关闭资源
client.close();
}
4.删除索引库
/**
* 删除索引库
*/
@Test
public void deleteIndex() throws UnknownHostException {
TransportClient client = getClient();
//删除索引库
client.admin().indices().prepareDelete("wdksoft").get(); //关闭资源
client.close();
}
5.创建文档-通过XContentBuilder对象拼接JSON格式字符串
( { ) 开头用.startObject()
( } )结尾用.endObject()
域用.field(键,值),多个就继续在后面追加
/**
* 创建文档-通过XContentBuilder对象拼接JSON字符串
*/
@Test
public void createDocumentByXC() throws IOException {
TransportClient client = getClient();
//构建文档信息
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder();
xContentBuilder.startObject().field("id",1).field("title","Lucene是apache软件基金会4 jakarta项目组的一个子项目")
.field("content","Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的")
.endObject();
//创建文档
client.prepareIndex("y2170","hello","1").setSource(xContentBuilder).get();
client.close();
}

6.创建文档-通过对象转换为JSON字符串
Hello类
public class Hello {
private Integer id; //属性要跟Type的域的名字一致
private String title;
private String content;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public Hello(Integer id, String title, String content) {
this.id = id;
this.title = title;
this.content = content;
}
public Hello() {
}
}
/**
* 创建文档-通过对象转换成JSON字符串
* fastjson String helloJson = JSON.toJSONString(hello);
* jackson
* ObjectMapper objectMapper=new ObjectMapper();
* String helloJson = objectMapper.writeValueAsString(hello);
*/
@Test
public void createDocumentByObject() throws UnknownHostException, JsonProcessingException {
TransportClient client = getClient(); //准备一个数据(文档)对象
Hello hello=new Hello(3,"ElasticSearch是一个基于Lucene的搜索服务器","ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用");
//将对象转换为JSON格式字符串 fastjson
/*String helloJson = JSON.toJSONString(hello);
System.out.println(helloJson);*/ //利用jackson转换
ObjectMapper objectMapper=new ObjectMapper();
String helloJson = objectMapper.writeValueAsString(hello);
//向索引库中添加文档数据
client.prepareIndex("y2170","hello","3").setSource(helloJson, XContentType.JSON).get();
client.close();
}
7.删除文档
/**
* 删除文档
*/
@Test
public void deleteDocument() throws UnknownHostException, JsonProcessingException {
TransportClient client = getClient(); //删除文档
client.prepareDelete("y2170","hello","4").get(); client.close();
}
8.查询文档-根据文档ID查询
/**
* 根据文档ID进行查询
*/
@Test
public void getDocumentByID() throws UnknownHostException, JsonProcessingException {
TransportClient client = getClient();
//执行查询,可查询多个
SearchResponse searchResponse = client.prepareSearch("y2170").setTypes("hello").setQuery(
QueryBuilders.idsQuery().addIds("1", "2")
).get();
//获取到查询结果
SearchHits hits = searchResponse.getHits();
//如果返回数据较多,默认进行分页,默认10条数据
System.out.println("获取到文档数据条目数:"+hits.getTotalHits());
//获取到文档数据
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()){
SearchHit hit = iterator.next();
System.out.println(hit.getSourceAsString());
System.out.println("content:"+hit.getSource().get("content"));
} client.close();
}
9.查询文档-根据Term关键词查询
/**
* 根据Term分词进行查询
*/
@Test
public void getDocumentByTerm() throws UnknownHostException, JsonProcessingException {
TransportClient client = getClient();
//执行查询,可查询多个
SearchResponse searchResponse = client.prepareSearch("y2170").setTypes("hello").setQuery(
QueryBuilders.termQuery("title","服务器")
).get();
//获取到查询结果
SearchHits hits = searchResponse.getHits();
//如果返回数据较多,默认进行分页,默认10条数据
