MySQL 什么是索引?
该文为《 MySQL 实战 45 讲》的学习笔记,感谢查看,如有错误,欢迎指正
一、索引简介
索引就类似书本的目录,作用就是方便我们更加快速的查找到想要的数据。
索引的实现方式比较多,常见的有哈希表,有序数组,搜索树。
1.1 哈希表
哈希表是将数据以key-value的形式存储起来,简单来说就是将key通过哈希函数换算成数组中的一个确定的位置,将value存到这个位置去。当key比较多时,有可能换算出相同的位置,此时可以通过链表来解决。在查询时先找到位置,再对该位置的多个value进行遍历。
哈希表适合用于等值查询,由于是无序的,不适合用来做区间查询。
1.2 有序数组
有序数组在等值查询和区间查询上效率都很高。由于是有序的,可以通过二分法快速得到结果。也支持范围查询。但是也有一个缺点,如果要在中间插入一个数据,那么后面的所有记录都要向后挪一位,成本太高了。
因此,有序数组只适用于静态存储引擎。 例如我们要保存2019年的出生人口信息,就适合用有序数组。
1.3 搜索树
常见的搜索树有二叉,也有多叉。
二叉树的特点是:
- 每个节点的左儿子小于父节点,父节点又小于右儿子。
多叉树的特点是:
- 每个节点有多个儿子,儿子之间的大小保证从左到右递增。
由于索引不止存在内存中,还会写到磁盘上,而读磁盘越多,查询效率越慢。要降低读磁盘的次数的话,就要尽量访问尽量少的数据块。
假设数据块大小是N,树高为M,最多可以存的数据行数为 N^(M-1)(N 的 M-1 次方)。最多访问磁盘数为 M-1。
要使树高比较小,访问次数就少,N叉树的树高就小于二叉树。以 InnoDB 的一个整数字段索引为例,这个 N 差不多是 1200,这棵树高是 4 的时候,就可以存 1200 的 3 次方个值,这已经 17 亿行记录了。一个 10 亿行的表上一个整数字段的索引,查找一个值最多只需要访问 3 次磁盘。
数据库底层存储的核心就是基于这些数据模型的。每碰到一个新数据库,我们需要先关注它的数据模型,这样才能从理论上分析出这个数据库的适用场景。
二、InnoDB 的索引模型
- 在 InnoDB 中,表都是根据主键顺序以索引的形式存放的,这种存储方式的表称为
索引组织表。 - InnoDB 使用了 B+ 树索引模型,所以数据都是存储在 B+ 树中的。
因此,每一个索引在 InnoDB 里面对应一棵 B+ 树。
2.1 索引分类
根据字段约束,分为主键索引和普通索引;根据字段内容是否可重复,分为唯一索引和非唯一索引。
主键索引
主键是一种约束,一个表中只能有一个主键;
主键可以是多个列;
主键可以被其它表引用为外键使用;
主键索引可以理解为非空字段+唯一索引;
主键索引的叶子节点存的是整行数据。普通索引(二级索引)
一个表中可以有多个普通索引;索引可以有多列;
普通索引的叶子节点内容是主键的值;唯一索引
字段内容不能重复,但是可以为空;
一个表中可以有多个唯一索引;
不能做外键使用;非唯一索引
字段内容允许重复;
下面以表为例,建表语句:
mysql> create table T(
id int primary key,
k int not null,
name varchar(16),
index (k))engine=InnoDB;
表中 R1~R5 的 (ID,k) 值分别为 (100,1)、(200,2)、(300,3)、(500,5) 和 (600,6),两棵树的示例示意图如下:
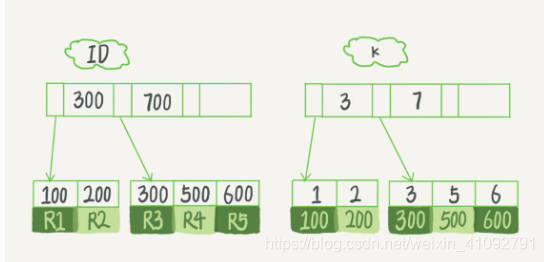
id字段为主键索引,主键索引的字段是不会重复的,必定是唯一索引;
k字段为普通索引,k的值允许重复,因此是非唯一索引。
2.2 回表操作
分析下面 2 条 SQL 语句:
select * from T where ID=500。此时用到的是主键索引,因此直接从索引中返回了整行记录,只需要搜索ID这棵 B+ 树。select * from T where k=5。此时用到的是普通索引,需要先搜索k索引树,得到ID = 500,再根据500到ID索引树搜索一次。这种需要返回主键索引树搜索的过程,叫做回表。
以上两条 SQL 语句返回的结果是一样的,但是效率却不一样,因为第 2 条 SQL 语句有一次回表操作,效率会慢很多,因此,要尽量避免回表操作,多使用主键查询。
2.3 页的分裂与合并
还是以上表为例,如果我们要插入一个数据,ID 值为 700,则只需要在 R5 后面新增加 1 条记录即可。如果插入的值 ID 为 400,那就需要逻辑上挪动后面的数据,空出位置。
