如何构建日均千万PV Web站点(二) 之~缓存为王~
随着网站业务的不断发展,用户的规模越来越大;介于中国无比蹩脚复杂的网路环境;南电信;北联通;中间竟然只用一条链路进行互联通信!有研究表明,网站访问延迟和用户流失率正相关,网站访问速度越慢,用户越容易失去耐心而离开。为了提高更好的用户体验,留住用户,网站需要加速网站访问速度。如今主要的手段只有使用CDN和反向代理了;此时网站的架构应该是这样的:
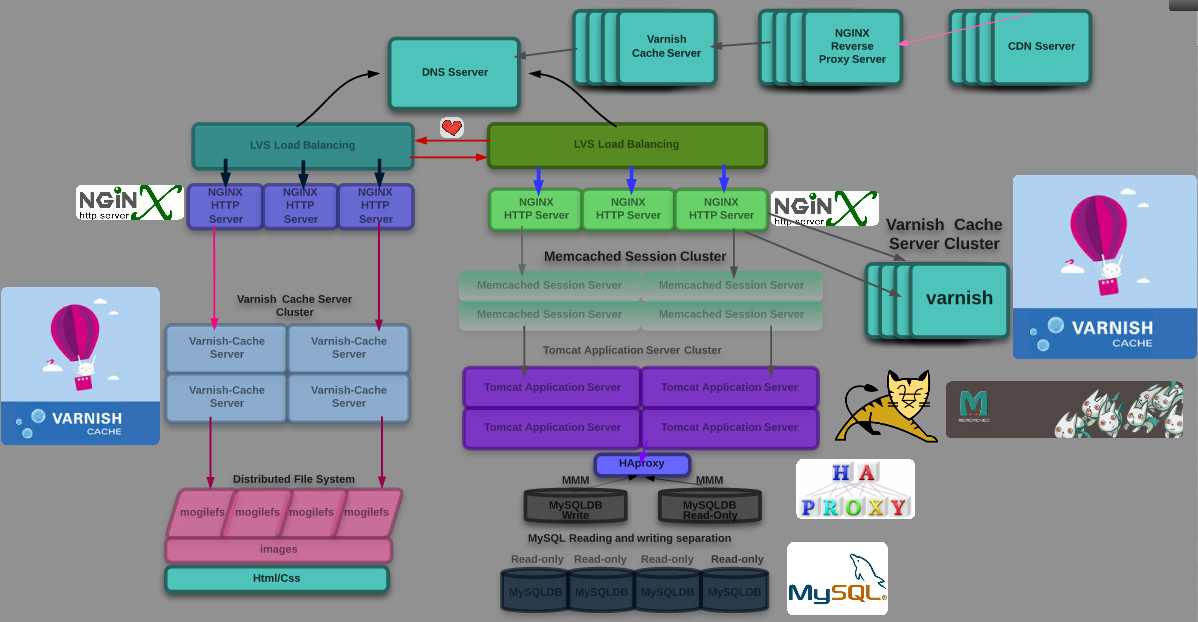
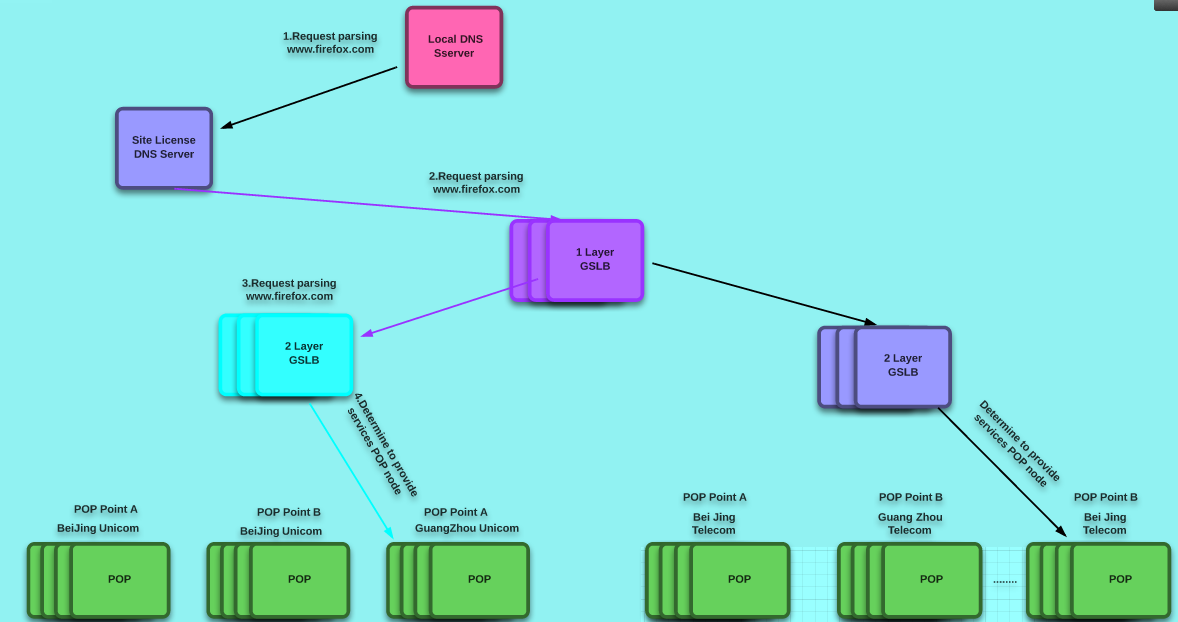
1、使用CDN和缓存服务器;CDN和反向代理的基本原理都是缓存数据,区别就在于CDN部署在网络提供商的机房,使用户在请求网站服务时,可以从距离自己最近的网络提供商机房获取数据;CDN的网络环境很复杂;所谓的多重负载均衡架构模型;不过它们一般会使用DNS作为全局负载均衡器;高效,并且能够根据客户端的源IP地址,来判断客户端的来源地区;将客户端的请求分配制本地负载均衡器;CDN架构图如下:从下图中可以看到,第一层GSLB和第二层GSLB都有各自的域组,第一层GSLB通过区域设置,将整个服务池分为电信的服务池和联通的服务池,第二层GSLB通过区域设置,将电信的服务池分为各省的服务池。这里的服务池就是提供相同业务的所有POP节点的组合,各省的服务池包含两个POP节点,POP节点也是GSLB在调度配置中所认识到的虚拟服务器.GSLB通过负载均很策略最终返回一个POP节点地址,用户直接访问POP节点来获取网站缓存内容。
而反向代理则部署在网站的中心机房中,当用户请求到达中心机房中后,首先访问的服务器就是反向代理服务器,如果反向代理服务器ui中缓存着用户请求的资源,就将其直接返回给用户。使用CDN和反向代理的目的都是尽早返回数据给用户,一方面加快用户的访问速度,另一方面也减轻了后端服务器的负载压力;
2、分布式数据库;分布式数据库是网站数据拆分的最后手段,只有在表单数据规模非常庞大的时候才使用;
3、服务器推送;将应用程序服务器;以及缓存服务器全部推送到运营商机房中;
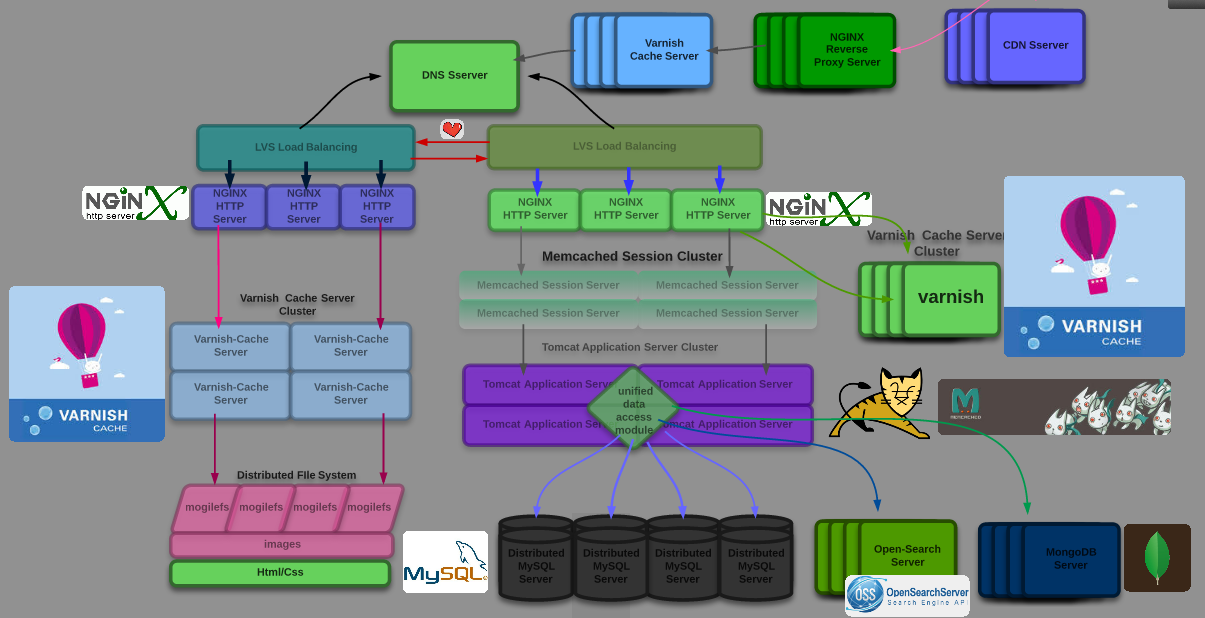
4、NoSQL以及搜索引擎的引入;随着网站的业务越来越复杂,对数据的存储和检索需求也越来越复杂,这时网站就必须得引入一些非关系型数据库技术如NoSQL(MongoDB,对于大数据量、髙并发、弱事务的互联网应用, MongoDB则是一个如瑞士军刀般的利器。尽管我不认同MongoDB会在所有场合完全取代MySQL,但我相信它完全可以满足Web 2.0和移动互联网应用的数据存储需求。MongoDB内置的水平扩展机制提供了从百万到十亿级别的数据量处理能力,其开箱即用的特性也大大降低了中小网站的运维成本),以及非数据库查询技术如搜索引擎;NoSQL和搜索引擎对可伸缩的分布式特性具有更好的支持。因此,此时的架构模型就如下图所示: 喜欢的话就点个赞呗;
Nginx 反向代理配置:

user nobody nobody;
worker_processes 4;
worker_rlimit_nofile 51200; error_log logs/error.log notice; pid /var/run/nginx.pid; events {
