Spark SQL 编程
Spark SQL的依赖

Spark SQL的入口:SQLContext

官方网站参考 https://spark.apache.org/docs/1.6.2/sql-programming-guide.html#starting-point-sqlcontext
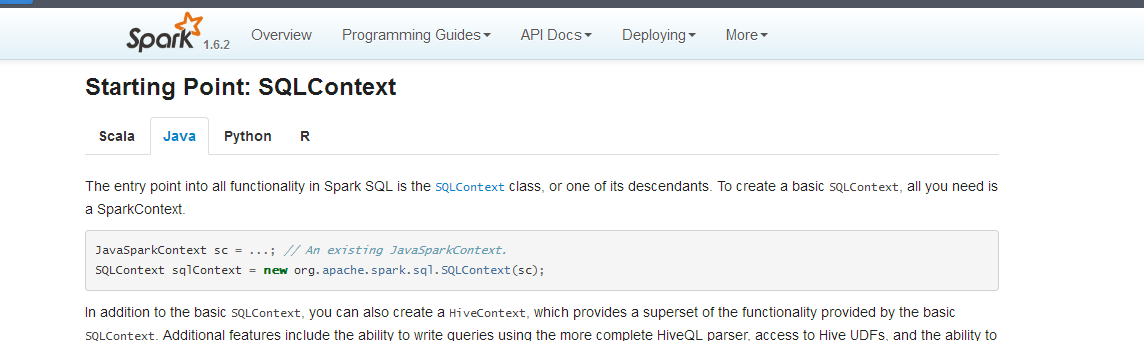
针对几种不同的语言来写。
Spark SQL的入口:HiveContext