System.out.println("获取到文档数据条目数:"+hits.getTotalHits());
//获取到文档数据
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()){
SearchHit hit = iterator.next();
System.out.println(hit.getSourceAsString());
System.out.println("content:"+hit.getSource().get("content"));
} client.close();
}
10.查询文档-根据QueryString查询文档
@Test
public void getDocumentByQueryString() throws UnknownHostException, JsonProcessingException {
TransportClient client = getClient();
//执行查询
SearchResponse searchResponse = client.prepareSearch("y2170").setTypes("hello").setQuery(
QueryBuilders.queryStringQuery("Solr是一个独立的企业级搜索应用服务器")
).get();
//获取到查询结果
SearchHits hits = searchResponse.getHits();
//如果返回数据较多,默认进行分页,默认10条数据
System.out.println("获取到文档数据条目数:"+hits.getTotalHits());
//获取到文档数据
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()){
SearchHit hit = iterator.next();
System.out.println(hit.getSourceAsString());
System.out.println("content:"+hit.getSource().get("content"));
} client.close();
}
11.查询数据的分页检索
ES当中默认检索数据是10条
/**
* 分页
*/
@Test
public void getDocumentByQueryStringlimit() throws UnknownHostException, JsonProcessingException {
TransportClient client = getClient();
//设置查询条件
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("y2170").setTypes("hello").setQuery(
QueryBuilders.queryStringQuery("服务器")
);
//加入分页规则 setFrom代表从那一条数据开始获取
searchRequestBuilder.setFrom(0).setSize(5);
SearchResponse searchResponse = searchRequestBuilder.get();
//获取到查询结果
SearchHits hits = searchResponse.getHits();
//如果返回数据较多,默认进行分页,默认10条数据
System.out.println("获取到文档数据条目数:" + hits.getTotalHits());
//获取到文档数据
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit hit = iterator.next();
System.out.println(hit.getSourceAsString());
System.out.println("content:" + hit.getSource().get("content"));
} client.close();
}
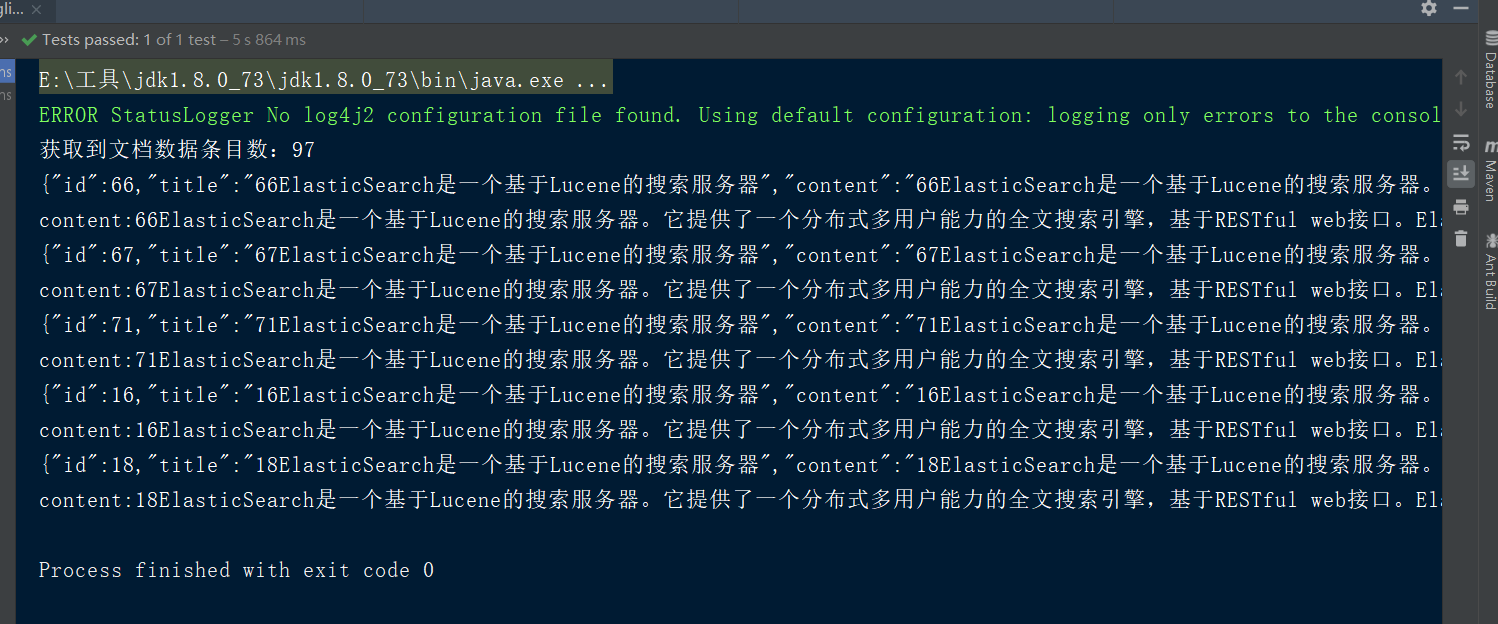
12.查询数据的高亮显示
执行查询数据之前设置高亮显示规则
1.设置高亮显示的域
2.设置高亮显示前缀
3.设置高亮显示后缀
执行查询
获取到高亮显示的数据
/**
* 高亮显示
*/
@Test
public void getDocumentByQueryHight() throws UnknownHostException, JsonProcessingException {
TransportClient client = getClient();
//设置查询条件
SearchRequestBuilder searchRequestBuilder = client.prepareSearch("y2170").setTypes("hello").setQuery(
QueryBuilders.termQuery("title", "服务器")
);
//加入分页规则 setFrom代表从那一条数据开始获取
searchRequestBuilder.setFrom(0).setSize(5);
//设置高亮规则
HighlightBuilder highlightBuilder=new HighlightBuilder();
//指定高亮显示的域
highlightBuilder.field("title");
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
searchRequestBuilder.highlighter(highlightBuilder);
//执行查询
SearchResponse searchResponse = searchRequestBuilder.get();
//获取到查询结果
SearchHits hits = searchResponse.getHits();
//如果返回数据较多,默认进行分页,默认10条数据
System.out.println("获取到文档数据条目数:" + hits.getTotalHits());
//获取到文档数据
Iterator<SearchHit> iterator = hits.iterator();
while (iterator.hasNext()) {
SearchHit hit = iterator.next();
System.out.println(hit.getSourceAsString());
/* System.out.println("content:" + hit.getSource().get("content"));*/ //获取高亮结果
Text[] titles = hit.getHighlightFields().get("title").getFragments();
for(Text text:titles){
System.out.println("高亮显示数据为:"+text);
}
} client.close();
}
数据到网页中,通过改变样式
就可达到高亮显示数据的目的
Java代码操作Elasticsearch的更多相关文章
- Elasticsearch入门系列~通过Java一系列操作Elasticsearch
Elasticsearch索引的创建.数据的增删该查操作 上一章节已经在Linux系统上安装Elasticsearch并且可以外网访问,这节主要通过Java代码操作Elasticsearch 1.创建 ...