use epoll;
worker_connections 51200;
} http {
server_tokens off;
include mime.types; proxy_redirect off;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
client_max_body_size 20m;
client_body_buffer_size 256k;
proxy_connect_timeout 90;
proxy_send_timeout 90;
proxy_read_timeout 90;
proxy_buffer_size 128k;
proxy_buffers 4 64k;
proxy_busy_buffers_size 128k;
proxy_temp_file_write_size 128k; default_type application/octet-stream;
charset utf-8; client_body_temp_path /var/tmp/client_body_temp 1 2;
proxy_temp_path /var/tmp/proxy_temp 1 2;
fastcgi_temp_path /var/tmp/fastcgi_temp 1 2;
uwsgi_temp_path /var/tmp/uwsgi_temp 1 2;
scgi_temp_path /var/tmp/scgi_temp 1 2; ignore_invalid_headers on;
server_names_hash_max_size 256;
server_names_hash_bucket_size 64;
client_header_buffer_size 8k;
large_client_header_buffers 4 32k;
connection_pool_size 256;
request_pool_size 64k; output_buffers 2 128k;
postpone_output 1460; client_header_timeout 1m;
client_body_timeout 3m;
send_timeout 3m; log_format main '$server_addr $remote_addr [$time_local] $msec+$connection '
'"$request" $status $connection $request_time $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"'; open_log_file_cache max=1000 inactive=20s min_uses=1 valid=1m; access_log logs/access.log main;
log_not_found on; sendfile on;
tcp_nodelay on;
tcp_nopush off; reset_timedout_connection on;