如果恰好 R5 所在的数据页已经满了,那么就需要申请一个新的数据页,并且将 R5 挪过去,这个情况就叫做页分裂。
数据页中并不是要利用率达到 100% 才会申请新的数据页。也不是说只要有数据删除,那么后一页的数据就会顺补到前一页,这样太浪费性能了。数据页有一个利用率,假设分裂是80%,合并是 50%。只要利用率达到了 80%,就会申请一个新的数据页。如果删除数据比较多,利用率低于 50% 了,就会把后一页的数据合并过来。
如何避免页分裂造成的性能消耗?常见做法是在表中,设置一个自增长的 id 主键,这个字段不能和业务相关。自增主键的定义:NOT NULL PRIMARY KEY AUTO_INCREMENT。
这样每次插入数据,如果不指定 id 值,就会自增长到最后,因为和业务无关,所以没必要去指定 id 值。这样可以避免出现页分裂。
三、索引的一些特点
3.1 覆盖索引
还是以上表为例,执行以下 SQL 语句,分析执行过程:
mysql> select * from T where k between 3 and 5;
- 在普通索引
k上遍历,得到k=3对应的ID值300; - 通过
ID=300去主键索引上取得整行记录R3; - 继续向后遍历
k,得到k=5对应的ID值500; - 通过
ID=500去主键索引上取得整行记录R5; - 继续向后遍历
k,发现k=6,不满足between条件,循环结束。
可以看到,这个过程读了k索引树的 3 条记录(步骤 1,3,5), 回表了2次(步骤2,4)。
如果我们换成以下 SQL 语句:
mysql> select ID from T where k between 3 and 5;
由于 ID已经在k索引树上了,因此可以直接返回结果,不用回表。这种索引中已经覆盖了我们要查询的数据,叫做覆盖索引。
覆盖索引可以减少树的搜索次数(没有回表过程),显著提高查询性能。
3.2 关于扫描行数
MySQL 认为上述操作扫描的行数是 2 行,因为在索引中查数据,是在引擎层的操作。而 Server 层最后只拿到了 2 条记录,因此 MySQL 认为只扫描了 2 行。
那么如何看扫描函数呢?有 2 种方法:
- 使用
explain查看预计扫描行数
mysql> explain select * from t where a between 1000 and 2000;
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
| 1 | SIMPLE | t | range | a | a | 5 | NULL | 1000 | Using index condition |
+----+-------------+-------+-------+---------------+------+---------+------+------+-----------------------+
1 row in set (0.01 sec)
mysql>
可以看到使用了索引 key=a,预计扫描行数rows=1000。
- 将慢日志记录时间设置为 0 ,直接在慢日志中查看扫描行数
# Time: 191228 13:03:16
# User@Host: federated[federated] @ [60.191.76.22] Id: 177
# Query_time: 31.211439 Lock_time: 0.000059 Rows_sent: 0 Rows_examined: 95324
SET timestamp=1577509396;
CALL Z10004();
可以看到,扫描行数为Rows_examined: 95324
3.3 最左前缀原则
举一个例子来理解最左前缀原则,假设有一个联合索引(name,age)如下:
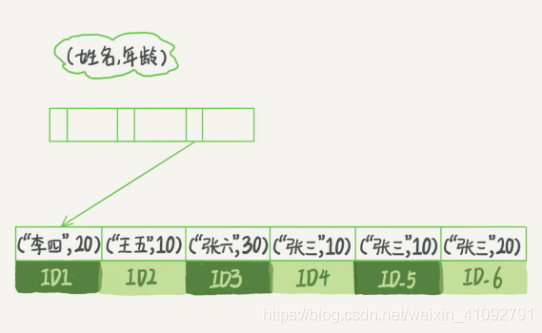
可以看到,索引顺序先按照第一个字段排序,再按照第二个字段。
假设我们要查询所有名为张三的数据。可以快速定位到ID4,再依次向后遍历。如果要查询所有姓张的(where name like '张%'),也能用到索引,先定位到ID3,再依次向后遍历,直到不满足条件为止。
不只是索引的全部定义,只要满足最左前缀,就可以利用索引来加速检索。这个最左前缀可以是联合索引的最左 N 个字段,也可以是字符串索引的最左 M 个字符。
在建立联合索引时,如何确定字段的前后顺序呢?