- 使用Java客户端操作elasticsearch(二)
承接上文,使用Java客户端操作elasticsearch,本文主要介绍 常见的配置 和Sniffer(集群探测) 的使用. 常见的配置 前面已介绍过,RestClientBuilder支持同时提供一 ...
- Java代码操作HDFS测试类
1.Java代码操作HDFS需要用到Jar包和Java类 Jar包: hadoop-common-2.6.0.jar和hadoop-hdfs-2.6.0.jar Java类: java.net.URL ...
- 使用java代码操作Redis
1导入pom.xml依赖 <dependency> <groupId>redis.clients</groupId> <artifactId>jedis ...
- java代码操作Redis
1.导入需要的pom依赖 <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEn ...
- Java代码操作zookeeper
.personSunflowerP { background: rgba(51, 153, 0, 0.66); border-bottom: 1px solid rgba(0, 102, 0, 1); ...
- Java代码解决ElasticSearch的Result window is too large问题
调用ElasticSearch做分页查询时报错: QueryPhaseExecutionException[Result window is too large, from + size must b ...
- 分享知识-快乐自己:java代码 操作 solr
POM 文件: <!-- solr客户端 --> <dependency> <groupId>org.apache.solr</groupId> < ...
- 大数据之路week07--day01(HDFS学习,Java代码操作HDFS,将HDFS文件内容存入到Mysql)
一.HDFS概述 数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,因此迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统 ...
随机推荐
- nginx+lua在我司的实践
导读:nginx是一个高性能的反向代理服务器,lua是一个小巧的脚本语言,这两个的巧妙结合会擦出怎样的火花呢. 关键词:nginx,lua,nginx+lua 前言 nginx,lua,nginx+l ...
- Exchange邮件服务器安全
Exchange是由微软推出的用于企业环境中部署的邮件服务器.Exchange在逻辑上分为三个层次:网络层(network layer).目录层(directory layer).消息层(messag ...
- Docker容器到底是什么?
Docker是一个开源的应用容器引擎,是近些年最火的技术之一,Docker公司从Docker项目开源之后发家致富把公司商标改为了Docker,收购了fit项目,整合为了docker-compose,前 ...
- C# 把带有父子关系的数据转化为------树形结构的数据 ,以及 找出父子级关系的数据中里面的根数据Id
紧接上一篇,将List<Menu>的扁平结构数据, 转换成树形结构的数据 返回给前端 , 废话不多说,开撸! --------------------- 步骤: 1. 建 Menu ...
- 推荐算法之因子分解机(FM)
在这篇文章我们将介绍因式分解机模型(FM),为行文方便后文均以FM表示.FM模型结合了支持向量机与因子分解模型的优点,并且能够用了回归.二分类以及排序任务,速度快,是推荐算法中召回与排序的利器.FM算 ...
- ubuntu下怎么配置/查看串口-minicom工具
一.安装minicom工具: 可直接使用命令sudo apt-get install minicom来完成安装 上面的截图因为检测到我已经安装过了. 二.通过minicom工具配置串口: 1.启动mi ...
- 利用预测分析改进欠款催收策略,控制欺诈风险和信贷风险—— Altair Knowledge Studio 预测分析和机器学习
前提摘要 在数字经济新时代,金融服务主管正在寻求方法去细分他们的产品和市场,保持与客户的联系,寻找能够推动增长和收入的新市场,并利用可以增加优势和降低风险的新技术. 在拥有了众多可用数据之后,金融机构 ...
- HTML连载68-形变中心点、形变中心轴
一. 形变中心点介绍 <style> ul li { width: 100px; height: 100px; list-style: none; float:left; margin:0 ...
- 类加载机制与JVM调优命令
一.类加载过程 类加载:类加载器将.class字节码文件加载进Java虚拟机的内存中. 加载:在硬盘上查找并通过IO读入字节码文件 连接:执行校验.准备.解析(可选)步骤 校验:校验字节码文件的正确性 ...
- 【React Native】在网页中打开Android应用程序
React Native官方提供Linking库用于调起其他app或者本机应用.Linking的主要属性和方法有: 属性与方法 canOpenURL(url); 判断设备上是否有已经安装相应应用或可以 ...