Suricata, to 10Gbps and beyond(X86架构)
Introduction
Since the beginning of July 2012, OISF team is able to access to a server where one interface is receivingsome mirrored real European traffic. When reading "some", think between 5Gbps and 9.5Gbpsconstant traffic. With that traffic, this is around 1Mpps to
1.5M packet per seconds we have to study.
The box itself is a standard server with the following characteristics:
- CPU: One Intel(R) Xeon(R) CPU E5-2680 0 @ 2.70GHz (16 cores counting Hyperthreading)
- Memory: 32Go
- capture NIC: Intel 82599EB 10-Gigabit SFI/SFP+
The objective is simple: be able to run Suricata on this box and treat the wholetraffic with a decent number of rules. With the constraint not to use any nonofficial system code (plain system and kernel if we omit a driver).
The code on the box have been updated October 4th:
- It runs Suricata 1.4beta2
- with 6719 signatures
- and 0% packet loss
- with setup described below
The setup is explained by the following schema: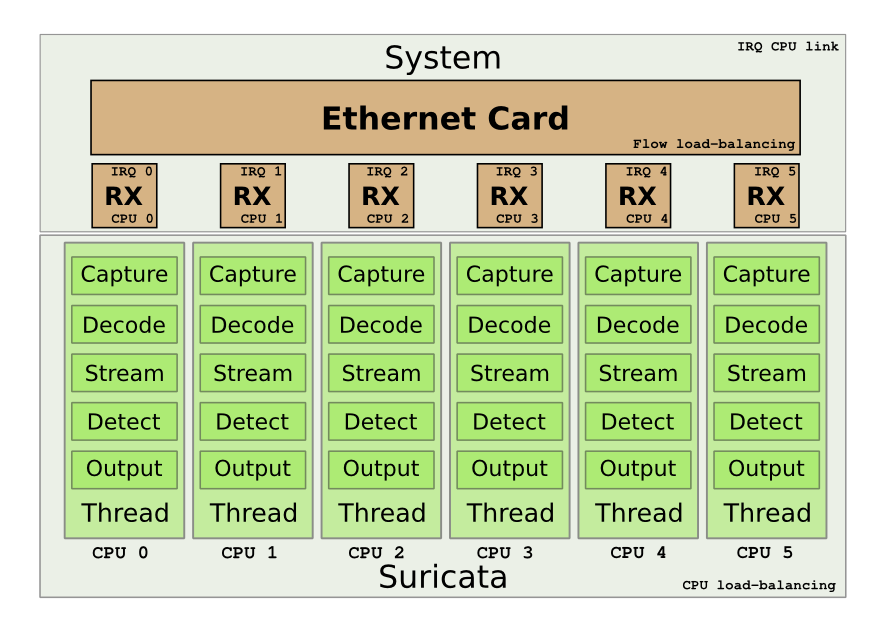 We
We
want to use the multiqueue system on the Intel card to be able to load balance the treatment. Next goal is to have one single CPU to treat the packet from the start to the end.
Peter Manev, Matt Jonkmann, Anoop Saldanha and Eric Leblond (myself) have been involved inthe here described setup.
Detailed method
The Intel NIC benefits from a multiqueue system. The RX/TX traffic can be load-balancedon different interrupts. In our case, this permit to handle a part of the flow on eachCPU. One really interesting thing is that the load-balancing can be done with respectto
the IP flows. By default, one RX queue is created per-CPU.
More information about multiqueue ethernet devices can be found in the documentnetworking/scaling.txt in the Documentation directory of Linux
sources.
Suricata is able to do zero-copy in AF_PACKET capture mode. One other interesting featureof this mode is that you can have multiple threads listening to the same interface. Inour case, we can start one threads per queue to have a load-balancing of capture
on allour resources.
Suricata has different running modes which define how the different parts of the engine(decoding, streaming, siganture, output) are chained. One of the mode is the ‘workers’mode where all the treatment for a packet is made on a single thread. This mode isadapted
to our setup as it will permit to keep the work from start to end on a singlethread. By using the CPU affinity system available in Suricata, we can assign eachthread to a single CPU. By doing this the treatment of each packet can be done ona single CPU.
