redis笔记之两种持久化备份方式(RDB & AOF)
Redis支持的两种持久化备份方式(RDB & AOF)
redis支持两种持久化方式,一种是RDB,一种是AOF。
RDB是根据指定的规则定时将内存中的数据备份到硬盘上,AOF是在每次执行命令后命令本身记录下来,所以RDB的备份文件是一个二进制文件,而AOF的备份文件是一个文本文件。
1. RDB方式
RDB的备份是通过快照来完成的,当符合设定的条件时redis会将内存中的所有数据自动生成一份副本保存到硬盘上,这个保存的过程就是快照。
1.1 根据配置规则自动执行快照
这个条件在配置文件中指定,由两个参数所定义:时间窗口M和改动的键个数N,每当时间M内改动的键个数大于N时,则触发快照备份。
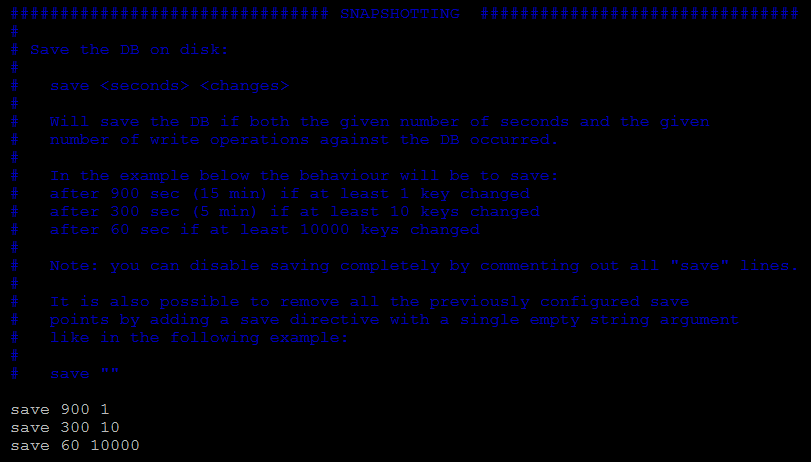
可以同时存在多个快照条件,条件之间是或的关系,也就是说只要有一个条件被触发就会执行快照备份。
save 900 1 : 在15分钟内有至少一个键被修改则触发。
save 300 10 : 在5分钟内至少有10个键被修改则触发。
sae 60 10000 : 在一分钟内有10000个键被修改则触发。
1.2 用户执行SAVE或者BGSAVE命令
save命令会让redis同步地执行快照操作,在快照执行的时候会阻塞所有来自客户端的请求,当数据库中的数据比较多时备份时间可能就比较长,就会导致服务器长时间无响应,所以此项在生产环境应该慎用。
需要手动执行快照备份的话应该使用bgsave命令,bgsave命令可以在后台异步的执行备份操作,在备份快照的同时服务器仍然能够相应客户端的请求。
既然bgsave那么好,为毛还要save呢?
save可以一直阻塞等到结果,但是因为bgsave是多线程,在执行bgsave的时候只是启动一个线程去备份,我们并不能确定备份到底有没有成功呢?当指定bgsave的时候总是返回OK,这个OK表示的是开始执行快照操作并不是快照操作执行成功,要想知道快照是否执行成功,可以通过lastsave命令获取最近一次成功执行快照的时间,返回结果是一个unix时间戳。

1.3 执行FLUSHALL命令
当执行flushall的时候redis会清空当前仓库的所有数据,只要自动快照条件不为空的话在清空之前就要执行一次备份,当没有定义快照触发条件的时候执行flushall不会执行备份。
1.4 执行复制时
当设置了主从模式时,redis会在初始化时自动进行快照。
1.5 快照的原理
redis默认会将快照放到当前进程工作目录的dump.db文件中,可以通过配置dir和dbfilename两个参数来指定要保存到的路径和文件名。


为了节省空间,RDB文件是经过压缩的,在硬盘上的占用空间会小于在内存中的占用空间,可以通过rdbcompression参数来禁用掉压缩(可节省些许cpu占用吧)

rdb快照备份的过程(copy-on-write):
1. redis用fork函数复制一份当前进程的副本。
2. 父进程继续接受客户端发来的命令,子进程开始将内存中的数据写到硬盘的临时文件。
3. 当子进程备份完的时候将子进程和父进程的数据合并。
(没看过源代码,上面抄来的... = = )
注: copy-on-write是一种比较常用的备份策略。
