Hadoop学习笔记——WordCount
1.在IDEA下新建工程,选择from Mevan
GroupId:WordCount
ArtifactId:com.hadoop.1st
Project name:WordCount
2.pom.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>WordCount</groupId>
<artifactId>com.hadoop.1st</artifactId>
<version>1.0-SNAPSHOT</version> <repositories>
<repository>
<id>apache</id>
<url>http://maven.apache.org</url>
</repository>
</repositories> <dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-core</artifactId>
<version>1.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
</dependencies> <build>
<plugins>
<plugin>
<artifactId>maven-dependency-plugin</artifactId>
<configuration>
<excludeTransitive>false</excludeTransitive>
<stripVersion>true</stripVersion>
<outputDirectory>./lib</outputDirectory>
</configuration> </plugin>
</plugins>
</build>
</project>
3.main/java目录下新建WordCount.java文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import java.io.IOException;
import java.util.StringTokenizer; /**
* Created by common on 17-3-26.
*/
public class WordCount {
public static class WordCountMap extends
Mapper<LongWritable, Text, Text, IntWritable> { private final IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer token = new StringTokenizer(line);
while (token.hasMoreTokens()) {
word.set(token.nextToken());
context.write(word, one);
}
}
} public static class WordCountReduce extends
Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
context.write(key, new IntWritable(sum));
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(WordCount.class);
job.setJobName("wordcount"); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordCountMap.class);
job.setReducerClass(WordCountReduce.class); job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
}
}
4.在src同级目录下新建input目录,以及下面的test.segmented文件
test.segmented文件内容
aa
bb
cc
dd
aa
cc
ee
ff
ff
gg
hh
aa
4.在run configuration下设置运行方式为Application
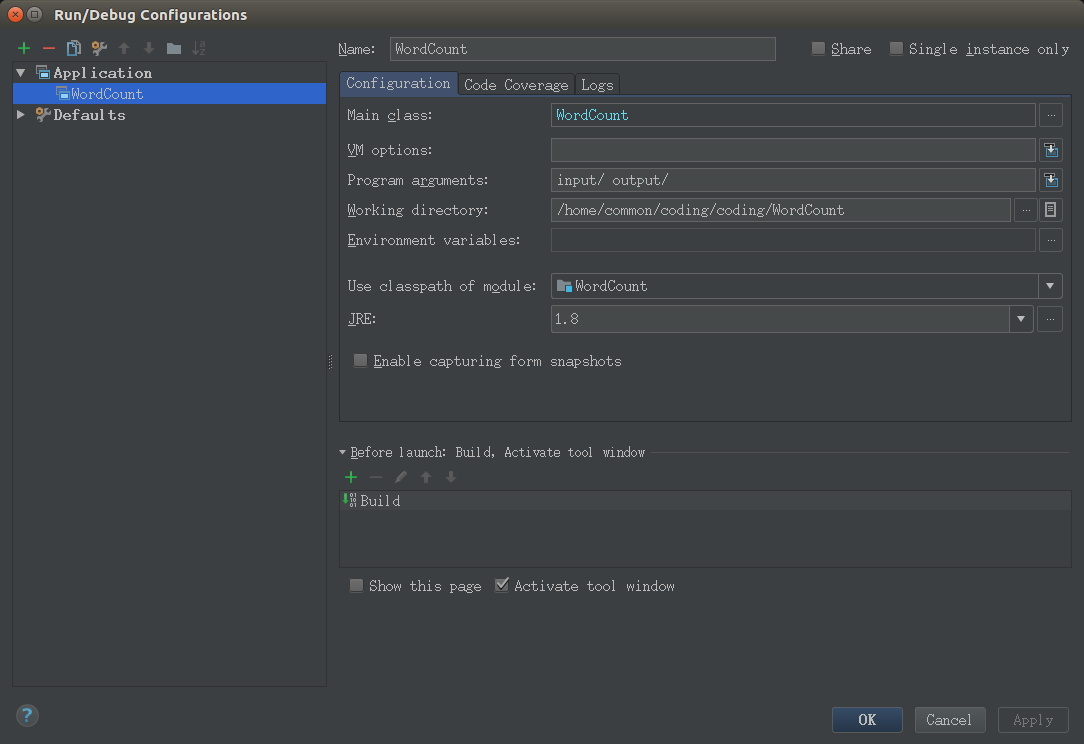
5.运行java文件,将会生成output目录,part-r-00000为运行的结果,下次运行必须删除output目录,否则会报错

Hadoop学习笔记——WordCount的更多相关文章
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(5) ——编写HelloWorld(2)
Hadoop学习笔记(5) ——编写HelloWorld(2) 前面我们写了一个Hadoop程序,并让它跑起来了.但想想不对啊,Hadoop不是有两块功能么,DFS和MapReduce.没错,上一节我 ...