But this does not solve one problem which is the link between the CPU receiving the packetand the one used in Suricata.To do so we have to ensure that when a packet is received on a queue, the CPU that willhandle the packet will be the same as the one treating
the packet in Suricata. DavidMiller had already planned this kind of setup when coding the fanout mode of AF_PACKET.One of the flow load balancing mode is flow_cpu. In this mode, the packet is delivered tothe same track depending on the CPU.
The dispatch is made by using the formula "cpu % num" where cpu is the cpu number andnum is the number of socket bound to the same fanout socket. By the way, this implyyou can’t have a number of sockets superior to the number of CPUs.A code study shows that
the assignement in the array of sockets is incrementally made.Thus first socket to bind will be assigned to the first CPU, etc..In case, a socket disconnect from the set, the last socket of the array will take the empty place.This implies the optimizations
will be partially lost in case of a disconnect.
By using the flow_cpu dispatch of AF_PACKET and the workers mode of Suricata, we canmanage to keep all work on the same CPU.
Preparing the system
The operating system running on is an Ubuntu 12.04 and the driver igxbewas outdated.Using the instruction available on Intel website (README.txt),we’ve updated the driver.Next
step was to unload the old driver and load the new one
sudo rmmod ixgbe
sudo modprobe ixgbe FdirPballoc=3
Doing this we’ve also tried to use the RSS variable. But it seems there is an issue, as we still having 16 queues although the RSS params wasset to 8.
Once done, the next thing is to setup the IRQ handling to have each CPU linked in order withthe corresponding RX queue. irqbalance was running on the system and the setup wascorrectly made.
The interface was using IRQ 101 to 116 and /proc/interrupts show a diagonale indicatingthat each CPU was assigned to one interrupt.
If not, it was possible to use the instruction contained in IRQ-affinity.txt availablein the Documentation directory of Linux sources.
But the easy way to do it is to use the script provided with the driver:
ixgbe-3.10.16/scripts$ ./set_irq_affinity.sh eth3
Note: Intel latest driver was responsible of a decrease of CPU usage. With Ubuntu kernel version, the CPU usage as 80% and it is 45% with latest Intel driver.
The card used on the system was not load-balancing UDP flow using port. We had to use‘ethtool’ to fix this
regit@suricata:~$ sudo ethtool -n eth3 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA regit@suricata:~$ sudo ethtool -N eth3 rx-flow-hash udp4 sdfn
regit@suricata:~$ sudo ethtool -n eth3 rx-flow-hash udp4
UDP over IPV4 flows use these fields for computing Hash flow key:
IP SA
IP DA
L4 bytes 0 & 1 [TCP/UDP src port]
L4 bytes 2 & 3 [TCP/UDP dst port]
In our case, the default setting of the ring parameters of the card, seemsto indicate it is possible to increase the ring buffer on the card
regit@suricata:~$ ethtool -g eth3
Ring parameters for eth3:
Pre-set maximums:
RX: 4096
RX Mini: 0
RX Jumbo: 0
TX: 4096
Current hardware settings:
RX: 512
RX Mini: 0
RX Jumbo: 0
TX: 512
Our system is now ready and we can start configuring Suricata.
Suricata setup
Global variables
The run mode has been set to ‘workers’
max-pending-packets: 512
runmode: workers
As pointed out by Victor Julien, this is not necessary to increase max-pending-packets too much because only a number of packets equal to the total number of worker threads can be treated simultaneously.
Suricata 1.4beta1 introduce a delayed-detect variable under detect-engine. If set to yes, this trigger a build of signature after the packet capture threads have started working. This is a potential issue if your system is short in CPU
as the task of building the detect engine is CPU intensive and can cause some packet loss. That’s why it is recommended to let it to the default value of
no.
AF_PACKET
The AF_PACKET configuration is almost straight forward
af-packet:
- interface: eth3
threads: 16
cluster-id: 99
cluster-type: cluster_cpu
defrag: yes
use-mmap: yes
ring-size: 300000
Affinity
Affinity settings permit to assign thread to set of CPUs. In our case, we onlSet to have in exclusive mode one packet thread dedicated to each CPU. The settingused to define packet thread property in ‘workers’ mode is ‘detect-cpu-set’
threading:
set-cpu-affinity: yes
cpu-affinity:
- management-cpu-set:
cpu: [ "all" ]
mode: "balanced"
prio:
default: "low" - detect-cpu-set:
cpu: ["all"]
mode: "exclusive" # run detect threads in these cpus
prio:
default: "high"
The idea is to assign the highest prio to detect threads and to let the OS do its bestto dispatch the remaining work among the CPUs (balanced mode on all CPUs for the management).
