Spark的CombineByKey
combineBykey关键是要明白里面的三个函数:
1. 当某个key第一次出现的时候,走的是第一个函数(createCombin);A function that creates a combiner. In the aggregateByKey function the first argument was simply an initial zero value. In combineByKey we provide a function that will accept our current value as a parameter and return our new value that will be merged with addtional values.
2. 当某个keyN次出现(N > 1)的时候,将会走第二个函数;The second function is a merging function that takes a value and merges/combines it into the previously collecte value(s).
3. 第三个函数是发生shuffle的时候,数据汇总的处理;处理逻辑一般和第二个函数一致;两个参数是来自于两个区的待累计处理参数。The third function combines the merged values together. Basically this function takes the new values produced at the partition level and combines them until we end up with one singular value.
突然来看这个combineByKey有些唐突,不过你要明白combine含义就是合并,可能会好理解.combinebyKey很多时候会和map做接续,combine数据后,在map对于数据进行二次处理,比如下面的例子里面的求平均值;combineByKey做得是累加,当需要对累加值做后续处理的时候,map就出场了;另外,combinByKey其实可以写成mapValues+reduceByKey;mapValues + reduceByKey是两轮便利,combineByKey其实是一轮便利(不算第三个函数)。但是两者只是类似,却不相同;
1.mapValues: 当一个遍历每个元素的时候,处理,参数是当前待处理元素;
2.reduceByKey,是遍历一遍之后,第二遍遍历处理,一般是做累计逻辑处理,第一个参数就是历史累计值,第二个参数是当前待处理元素;
代码如下:
object Main {
def main(args: Array[String]) {
val scores = List(
ScoreDetail("xiaoming", "Math", 98),
ScoreDetail("xiaoming", "English", 88),
ScoreDetail("wangwu", "Math", 75),
ScoreDetail("wangwu", "English", 78),
ScoreDetail("lihua", "Math", 90),
ScoreDetail("lihua", "English", 80),
ScoreDetail("zhangsan", "Math", 91),
ScoreDetail("zhangsan", "English", 80))
var sparkConf = new SparkConf
//sparkConf.setMaster("yarn-client")
sparkConf.setAppName("app")
var sc = new SparkContext(sparkConf)
//val scoresWithKey = for( i<-scores) yield (i.studentName, i)
val scoresWithKey = scores.map(score => (score.studentName, score))
var scoresWithKeyRDD = sc.parallelize(scoresWithKey).partitionBy(new HashPartitioner(3)).cache
scoresWithKeyRDD.foreachPartition(partition => {
//println("***** partion.length: " + partition.size + "************")
while (partition.hasNext) {
val score = partition.next();
println("name: " + score._1 + "; id: " + score._2.score)
}
})
val avg = scoresWithKeyRDD.combineByKey(
(x: ScoreDetail) => {
println("score:" + x.score + "name: " + x.studentName)
(x.score, 1)},
(acc: (Float, Int), x: ScoreDetail) =>{
println("second ground:" + x.score + "name: " + x.studentName)
(acc._1 + x.score, acc._2 + 1)
},
(acc1: (Float, Int), acc2: (Float, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
).map({ case (key, value) => (key, value._1 / value._2) })
/*
val avg = scoresWithKeyRDD.mapValues(value => (value.score, 1))
.reduceByKey((acc, item) => (acc._1 + item._1, acc._2 + item._2))
//.map(item => (item, item._2._1 / item._2._2)
.map({ case (key, value) => (key, value._1 / value._2) })
*/
avg.collect.foreach(println)
scoresWithKeyRDD.unpersist(true)
}
}
combineByKey的处理逻辑通过日志可以看到:
score:.0name: xiaoming
second ground:.0name: xiaoming
score:.0name: lihua
second ground:.0name: lihua
score:.0name: zhangsan
second ground:.0name: zhangsan
每个key只是走一次第一个函数;当同一个key第n次出现(n > 1)的时候,将会走第二个函数;这个和mapValues将会过遍历一遍,keyByValues再过一遍的逻辑还是不同的。
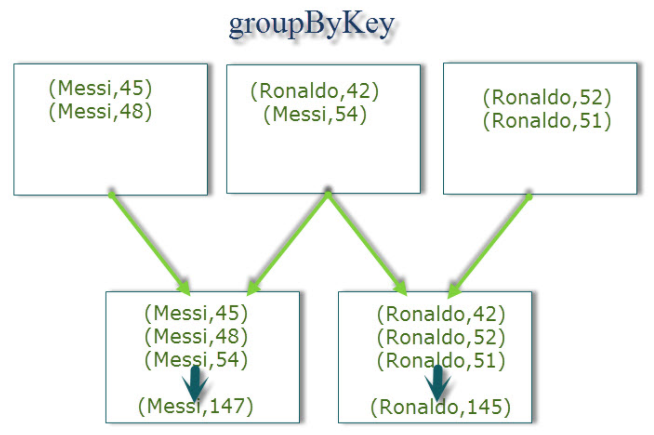
combineByKey的一个老对手是groupbyKey,这个说法其实不准确,reduceByKey才是groupByKey的老对手;因为无论是reduceByKey还是groupByKey,其实底层都是调用combinByKey;但是groupByKey将会导致大量的shuffle,因为groupByKey的实现逻辑是将各个分区的数据原封不动的shuffle到reduce机器,由reduce机器进行合并处理,见下图:
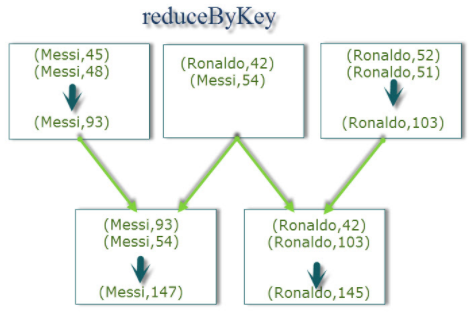
reduceByKey则是先将各个分区的数据进行合并(计算)处理后在shuffle到reducer机器;这样严重的减轻了数据传输的量。
Spark的CombineByKey的更多相关文章
- Spark入门(六)--Spark的combineByKey、sortBykey
spark的combineByKey combineByKey的特点 combineByKey的强大之处,在于提供了三个函数操作来操作一个函数.第一个函数,是对元数据处理,从而获得一个键值对.第二个函 ...