- Hadoop学习笔记(2) ——解读Hello World
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
- Hadoop学习笔记(1) ——菜鸟入门
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(1)(转)
Hadoop学习笔记(1) ——菜鸟入门 Hadoop是什么?先问一下百度吧: [百度百科]一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序. ...
- Hadoop学习笔记(4) ——搭建开发环境及编写Hello World
Hadoop学习笔记(4) ——搭建开发环境及编写Hello World 整个Hadoop是基于Java开发的,所以要开发Hadoop相应的程序就得用JAVA.在linux下开发JAVA还数eclip ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
随机推荐
- jetty 6.1 笔记
download: http://dist.codehaus.org/jetty/jetty-6.1.22/ jetty 6.2 代码启动 必要jar包 lib --->> lib---& ...
- Oracle数据库密码过期
按照如下步骤进行操作:1.查看用户的proifle是哪个,一般是default: SQL>SELECT USERNAME,PROFILE FROM DBA_USERS; 2.查看指定概要文件(如 ...
- StringUtils.isEmpty和StringUtils.isBlank用法和区别
两个方法都是判断字符是否为空的.前者是要求没有任何字符,即str==null 或 str.length()==0:后者要求是空白字符,即无意义字符.其实isBlank判断的空字符是包括了isEmpty ...
- python 基础总结1
1.python简介特点: 是简单义学,有功能强大,高性能.面向对象,对动态输入的支持.解释性语言的本质,是大多数平台上理想的脚本语言. 简单,义学 免费, ...
- Mac OS X上如何实现到Linux主机的ssh免登陆
转载说明: 本文转载自 http://www.aips.me/mac-key-ssh-login-linux.html 生成密钥对 用密码登录远程主机,将公钥拷贝过去 done 第一步:生成密匙对执行 ...
- uboot下emmc内容烧写(拷贝)步骤
一.目的:嵌入式开发板,通过emmc上的内核文件加载启动linux操作系统,以及存放其他程序文件.需要将所需文件先写入emmc中. 二.总体步骤是:uboot启动后,进入linux下,将emmc分区并 ...
- Go Revel - server.go 源码分析
之前介绍了 Go Revel - main函数分析 http://www.cnblogs.com/hangxin1940/p/3263775.html 最后会调用 `revel.Run(*port)` ...
- 115道Java经典面试题(面中率最高、最全)
115道Java经典面试题(面中率最高.最全) Java是一个支持并发.基于类和面向对象的计算机编程语言.下面列出了面向对象软件开发的优点: 代码开发模块化,更易维护和修改. 代码复用. 增强代码的可 ...
- andrdoi示例项目SampleSyncAdapter分析
概述 在sdk目录下有个示例项目SampleSyncAdapter,演示了 用户授权和同步适配器的一些内容,是个学习的很好范例.我读了很久,很多地方没搞明白,先把理解的一些记录下来. 通过学习该示例, ...
- 移动端 图片切换 轮播(banner)
发现一个很好用的jquery控件 操作很简单 1.引入css <link href="/Resources/style/swiper.min.css" rel="s ...