Zookeeper概述和基本概念
一、Zookeeper背景
随着互联网技术的发展,企业对计算机系统的计算,存储能力要求越来越高,各大IT企业都在追求高并发,海量存储的极致,在这样的背景下,单纯依靠少量高性能单机来完成计算机,云计算的任务已经无法满足需求,企业的IT架构逐渐由集中式往分布式过渡。所谓的分布式是指:把一个计算任务分解成若干个计算单元,并分派到不同的计算机中去执行,最终汇总计算结果的过程。
二、Zookeeper概述
Zookeeper是源代码开放的分布式协调服务,是一个高性能的分布式数据一致性的解决方案,它将那些复杂的,容易出错的分布式一致性服务封装起来。用户可以通过调用Zookeeper提供的接口来解决一些分布式应用中的实际问题。
三、Zookeeper典型应用场景
(1)数据发布/订阅
数据的发布与订阅,顾名思义就是一方把数据发布出来,另一方通过某种手段获取。
通常数据发布与订阅有两种模式:推模式和拉模式,推模式一般是服务器主动往客户端推送信息,拉模式是客户端主动去服务端请求目标数据(通常采用定时轮询的方式)
Zookeeper采用两种方式互相结合:发布者将数据发布到Zookeeper集群节点上,订阅者通过一定的方法告诉Zookeeper服务器,自己对哪个节点的数据感兴趣,那么在服务端数据发生变化时,就会通知客户端去获取这些信息。
(2)负载均衡
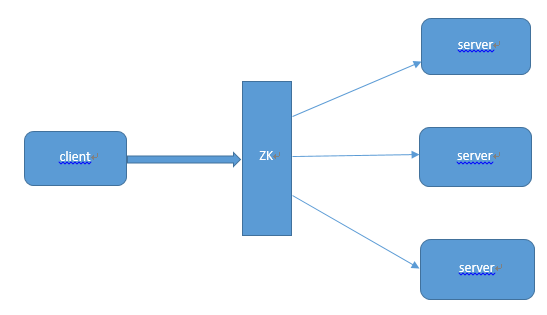
首先在服务端启动的时候,把自己在zookeeper服务器上注册成一个临时节点。zookeeper拥有两种形式的节点,一种是临时节点,一种是永久节点。这两种节点后面的博客会有较为详细的介绍。注册成临时节点后,再服务端出问题时,节点会自动的从zookeeper上删除,如此zookeeper服务器上的列表就是最新的可用的列表。
客户端在需要访问服务器的时候首先会去Zookeeper获得所有可用的服务端的连接信息。
客户端通过一定的策略(如随机)选择一个与之建立连接。
当客户端发现连接不可用时,会再次从zookeeper上获取可用的服务端连接,并同时删除之前获取的连接列表。
(3)命名服务
提供名称的服务。如一般使用较多的有两种id,一种是数据库自增长id,一种是UUID,两种id都有局限,自增长id仅适合在单表单库中使用,uuid适合在分布式系统中使用但由于id没有规律难以理解。而ZK提供了一定的接口可以用来获取一个顺序增长的,可以在集群环境下使用的id。
(4)分布式协调,通知,心跳服务
在分布式服务系统中,我们常常需要知道哪个服务是可用的,哪个服务是不可用的,传统的方式是通过ping主机来实现的,ping得200的结果说明说明该服务是OK的。
而在使用 zookeeper时,可以将所有的服务都注册成一个临时节点,我们判断一个服务是否可用,只需要判断这个节点是否在zookeeper集群中存在就可以了,不需要直接去连接和ping服务所在主机,减少系统的复杂度和对服务主机的压力。
四、Zookeeper优势
(1)源代码开放
(2)高性能,易用稳定,该优势已在众多分布式系统中得到验证
(3)有着广泛的应用,并且与众多大数据相关技术能实现良好的融合开发。
Zookeeper概述和基本概念的更多相关文章
- 十四、Hadoop学习笔记————Zookeeper概述与基本概念
顺序一致性:严格按照顺序在zookeeper上执行 原子性:所有事物请求的结果,在整个集群的应用情况一致 单一视图:无论从哪个服务器进入集群,看到的东西都是一致的 可靠性:服务端成功响应后,状态会 一 ...