Defrag
Some tuning was needed here. The network was exhibing some serious fragmentationand we have to modify the default settings
defrag:
memcap: 512mb
trackers: 65535 # number of defragmented flows to follow
max-frags: 65535 # number of fragments
The ‘trackers’ variable was not documented in the original YAML configuration file.Although defined in the YAML, the ‘max-frags’ one was not used by Suricata. A patchhas been made to implement this.
Streaming
The variables relative to streaming have been set very high
stream:
memcap: 12gb
max-sessions: 20000000
prealloc-sessions: 10000000
inline: no # no inline mode
reassembly:
memcap: 14gb
depth: 6mb # reassemble 1mb into a stream
toserver-chunk-size: 2560
toclient-chunk-size: 2560
To detect the potential issue with memcap, one can read the ‘stats.log’ filewhich contains various counters. Some of them matching the ‘memcap’ string.
Running suricata
Suricata can now be runned with the usual command line
sudo suricata -c /etc/suricata.yaml --af-packet=eth3
Our affinity setup is working as planned as show the following log line
Setting prio -2 for "AFPacketeth34" Module to cpu/core 3, thread id 30415
Tests
Tests have been made by simply running Suricata against the massive trafficmirrored on the eth3 interface.
At first, we started Suricata without rules to see if it was able to dealwith the amount of packets for a long period. Most of the tuning was doneduring this phase.
To detect packet loss, the capture keyword can be search in ‘stats.log’.If ‘kernel_drops’ is set to 0, this is good
capture.kernel_packets | AFPacketeth315 | 1436331302
capture.kernel_drops | AFPacketeth315 | 0
capture.kernel_packets | AFPacketeth316 | 1449320230
capture.kernel_drops | AFPacketeth316 | 0
The statistics are available for each thread. For example, ‘AFPacketeth315′ isthe 15th AFPacket thread bound to eth3.
When this phase was complete we did add some rules by using Emerging Threat PRO rulesfor malware, trojan and some others:
rule-files:
- trojan.rules
- malware.rules
- chat.rules
- current_events.rules
- dns.rules
- mobile_malware.rules
- scan.rules
- user_agents.rules
- web_server.rules
- worm.rules
This ruleset has the following characterics:
- 6719 signatures processed
- 8 are IP-only rules
- 2307 are inspecting packet payload
- 5295 inspect application layer
- 0 are decoder event only
This is thus a decent ruleset with a high part of application level event which require acomplex processing. With that ruleset, there is more than 16 alerts per second (output in unified2 format).
With the previously mentioned ruleset, the load of each CPU is around 60% and Suricatais remaining stable during hours long run.
In most run, we’ve observed some packet loss between capture start and first time Suricata grab the statistics. It seems the initialization phase is not fast enough.
Conclusion
OISF team has access to the box for a week now and has alreadymanaged to get real performance. We will continue to work on it to providethe best possible experience to all Suricata’s users.
Feel free to made any remark and suggestion about this blog post and this setup.
Suricata, to 10Gbps and beyond(X86架构)的更多相关文章
- x86架构手机跑安卓好吗?(脑补)
华硕低价位手机ZenFone一推出就掀起市场话题,许多人也对ZenFone所采用的Intel Atom处理器有所意见,深怕其相容性问题无法正确执行应用程式App,这究竟是怎么回事呢? Intel近几年 ...
- x86架构的android手机兼容性问题
x86架构的android手机兼容性问题 http://www.cnblogs.com/guoxiaoqian/p/3984934.html 自从CES2012上Intel发布了针对移动市场的Medf ...
- X86 架构和 ARM 架构
1.关于x86架构 X86是一个intel通用计算机系列的标准编号缩写,也标识一套通用的计算机指令集合,X86是由Intel推出的一种复杂指令集,用于控制芯片的运行的程序,现在X86已经广泛运用到了家 ...