2. AOF(Append Only File)方式
aof一般用于对数据丢失容忍度不高的情况下,用于对数据保存要求较高的场景。
2.1 开启AOF
默认情况下redis是没有开启aof的,使用appendonly来开启(appendonly yes):
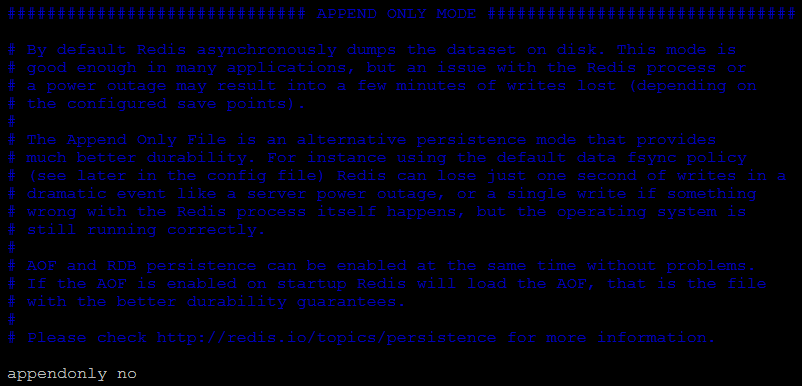
可以通过appendfilename来指定aof文件的名字,默认的名字是【appendonly.aof】:

2.2 AOF的实现
aof文件以纯文本的形式记录了redis执行的命令,它只是傻傻的把执行过的命令往aof文件中添加并不知道添加的是个什么,这样就可能存在一个问题,比如下面连着的两条命令:
set foo bar
set foo baar
在aof文件中会忠实的记录下整个改变的过程,而不是机智的只存储一个set foo baar。
这样子的话aof文件中就可能会存在冗余命令,所以可以设定一个触发条件,设定每到一定条件时就让redis优化aof文件,优化aof文件的策略是与之前aof的内容无关,而是跟当前内存中的数据有关(在内存中都已经不存在的命令没有存在必要了,对于已经存在的只保留最后一次的操作就可以啦),进行设定的参数:
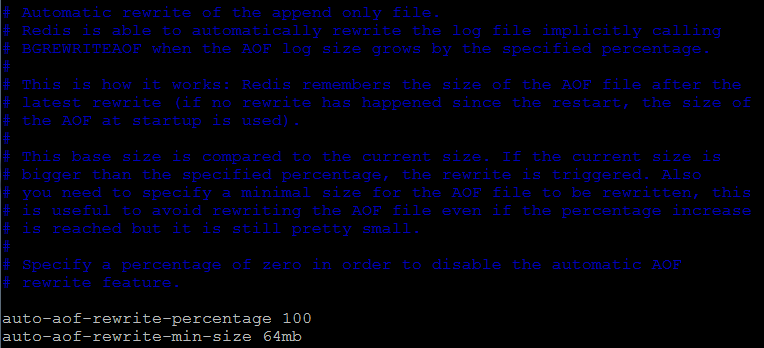
auto-aof-rewrite-percentage : 当前的aof文件超过上一次重写时大小的百分之多少时再次进行重写,如果之前没有重写过,则以启动时的aof文件大小为依据。
auto-aof-rewrite-min-size : 限制允许重写aof文件的最小的大小,比如当aof文件很小的时候有冗余也没关系的,我们就不要再去抽出资源来重写它啦,这个是aof文件小于64M则不会进行重写。
2.3 同步硬盘数据
每次同步数据库的内容时redis都会将命令记录到aof文件中,但是事实上我们都知道硬盘是有一个写缓冲区的,要写的东西并不会立即就写到硬盘上而是现在硬盘的缓冲区内待一会儿,等到攒够了人头再“拼车”一起写入硬盘,在默认情况下操作系统每30秒会执行一次同步操作,会将硬盘缓冲区的内容真正的写入到硬盘,但是在这30秒内如果发生了什么人力不可抗拒因素啥的这数据可是就丢了哇,我们用aof就是为了尽量不丢失数据,所以有一个选项appendfsync用来指定同步的策略:
always : 表示每次都会写入硬盘,这是最安全也是最慢的方式(请确保丫硬盘够给力....)。
everysec : 每秒同步一次(默认)
no : 不会主动进行同步,让操作系统看着办吧,操作系统默认的是每30秒将硬盘缓冲区内的数据同步到的硬盘一次。
RDB和AOF可以同时配置的,当同时开启的时候启动的时候redis会加载AOF文件,因为通常情况下AOF持久化保存的数据更完整一些。
参考资料:
1. 《redis入门指南》 第二版
redis笔记之两种持久化备份方式(RDB & AOF)的更多相关文章
- redis两种持久化方式的优缺点
redis两种持久化的方式 RDB持久化可以在指定的时间间隔内生成数据集的时间点快照 AOF持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集,AOF文件中全部以 ...