- ZooKeeper概述与安装
ZooKeeper笔记 ZooKeeper概述 背景: 现代企业对计算机系统的计算存储能力要求越来越高,单纯的高性能服务器已经无法满足要求.企业的IT架构从集中式向分布式过度. 所谓分布式,就是将一个 ...
- ZooKeeper概述(转)
译自http://zookeeper.apache.org/doc/trunk/zookeeperOver.html ZooKeeper是一个用于分布式应用的开源分布式协调服务.它提供了简单的原语集合 ...
- ZooKeeper概述
1.Zookeeper概述 Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务.它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置 ...
- ZooKeeper概述(三)
ZooKeeper:分布式应用的分布协调服务 ZooKeeper是一个为分布式应用提供的分布的开源的协调服务.它暴露一组简单的原子操作,分布式系统可以在这之上为同步,配置管理,和组和命名实现更高级的服 ...
- zk 01之 ZooKeeper概述
Zookeeper产生的背景 ZooKeeper---译名为“动物园管理员”.动物园里当然有好多的动物,游客可以根据动物园提供的向导图到不同的场馆观赏各种类型的动物,而不是像走在原始丛林里,心惊胆颤的 ...
- 大话Spark(1)-Spark概述与核心概念
说到Spark就不得不提MapReduce/Hadoop, 当前越来越多的公司已经把大数据计算引擎从MapReduce升级到了Spark. 至于原因当然是MapReduce的一些局限性了, 我们一起先 ...
- Zookeeper概述、特点、数据模型
Zookeeper 1.Zookeeper概述 Zookeeper是一个工具,可以实现集群中的分布式协调服务. 所谓的分布式协调服务,就是在集群的节点中进行可靠的消息传递,来协调集群的工作. Zo ...
- 大数据之Zookeeper概述
Zookeeper概述 Zookeeper是一个开放源码的分布式应用程序协调服务,是 Google的Chubby一个开源的实现,是 Hadoop和 HBASE的重要组件.主要解决分布式应用一致性问题. ...
随机推荐
- 【BZOJ】1639: [Usaco2007 Mar]Monthly Expense 月度开支(二分)
http://www.lydsy.com/JudgeOnline/problem.php?id=1639 同tyvj1359,http://www.cnblogs.com/iwtwiioi/p/394 ...
- digitalocean --- How To Install Apache Tomcat 8 on Ubuntu 16.04
https://www.digitalocean.com/community/tutorials/how-to-install-apache-tomcat-8-on-ubuntu-16-04 Intr ...
- ACM计算几何模板——圆和球
#include <iostream> #include <cmath> using namespace std; #define eps 1e-10 /********** ...
- Tomcat高并发配置优化
用的JMeter在自己电脑上测试的.Ubuntu10.04(x64)内存2G,cpu E5400 主频2.7.jdk1.6.0_27(x64) , tomcat6.0.33(x64) , oracle ...
- hdu 4685(匹配+强连通分量)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=4685 思路:想了好久,终于想明白了,懒得写了,直接copy大牛的思路了,写的非常好! 做法是先求一次最 ...
- Linux GCC编译使用动态、静态链接库 (转)
原文出处:http://blog.csdn.net/a600423444/article/details/7206015 在windows下动态链接库是以.dll后缀的文件,二在Linux中,是以.s ...
- Splash界面完美实现
Flash闪烁界面的实现原理 1.首先 new一个数组里面放一些Random图片 private int[] drawables = new int[]{R.drawable.a,R.adable.b ...
- ECharts使用(1)(转载)
转载自http://www.cnblogs.com/Olive116/p/3634480.html 1. EChart最新的文档目录. 首先创建一个解决方案,目录如下: 之前的一篇文章中讲到如果要使 ...
- Dart异步与消息循环机制
Dart与消息循环机制 翻译自https://www.dartlang.org/articles/event-loop/ 异步任务在Dart中随处可见,例如许多库的方法调用都会返回Future对象来实 ...
- Django系列
1.Django框架 2.Django restframework 其他 django之contenttype