keepalive_timeout 10 5;
keepalive_requests 100; gzip on;
gzip_http_version 1.1;
gzip_vary on;
gzip_proxied any;
gzip_min_length 1024;
gzip_comp_level 6;
gzip_buffers 16 8k;
gzip_proxied expired no-cache no-store private auth no_last_modified no_etag;
gzip_types text/plain application/x-javascript text/css application/xml application/json;
gzip_disable "MSIE [1-6]\.(?!.*SV1)"; upstream varnish 81 {
least_conn
server 172.16.100.103:81 weight=1 max_fails=2;
server 172.16.100.104:81 weight=1 max_fails=2;
server 172.16.100.105:81 weight=1 max_fails=2;
} server {
listen 80;
server_name www.firefox.com;
# config_apps_begin
root /data/webapps/htdocs;
access_log /var/logs/webapp.access.log main;
error_log /var/logs/webapp.error.log notice; location / { location ~* ^.*/favicon.ico$ {
root /data/webapps;
expires 180d;
break;
} if ( !-f $request_filename ) {
proxy_pass http://varnish 81;
break;
}
} error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
} server {
listen 8088;
server_name nginx_status; location / {
access_log off;
deny all;
return 503;
} location /status {
stub_status on;
access_log off;
allow 127.0.0.1;
allow 172.16.100.71;
deny all;
}
} }
转自:http://www.cnblogs.com/xiaocen/p/3726763.html
如何构建日均千万PV Web站点(二) 之~缓存为王~的更多相关文章
- 构建日均千万PV Web站点1
如何构建日均千万PV Web站点 (一) 其实大多数互联网网站起初的网站架构都是(Linux+Apache+MySQL+PHP). 不过随着时代的发展,科技的进步.互联网进入寻常百姓家的生活.所谓的用 ...