SQLContext vs HiveContext

Spark SQL的作用与使用方式

Spark SQL支持的API
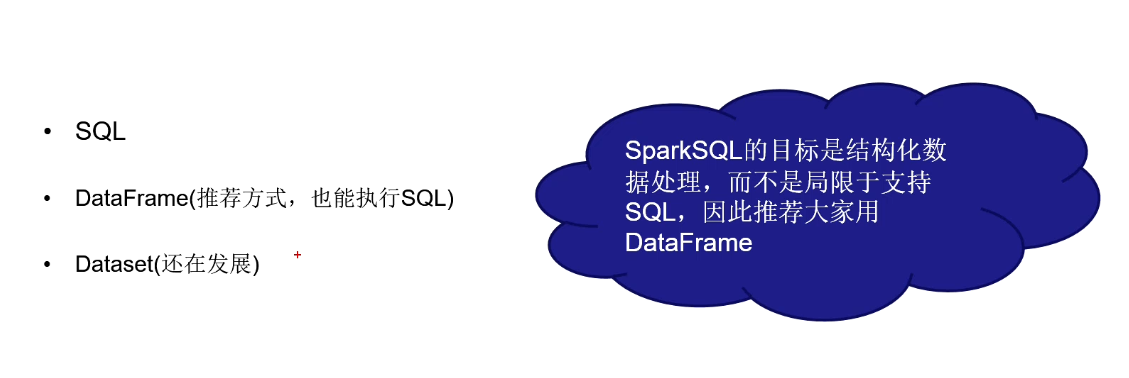

从程序中使用SparkSQL的基本套路

DataFrame--推荐使用

为什么要用DataFrame

SparkSQL数据源:从各种数据源创建DataFrame

SparkSQL数据源:RDD

SparkSQL数据源:Hive

sparkSQL数据源:Hive读写

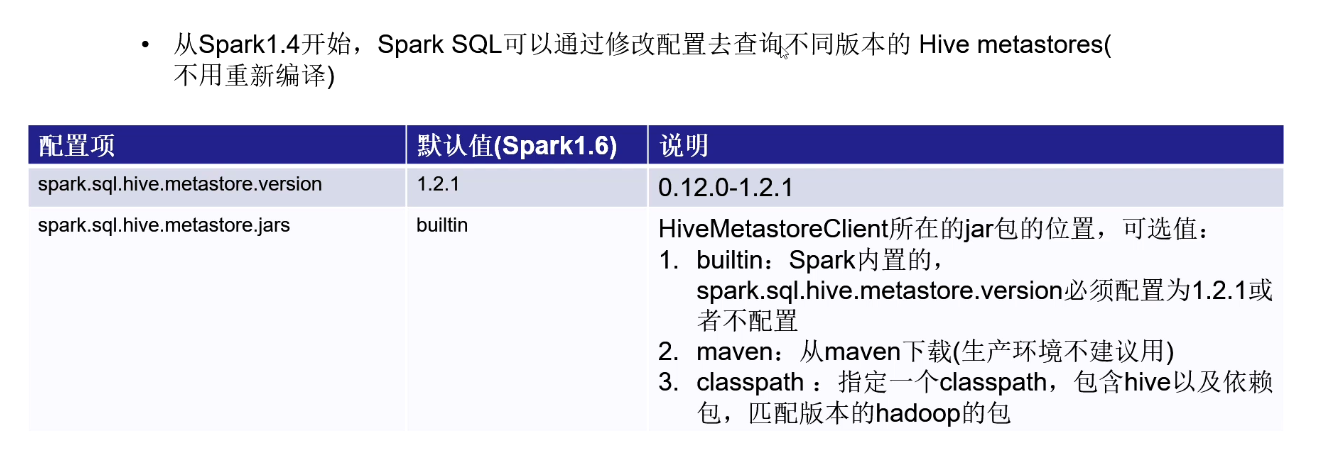
SparkSQL数据源:访问不同版本的metastore
SparkSQL数据源:Parquet