第一原则,如果通过调整顺序,可以少维护一个索引,那么这个顺序往往就是需要优先考虑采用的。
比如,已经有了一个(a, b)索引,就不必再建立一个 a 索引了。考虑磁盘空间占用大小。
比如,(name, age) 索引加上 age 索引,和 (age, name) 索引加上 name 索引。这两种情况,我们就要考虑占用空间了。选择占用空间小的。
由于name 字段比 age 字段大,因此我们选择(name, age) 索引加上 age 索引。
3.4 索引下推
索引下推功能是在 MySQL 5.6 引入的,目的是减少回表次数。
还是以市民表的联合索引(name, age)为例。如果现在有一个需求:检索出表中“名字第一个字是张,而且年龄是 10 岁的所有男孩”。那么,SQL 语句是这么写的:
mysql> select * from tuser where name like '张%' and age=10 and ismale=1;
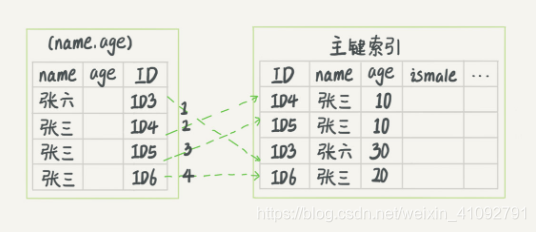
- 没有索引下推
先定位到ID3,然后回表到主键索引,找出对应的数据行,判断是否符合and age=10 and ismale=1。最终要回表 4 次(ID3,ID4,ID5,ID6),返回的结果只有 ID4,ID5。
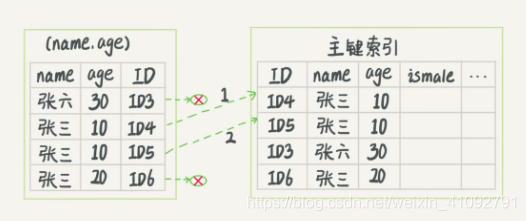
- 索引下推
在回表之前,会先判断这个联合索引上的后续字段是否满足条件,不满足则不进行回表操作。最终只用回表 2 次。
感谢阅读,有兴趣的小伙伴可以关注我的微信公众号DevOps探索之旅,大家一起学习进步

MySQL 什么是索引?的更多相关文章
- MySQL引擎、索引和优化(li)
一.存储引擎 存储引擎,MySQL中的数据用各种不同的技术存储在文件(或者内存)中.这些技术中的每一种技术都使用不同的存储机制.索引技巧.锁定水平并且最终提供广泛的不同的功能和能力.通过选择不同的技术 ...
- MySQL的InnoDB索引原理详解
摘要 本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节. InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档).本着高效学习的目的,本篇 ...
- MySQL和Lucene索引对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过 ...
