python简单日志统计
业务场景:在一个目录里,有许多日志文件,里面是一条条的json数据,格式如下,为防止一个账号被多个ip使用,现在我想知道:哪些用户登录了哪些ip,和哪些ip登录了哪些用户,如果一个ip对应一个用户,就不展示了
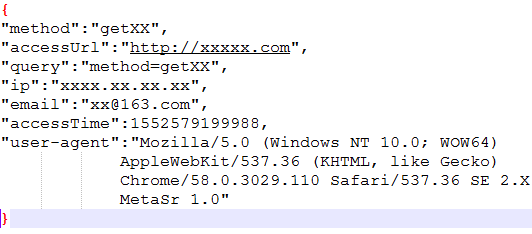
import json, os, sys
ip_map = {}
email_map = {}
path = 'E:/GoogleDownload/' #日志路径
type = # :countByIp :countByEmail
def countByIp(line):
try:
if line['ip'] in ip_map.keys():
ip_v_map = ip_map[line['ip']]
if line['email'] in ip_v_map.keys():
new_email_count = ip_v_map[line['email']] +
ip_v_map[line['email']] = new_email_count
else:
ip_v_map[line['email']] =
ip_map[line['ip']] = ip_v_map
else:
ip_v_map = {}
ip_v_map[line['email']] =
ip_map[line['ip']] = ip_v_map
except:
print("countByIp error: %s"%line)
def countByEmail(line):
try:
if line['email'] in email_map.keys():
email_v_map = email_map[line['email']]
if line['ip'] in email_v_map.keys():
new_ip_count = email_v_map[line['ip']] +
email_v_map[line['ip']] = new_ip_count
else:
email_v_map[line['ip']] =
email_map[line['email']] = email_v_map
else:
email_v_map = {}
email_v_map[line['ip']] =
email_map[line['email']] = email_v_map
except:
print("countByEmail error: %s"%line)
def getResult(file, type):
fr = open(path+file, "r")
line = fr.readline()
line = json.loads(line)
if type == :
countByIp(line)
elif type == :
countByEmail(line)
else:
return
i =
while line:
line = fr.readline()
if line == "" or line is None:
continue
i +=
line = json.loads(line[:-])
if type == :
countByIp(line)
elif type == :
countByEmail(line)
else:
return
print("读取%s, 行数:%s"%(file,i))
fr.close()
if __name__ == "__main__":
for f in os.listdir(path):
if os.path.isfile(os.path.join(path, f)) and str(f).endswith('.log'):
getResult(str(f), type)
fw_ip = open(path + "result_ip.txt", "w")
fw_email = open(path + "result_email.txt", "w")
for ip in list(ip_map):
if == len(ip_map[ip]):
ip_map.pop(ip)
for ip in list(email_map):
if == len(email_map[ip]):
email_map.pop(ip)
fw_ip.write(str(ip_map))
fw_email.write(str(email_map))
fw_ip.close()
fw_email.close()
最后,结果如下
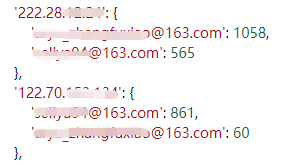
当前ip被哪些用户登录了多少次
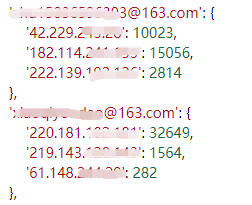
当前用户在哪些ip上登录过多少次
python简单日志统计的更多相关文章
- python简单日志处理
简单日志处理 import datetime import re logfile='''58.61.164.141 - - [22/Feb/2010:09:51:46 +0800] "GET ...
- python简单词频统计
任务 简单统计一个小说中哪些个汉字出现的频率最高 知识点 文件操作 字典 排序 lambda 代码 import codecs import matplotlib.pyplot as plt from ...
- python 简单日志框架 自定义logger
转载请注明: 仰望高端玩家的小清新 http://www.cnblogs.com/luruiyuan/ 通常我们在构建 python 系统时,往往需要一个简单的 logging 框架.python 自 ...