- Spark 的combineByKey函数
在Spark中有许多聚类操作是基于combineByKey的,例如group那个家族的操作等.所以combineByKey这个函数也是比较重要,所以下午花了点时间看来下这个函数.也参考了http:// ...
- Spark RDD——combineByKey
为什么单独讲解combineByKey? 因为combineByKey是Spark中一个比较核心的高级函数,其他一些高阶键值对函数底层都是用它实现的.诸如 groupByKey,reduceByKey ...
- spark之combineByKey
combineByKey def combineByKey[C](createCombiner: (V) => C, mergeValue: (C, V) => C, mergeCombi ...
- Spark实战系列目录
1 Spark rdd -- action函数详解与实战 2 Spark rdd -- transformations函数详解与实战(上) 3 Spark rdd -- transformations ...
- Spark入门(七)--Spark的intersection、subtract、union和distinc
Spark的intersection intersection顾名思义,他是指交叉的.当两个RDD进行intersection后,将保留两者共有的.因此对于RDD1.intersection(RDD2 ...
- Job 逻辑执行图
General logical plan 典型的 Job 逻辑执行图如上所示,经过下面四个步骤可以得到最终执行结果: 从数据源(可以是本地 file,内存数据结构, HDFS,HBase 等)读取数据 ...
- Spark API 之 combineByKey(一)
1 前言 combineByKey是使用Spark无法避免的一个方法,总会在有意或无意,直接或间接的调用到它.从它的字面上就可以知道,它有聚合的作用,对于这点不想做过多的解释,原因很简单, ...
- spark算子:combineByKey
假设我们有一组个人信息,我们针对人的性别进行分组统计,并进行统计每个分组中的记录数. scala> val people = List(("male", "Mobi ...
随机推荐
- LabVIEW之安装队列工具包AMC安装问题解决
LabVIEW之安装队列工具包AMC安装问题解决--VIPM无法连接LabVIEW 彭会锋 参考资料: http://www.labviewpro.net/forum_post_detail.php? ...
- 解决SecureCRT下spark-shell中scala无法删除问题
转自:http://blog.csdn.net/huanbia/article/details/51318278 问题描述 当使用SecureCRT来打开Spark-shell的时候,有时会出现如下问 ...
- UVA-10917 Walk Through the Forest (dijkstra+DP)
题目大意:n个点,m条边的无向图.一个人从起点到终点按照下面的走法:从A走向B当A到终点的最小距离比B到终点的最小距离大时.问从起点到终点有多少路径方案. 题目分析:先用dijkstra预处理出终点到 ...
- urllib2.HTTPError: HTTP Error 403: Forbidden
这个问题主要是没有headers,加入一些内容就可以了 示例: # -*- coding: UTF-8 -*- import urllib2 site= "http://www.nseind ...
- linux---网络相关配置,ssh服务,bash命令及优先级,元字符
- 二:临时配置网络(ip,网关,dns)+永久配置 临时配置: [root@nfs-server ~]# ifconfig ens32: flags=4163<UP,BROADCAST,RUN ...
- C# 设计模式巩固 - 单例模式
前言 设计模式的文章很多,所以此文章只是为了巩固一下自己的基础,说的不详细请见谅. 介绍 - 单例模式 官方定义:确保一个类只有一个实例,并提供一个全局访问点. 通俗定义:就是一个类只有一个单个实例. ...
- 设置tableview 右侧 索引字体的大小
- Draggable拖动
Draggable(拖动)组件 学习要点: 1.加载方式 2.属性列表 3.事件列表 4.方法列表 EasyUI中Draggable(拖动)组件的使用方法,这个组件不依赖于其他组件. 1.加载方式 / ...
- 辛星笔记——VIM学习篇(推荐阅读)
转载自:辛星和您一起学vim脚本第一节 如本文侵犯了您的版权,请联系windeal12@qq.com 这几天在网上看了辛星的一些vim教程博文,觉得很有收获,也很实用,适合入门,所以转载其中一篇留个网 ...
- APUE学习笔记——10 信号
信号的基本概念 信号是软件中断,信号提供了解决异步时间的方法. 每一中信号都有一个名字,信号名以SIG开头. 产生信号的几种方式 很多条件可以产生信号: 终端交互:用户 ...