- MySQL(五) MySQL中的索引详讲
序言 之前写到MySQL对表的增删改查(查询最为重要)后,就感觉MySQL就差不多学完了,没有想继续学下去的心态了,原因可能是由于别人的影响,觉得对于MySQL来说,知道了一些复杂的查询,就够了,但是 ...
- mysql优化之索引篇
对mysql优化是一个综合性的技术,主要包括 a: 表的设计合理化(符合3NF) b: 添加适当索引(index) [四种: 普通索引.主键索引.唯一索引unique.全文索引] c: 分表技术(水平 ...
- MySQL的InnoDB索引原理详解 (转)
摘要: 本篇介绍下Mysql的InnoDB索引相关知识,从各种树到索引原理到存储的细节. InnoDB是Mysql的默认存储引擎(Mysql5.5.5之前是MyISAM,文档).本着高效学习的目的,本 ...
- Mysql 复合键索引性能
数据库的常见的索引一般是单个字段,如果多个字段的组合,那么就组成了复合索引.对于组合索引,如果 对其中一字段做为条件查询,会出现什么情况呢? 一.例子 mysql> show create ta ...
- Mysql几种索引类型的区别及适用情况
如大家所知道的,Mysql目前主要有以下几种索引类型:FULLTEXT,HASH,BTREE,RTREE. 那么,这几种索引有什么功能和性能上的不同呢? FULLTEXT 即为全文索引,目前只有MyI ...
- mysql 强制走索引
查询是数据库技术中最常用的操作.查询操作的过程比较简单,首先从客户端发出查询的SQL语句,数据库服务端在接收到由客户端发来的SQL语句后, 执行这条SQL语句,然后将查询到的结果返回给客户端.虽然过程 ...
- Mysql数据库的索引原理
写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库性能调优的起点.考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录.如果没有索引,查询将 ...
随机推荐
- 机器学习环境配置系列三之Anaconda
1.下载Anaconda文件 进入anaconda的官网 选择对应的系统 选择希望下载的版本(本人下载的是Anaconda 5.3 For Linux Installer Python 3.7 ver ...
- day04_IDEA、方法
day04_IDEA.方法 1.快捷输入 psvm:public static void main(String[] args){ } sout:System.out.print("&quo ...
- windows RabbitMQ安装与配置
windows RabbitMQ安装与配置 1.安装Erlang 下载地址: http://www.erlang.org/downloads 注意: 右键以管理员身份进行安装,否则将导致后续无法启动 ...
- oracle问题之死锁 (一)
[前言] 遇到 oracle 异常 和 解决实践 系列文章 整理分享 杂症一.oracle死锁 一.症状: 执行SQL或程序时,程序没有响应或SQL执行一直处于执行状态,没有成功,也没有报错. 二.病 ...
- Leetcode 题目整理-7 Remove Element & Implement strStr()
27. Remove Element Given an array and a value, remove all instances of that value in place and retur ...
- 跟Evan学Sprign编程思想 | Spring注解编程模式【译】
Spring注解编程模式 概况 多年来,Spring Framework不断发展对注解.元注解和组合注解的支持. 本文档旨在帮助开发人员(Spring的最终用户以及Spring Framework和S ...
- conCat()的应用
编写一个Java应用程序,从键盘读取用户输入两个字符串,并重载3个函数分别实现这两个字符串的拼接.整数相加和浮点数相加.要进行异常处理,对输入的不符合要求的字符串提示给用户: package com. ...
- 程序为什么开头总是PUSH EBP
因为对堆栈的操作寄存器有EBP和ESP两个.EBP是堆栈的基址,ESP一直指向栈顶(只要有PUSH动作,ESP就自动减小,栈的生长方向从大往小,不需要手动改变ESP.)所以要压入EBP,然后再用EBP ...
- POJ_1979_dfs
题目描述: 每组数据给你一张字符的图,'@'代表起点,'.'代表可走的路,'#'代表墙,求从起点出发,可到达的位置的数量,包括起点. 思路: dfs基础题,从起始点开始,每一次所在的点,只要不出界并且 ...
- 用MYSQL的存储过程创建百万级测试数据表
创建随机字符串函数,便于创建名称 DROP function if EXISTS rand_string; #创建一个指定字符个数的函数 create function rand_string(n I ...