SparkSQL数据源:Parquet -- Partition Discovery

SparkSQL数据源:Json

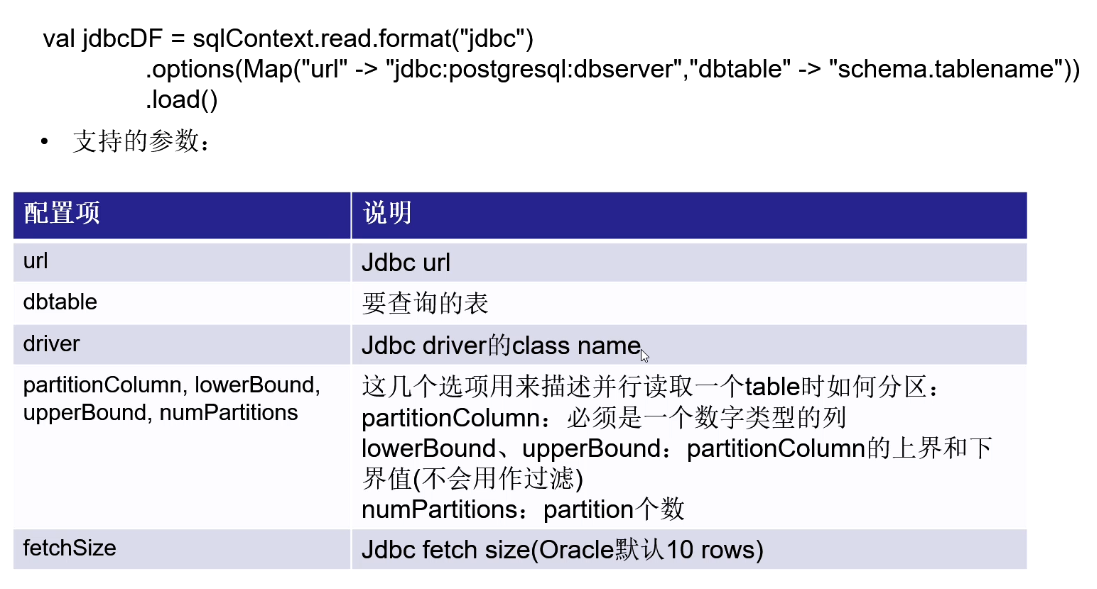
SparkSQL数据源:JDBC
DataFrame上的各种操作

Spark SQL 编程的更多相关文章
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- Spark SQL 编程API入门系列之SparkSQL的依赖
不多说,直接上干货! 不带Hive支持 <dependency> <groupId>org.apache.spark</groupId> <artifactI ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
- Spark SQL 编程初级实践
一.实验目的 (1) 通过实验掌握 Spark SQL 的基本编程方法: (2) 熟悉 RDD 到 DataFrame 的转化方法: (3) 熟悉利用 Spark ...
- spark SQL编程
1.编程实现将 RDD 转换为 DataFrame源文件内容如下(包含 id,name,age): 1,Ella,362,Bob,293,Jack,29 请将数据复制保存到 Linux 系统中,命名为 ...
- 第五周周二练习:实验 5 Spark SQL 编程初级实践
1.题目: 源码: import java.util.Properties import org.apache.spark.sql.types._ import org.apache.spark.sq ...
- spark实验(五)--Spark SQL 编程初级实践(1)
一.实验目的 (1)通过实验掌握 Spark SQL 的基本编程方法: (2)熟悉 RDD 到 DataFrame 的转化方法: (3)熟悉利用 Spark SQL 管理来自不同数据源的数据. 二.实 ...
- Spark SQL编程指南(Python)
前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询.它的核心是一个特殊类型的Spark RDD:SchemaRDD. SchemaRDD类似于传统关 ...
- 实验5 Spark SQL 编程初级实践
源文件内容如下(包含 id,name,age),将数据复制保存到 ubuntu 系统/usr/local/spark 下, 命名为 employee.txt,实现从 RDD 转换得到 DataFram ...
- Spark SQL编程指南(Python)【转】
转自:http://www.cnblogs.com/yurunmiao/p/4685310.html 前言 Spark SQL允许我们在Spark环境中使用SQL或者Hive SQL执行关系型查询 ...
随机推荐
- cobbler网络装机
cobbler网络装机 原理分析 cobbler简介 Cobbler通过将设置和管理一个安装服务器所涉及的任务集中在一起,从而简化了系统配置.相当于Cobbler封装了DHCP.TFTP.XINTED ...
- linux 读取物理寄存器
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #include <sys/mman.h ...
- spark 与 Hadoop 融合后 Neither spark.yarn.jars nor spark.yarn.archive is set
参考文献: http://blog.csdn.net/lxhandlbb/article/details/54410644 每次提交Spark任务到yarn的时候,总会出现uploading reso ...
- 如何从github上clone项目源码-linux
前言 github是目前较为流行的代码托管网站,linux系统是目前开发人员较为常用的操作系统.项目实现的过程中用到一些经典好用的源代码,可以从github上clone,本文主要介绍linux系统命令 ...
- unbtu使用笔记
安装fcitx输入法: sudo apt-get install fcitx-table-wbpy 再配置http://www.cnblogs.com/imsoft/p/4368550.html vi ...
- CodeForces - 285E: Positions in Permutations(DP+组合数+容斥)
Permutation p is an ordered set of integers p1, p2, ..., pn, consisting of n distinct positive in ...
- PHP vs Node.js
网络正在处于一个日新月异的发展时代.服务器端开发人员在选择语言的时候非常困惑,有长期占主导地位的语言,例如C.Java和Perl,也有专注于web开发的语言,例如Ruby.Clojure和Go.只要你 ...
- 谈ObjC对象的两段构造模式
前言 Objective-c语言在申请对象的时,需要使用两段构造(Two Stage Creation)的模式.一个对象的创建,需要先调用alloc方法或allocWithZone方法,再调用init ...
- java内存的分配和管理
常用的三个内存空间 栈内存 ,堆内存 ,方法区 栈内存存储的内容: 局部变量. 函数(栈中的局部变量,需要手动赋值.当变量,或者函数执行完毕,就自动被释放) 堆内存,存储的内容 :全局变量.数据容器. ...
- map和jsonObject 这2中数据结构之间转换
前台写json直接是:var array = [ ] ; 调用方法:array[index],若是对象,再[“key”] var obj = {''a'':123 , "b":&q ...