- 基于x86架构的内核Demo的详细开发文档
http://hurlex.0xffffff.org/ 这里是hurlex这个基于x86架构的内核Demo的详细开发文档, 包含PDF文档和生成PDF的XeLaTex源码和文档每章节的阶段代码. 你可 ...
- ARM架构和X86架构对比
转载地址 我们就ARM架构的系统与X86架构系统的特性进行一个系统分析,方便用户在选择系统时进行理性.合理的比价分析. 一.性能: X86结构的电脑无论如何都比ARM结构的系统在性能方面要快得多.强得 ...
- X86架构
在接触BIOS的时候,都需要对PC架构有一定的认知.目前的PC架构绝大多数都是Intel的X86架构,貌似也是因为INTEL的这个X86架构早就了目前INTEL如日中天的地位. 废话不多说,X86架构 ...
- kernel生成针对x86架构的tags和cscope数据库
最近下载了kernel的最新源码4.15版,但下载后的linux内核不仅包含了x86架构的函数还包含了如:arm.powerPC等等其他架构的函数,如果直接生成tags文件,将来查找时,多种架构的同名 ...
- ARM和X86架构
重温下CPU是什么 中央处理单元(CPU)主要由运算器.控制器.寄存器三部分组成.运算器起着运算的作用,控制器负责发出CPU每条指令所需要的信息,寄存器保存运算或者指令的一些临时文件以保证更高的速度. ...
- ARM与X86架构的对决[整编]
CISC(复杂指令集计算机)和RISC(精简指令集计算机)是当前CPU的两种架构.它们的区别在于不同的CPU设计理念和方法.早期的CPU全部是CISC架构,它的设计目的是 CISC要用最少的机器语言 ...
- Linux x86架构下ACPI PNP Hardware ID的识别机制
转:https://blog.csdn.net/morixinguan/article/details/79343578 关于Hardware ID的用途,在前面已经大致的解释了它的用途,以及它和AC ...
随机推荐
- 浅谈SpringMVC(一)
一.SpringMVC引言 Spring MVC属于SpringFrameWork的后续产品,已经融合在Spring Web Flow里面.Spring 框架提供了构建 Web 应用程序的全功能 MV ...
- [非技术参考]C#重写ToString方法
C# 中的每个类或结构都隐式继承 Object 类. 因此,C# 中的每个对象都会获得 ToString 方法,此方法返回该对象的字符串表示形式. 例如,所有 int 类型的变量都有一个 ToStri ...
- HiveQL与SQL区别
转自:http://www.aboutyun.com/thread-7327-1-1.html 1.Hive不支持等值连接 SQL中对两表内联可以写成:select * from dual a,dua ...
- bzoj 2141 : 排队 分块
题目链接 2141: 排队 Time Limit: 4 Sec Memory Limit: 259 MBSubmit: 1169 Solved: 465[Submit][Status][Discu ...
- Address already in use: JVM_Bind错误的解决
1,独立运行的Tomcat没有关闭. 自安装的tomcat程序设置开机自动运行,或者在之前运行过,先关闭ecplipse或jbuilder,在任务管理器中找到Tomcat的进程,将其 kill掉,即可 ...
- Snort
https://www.snort.org/ http://blog.csdn.net/htttw/article/details/7521053 http://www.ibm.com/develop ...
- VC++中的类的内存分布(上)(通过强制转换,观察地址,以及地址里的值来判断)
0.序 目前正在学习C++中,对于C++的类及其类的实现原理也挺感兴趣.于是打算通过观察类在内存中的分布更好地理解类的实现.因为其实类的分布是由编译器决定的,而本次试验使用的编译器为VS2015 RC ...
- Azure 网站上的 Java
编辑人员注释:本文章由Windows Azure 网站团队的项目经理Chris Compy 撰写. Microsoft 已推出针对 Azure 网站上基于 Java 的网站的支持.此功能旨在通过 ...
- sqlplus conn远程连接
oracle.install.responseFileVersion=/oracle/install/rspfmt_dbinstall_response_schema_v11_2_0oracle.in ...
- openstack windows 2008 img
1,制作镜像主机pre Env yum -y install qemu-img virt-install libvirt 2,配置bridge