- 使用python脚本实现统计日志文件中的ip访问次数
使用python脚本实现统计日志文件中的ip访问次数,注意此脚本只适用ip在每行开头的日志文件,需要的朋友可以参考下 适用的日志格式: 106.45.185.214 - - [06/Aug/2014: ...
- Python基础-使用range创建数字列表以及简单的统计计算和列表解析
1.使用函数 range() numbers = list(range[1,6]) print (numbers) 结果: [1,2,3,4,5] 使用range函数,还可以指定步长,例如,打印1~1 ...
- python制作简单excel统计报表3之将mysql数据库中的数据导入excel模板并生成统计图
python制作简单excel统计报表3之将mysql数据库中的数据导入excel模板并生成统计图 # coding=utf-8 from openpyxl import load_workbook ...
- python制作简单excel统计报表2之操作excel的模块openpyxl简单用法
python制作简单excel统计报表2之操作excel的模块openpyxl简单用法 # coding=utf-8 from openpyxl import Workbook, load_workb ...
- Kafka实战-实时日志统计流程
1.概述 在<Kafka实战-简单示例>一文中给大家介绍来Kafka的简单示例,演示了如何编写Kafka的代码去生产数据和消费数据,今天给大家介绍如何去整合一个完整的项目,本篇博客我打算为 ...
- 【转】Python之日志处理(logging模块)
[转]Python之日志处理(logging模块) 本节内容 日志相关概念 logging模块简介 使用logging提供的模块级别的函数记录日志 logging模块日志流处理流程 使用logging ...
随机推荐
- 条件编译#ifdef的妙用详解
c语言中条件编译相关的预编译指令,包括 #define.#undef.#ifdef.#ifndef.#if.#elif.#else.#endif.defined. #define ...
- JS正则表达式从入门到入土(10)—— 字符串对象方法
字符串对象方法 search方法 String.prototype.search(reg) search方法用于检索字符串中指定的子字符串,或检索与正则表达式相匹配的子字符串,方法返回第一个匹配结果的 ...
- jenkins windows执行批处理脚本总是失败
使用jenkins 在使用编译vc++的一个项目,在执行批处理脚本的时候总是失败, 但是在控制台无论是管理员还是普通用户都能正常编译,jenkins每次都失败,看日志就是调用一个cmd命令直接失败,e ...
- SaltStack配置salt-api第十二篇
介绍 SaltStack官方提供有REST API格式的 salt-api项目,将使Salt与第三方系统集成变得尤为简单.本文讲带你了解如何安装配置Salt-API, 如何利用Salt-API获取想要 ...
- ThinkPHP的URL重写时遇到No input file specified的解决方法
因为在Fastcgi模式下,php不支持rewrite的目标网址的PATH_INFO的解析 ThinkPHP运行在URL_MODEL=2时,会出现 No input file specified.的情 ...
- Linux shell常用命令
1. sz 和 rz sz命令发送文件到本地: # sz filename rz命令本地上传文件到服务器: # rz 执行该命令后,在弹出框中选择要上传的文件即可.
- idea中修改git提交代码的用户名
1.原因:刚进入这家公司,给同事交接完,直接使用他的电脑,每次提交代码都显示他的用户名,本以为是电脑系统名称呢,可是修改了之后没有效果 2.解决方案: 打开C盘里的 .gitconfig文件 看下gi ...
- 执行Maven install或Maven test命令时控制台输出乱码的解决办法
[解决方案一] 在Maven的pom.xml文件中增加如下代码: <properties> <argLine>-Dfile.encoding=UTF-8</argLine ...
- Python不同版本切换
2016年6月8日更新: 这是我早前写的一篇小文章,其实,后来也没有采用这种方法切换.电脑上安装了多个Python 版本,保证自己经常用的版本加入环境变量外,使用非系统的版本时一般使用 IDE 编辑器 ...
- zen cart 空白页面的解决方案
在安装zen cart 这套CMS时, 有时候会由于修改了某些页面或者是由于环境的某些组件的版本问题导致前台页面出现空白页, 由于在空白页面处没有任何提示, 并且在日志中也没有这样的出错提示, 导致在 ...