- redis的两种持久化的机制,你真的了解么?
redis提供了两种持久化的机制 RDB和AOF机制 RDB(redis Database):RDB保存某一个时间点之前的快照数据. AOF(Append-Only File):指所有的命令行记录以r ...
- Redis两种持久化策略分析
Redis专题地址:https://www.cnblogs.com/hello-shf/category/1615909.html SpringBoot读源码系列:https://www.cnblog ...
- Redis系列之----Redis的两种持久化机制(RDB和AOF)
Redis的两种持久化机制(RDB和AOF) 什么是持久化 Redis的数据是存储在内存中的,内存中的数据随着服务器的重启或者宕机便会不复存在,在生产环境,服务器宕机更是屡见不鲜,所以,我们希望 ...
- 9. 图解分析Redis的RDB和AOF两种持久化机制的原理
1.RDB和AOF两种持久化机制的介绍 2.RDB持久化机制的优点3.RDB持久化机制的缺点4.AOF持久化机制的优点5.AOF持久化机制的缺点6.RDB和AOF到底该如何选择 我们已经知道对于一个企 ...
- 10.Redis的RDB和AOF两种持久化机制的优劣势对比
1.RDB和AOF两种持久化机制的介绍 2.RDB持久化机制的优点3.RDB持久化机制的缺点4.AOF持久化机制的优点5.AOF持久化机制的缺点6.RDB和AOF到底该如何选择 我们已经知道对于一个企 ...
- Redis学习一:Redis两种持久化机制
申明 本文章首发自本人公众号:壹枝花算不算浪漫,如若转载请标明来源! 感兴趣的小伙伴可关注个人公众号:壹枝花算不算浪漫 22.jpg 前言 Redis是基于内存来实现的NO SQL数据库,但是我么你都 ...
- redis的RDB和AOF两种持久化机制
思维导图:我的redis基础知识汇总 RDB持久化机制的优点 (1)RDB会生成多个数据文件,每个数据文件都代表了某一个时刻中redis的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的 ...
- 分析RedisRDB和AOF两种持久化机制的工作原理及优劣势
一.RDB和AOF两种持久化机制的介绍 RDB持久化机制,对redis中的数据执行周期性的持久化 AOF机制对每条写入命令作为日志,以append-only(追加)的模式写入一个日志文件中,在redi ...
随机推荐
- BETA预发布演示视频
视频连接:优酷http://v.youku.com/v_show/id_XMTgxMjQxMjc0NA==.html?from=y1.7-2
- PAT 甲级 1144 The Missing Number
https://pintia.cn/problem-sets/994805342720868352/problems/994805343463260160 Given N integers, you ...
- 在MFC中显示cmd命令行
添加函数 void InitConsoleWindow1() { ; FILE* fp; AllocConsole(); nCrt = _open_osfhandle((long)GetStdHand ...
- 在linux下编译线程程序undefined reference to `pthread_create'
由于是Linux新手,所以现在才开始接触线程编程,照着GUN/Linux编程指南中的一个例子输入编译,结果出现如下错误:undefined reference to 'pthread_create'u ...
- js 实现路由功能
class Router { constructor() { this.routes = [] } handle(pattern, handler) { this.routes.push({ patt ...
- 编码转换,基础,copy
阅读目录 编码转换 基础补充 深浅拷贝 文件操作 一,编码转换 1. ASCII : 最早的编码. ⾥⾯有英⽂⼤写字⺟, ⼩写字⺟, 数字, ⼀些特殊字符. 没有中⽂, 8个01代码, 8个bit, ...
- 【bzoj5174】[Jsoi2013]哈利波特与死亡圣器 二分+树形dp
题目描述 给你一棵以1为根的有根树,初始除了1号点为黑色外其余点均为白色.Bob初始在1号点.每次Alice将其中至多k个点染黑,然后Bob移动到任意一个相邻节点,重复这个过程.求最小的k,使得无论B ...
- The Toll! Revisited UVA - 10537(变形。。)
给定图G=(V,E)G=(V,E),VV中有两类点,一类点(AA类)在进入时要缴纳1的费用,另一类点(BB类)在进入时要缴纳当前携带金额的1/20(不足20的部分按20算) 已知起点为SS,终点为TT ...
- Django模板语言循环字典
1. 对于字典,可以有下列用法: {% for row in user_dict.keys %} {% for row in user_dict.values %} {% for row in use ...
- 从块级元素和行内元素的分析到bfc的布局理解
接口和属性介绍 播放器提供了progressMakers属性,是一个数组类型,每一条记录包含offset时间和text打点的内容,还可以包含其他属性,此属性用于告诉播放器进度条打点记录,记录内容属性说 ...