- 如何构建日均千万PV Web站点 (一)
其实大多数互联网网站起初的网站架构都是(Linux+Apache+MySQL+PHP). 不过随着时代的发展,科技的进步.互联网进入寻常百姓家的生活.所谓的用户的需求,铸就了一个个互联网大牛: htt ...
- 如何构建日均千万PV Web站点
http://www.cnblogs.com/xiaocen/p/3723839.html http://www.cnblogs.com/xiaocen/p/3726763.html http://w ...
- 如何构建日均千万PV Web站点 (三) Sharding
其实国内许多大型网站为了应对日益复杂的业务场景,通过使用分而治之的手段将整个网站业务分成不同的产品线,比如说国内那些大型购物交易网站它们都将自己的网站首页.商铺.订单.买家.卖家等拆分不同的产品线,分 ...
- 日均百万 PV 的站点如何做性能监测?试试「3M口罩」!
对很多开发者而言,如果网站的日流量达到百万级别,峰值 PV 也突破了 3 万,这样的站点在线下测试的时候总是让人心力交瘁.... 生产环境下的性能监测问题更是尤其让人头疼! 开发同学在想,运维人员也在 ...
- 006-优化web请求二-应用缓存、异步调用【Future、ListenableFuture、CompletableFuture】、ETag、WebSocket【SockJS、Stomp】
四.应用缓存 使用spring应用缓存.使用方式:使用@EnableCache注解激活Spring的缓存功能,需要创建一个CacheManager来处理缓存.如使用一个内存缓存示例 package c ...
- 【转】构建高性能WEB站点之 吞吐率、吞吐量、TPS、性能测试
内容参考:构建高性能WEB站点.pdf 一.吞吐率 我们一般使用单位时间内服务器处理的请求数来描述其并发处理能力.称之为吞吐率(Throughput),单位是"req/s".吞吐率 ...
- 构建高性能WEB站点之 吞吐率、吞吐量、TPS、性能测试
内容参考: 构建高性能WEB站点.pdf 一.吞吐率 我们一般使用单位时间内服务器处理的请求数来描述其并发处理能力.称之为吞吐率(Throughput),单位是 “req/s”.吞吐率特指Web服务器 ...
- 读书笔记-构建高性能Web站点
基本概念 带宽:通常说的带宽比如8M带宽,是指主机与互联网运营商的交换机之间的数据传输速度,因为数据链路层的流量是通过控制接收方实现的.而百兆网卡则是指网卡的发送速度为100Mbit/s,则是指网卡发 ...
随机推荐
- Android wifi powersave
使用高通平台的查看power save的功能. 一般是控制WCNSS_qcom_cfg.ini文件的两个参数gEnableBmps,gEnableImps. BMPS: Beacon mode pow ...
- wifi 通过omnipeek 查看 pmf是否生效
给android的wifi设备添加PMF支持时,抓取omnipeek分析. 从assoc req 中发现相关标志位没有使能,说明STA 没有使能PMF RSN Capabilities: %00000 ...
- e837. 设置JTabbedPane中卡片的颜色
// Create a tabbed pane JTabbedPane pane = new JTabbedPane(); // Set the text color for all tabs pan ...
- 如何解决#1045 - Access denied for user 'root'@'localhost' (using password: NO)问题
1. #1045 - Access denied for user 'root'@'localhost' (using password: NO) 解决方案 在phpMyAdmin中librarie ...
- (转)Integrating Intel® Media SDK with FFmpeg for mux/demuxing and audio encode/decode usages 1
Download Article and Source Code Download Integrating Intel® Media SDK with FFmpeg for mux/demuxing ...
- android 解决输入法键盘遮盖布局问题
/** * @param root 最外层布局,需要调整的布局 * @param scrollToView 被键盘遮挡的scrollToView,滚动root,使scrollToVie ...
- 核心动画——Core Animation
一. CALayer (一). CALayer简单介绍 在iOS中,你能看得见摸得着的东西基本上都是UIView,比方一个button.一个文本标签.一个文本输入框.一个图标等等.这些都是UIView ...
- QIIME1 聚OTU
qiime 本身不提供聚类的算法,它只是对其他聚otu软件的封装 根据聚类软件的算法,分成了3个方向: de novo: pick_de_novo_otus.py ...
- titlesplit源码
) UNSIGNED NOT NULL AUTO_INCREMENT, innserSessionid ), times ), channelType ), sourcetitle ), title ...
- koa中上传文件到阿里云oss实现点击在线预览和下载
比较好的在线预览的方法: 跳转一个新的页面,里面放一个iframe标签,或者object标签 <iframe src="xxx"></iframe> < ...