【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述
官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/current/docker.html#docker-cli-run-prod-mode
1.拉取镜像
docker pull elasticsearch:6.5.
docker pull kibana:6.5.
2.启动容器
docker run -d --name es1 -p 9200:9200 -p 9300:9300 --restart=always -e "discovery.type=single-node" elasticsearch:6.5.4
docker run -d -p 5601:5601 --name kibana --restart=always --link es1:elasticsearch kibana:6.5.4
如果启动ES仅是测试使用,启用单节点即可。
如果启动ES是要给生产任务使用,需要启动ES集群。ES 6.5.4启动集群文章
3.访问地址
http://192.168.92.130:5601/status

4.安装ik分词器
进入es容器
sudo docker exec -it es1 /bin/bash
进入plugins目录
cd plugins/
此时查看插件目录下,有两个插件的目录

下载对应es版本的ik的压缩包【安装插件的版本需要与es版本一致】
wget http://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.5.4/elasticsearch-analysis-ik-6.5.4.zip
创建ik目录,用于存放解压ik压缩包的文件
mkdir elasticsearch-analysis-ik

解压ik压缩包到指定目录
unzip elasticsearch-analysis-ik-6.5..zip -d elasticsearch-analysis-ik
删除源压缩包
rm -f elasticsearch-analysis-ik-6.5..zip
exit 退出容器 重启es容器 查看启动日志加载插件信息
exit
docker restart es1
docker logs -f es1

验证ik分词器是否安装成功【analyzer参数值:ik_max_word 如果未安装成功,请求就会报错!】
两种粗细粒度分别为:
ik_max_word
ik_smart
POST http://192.168.92.130:9200/_analyze
请求体:
{
"analyzer":"ik_max_word",
"text":"德玛西亚之力在北韩打倒了变形金刚"
}
结果:
{
"tokens": [
{
"token": "德",
"start_offset": ,
"end_offset": ,
"type": "CN_CHAR",
"position":
},
{
"token": "玛",
"start_offset": ,
"end_offset": ,
"type": "CN_CHAR",
"position":
},
{
"token": "西亚",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "之力",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "在",
"start_offset": ,
"end_offset": ,
"type": "CN_CHAR",
"position":
},
{
"token": "北韩",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "打倒",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "倒了",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "变形金刚",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "变形",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
},
{
"token": "金刚",
"start_offset": ,
"end_offset": ,
"type": "CN_WORD",
"position":
}
]
}
ik分词器成功安装
附加一个:
查看某个index下某个type中的某条document的某个属性的属性值 分词效果:
格式如下:
你的index/你的type/document的id/_termvectors?fields=${字段名}
http://192.168.92.130:9200/swapping/builder/6/_termvectors?fields=buildName
【注意fields参数对应的是数组】
5.安装pinyin分词器
进入容器
sudo docker exec -it es1 /bin/bash
进入插件目录
cd plugins/
创建目录elasticsearch-analysis-pinyin
mkdir elasticsearch-analysis-pinyin

进入目录elasticsearch-analysis-pinyin,下载pinyin分词器压缩包【注意版本和es版本一致】
cd elasticsearch-analysis-pinyin/
wget https://github.com/medcl/elasticsearch-analysis-pinyin/releases/download/v6.5.4/elasticsearch-analysis-pinyin-6.5.4.zip
解压压缩包,解压完成删除压缩包
unzip elasticsearch-analysis-pinyin-6.5..zip
rm -f elasticsearch-analysis-pinyin-6.5..zip

退出容器,重启es,查看日志
exit
docker restart es1
docker logs -f es1

验证pinyin分词器是否安装成功

结果:
{
"tokens": [
{
"token": "de",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "dmxyzlzbhddlbxjg",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "ma",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "xi",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "ya",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "zhi",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "li",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "zai",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "bei",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "han",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "da",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "dao",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "le",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "bian",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "xing",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "jin",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
},
{
"token": "gang",
"start_offset": ,
"end_offset": ,
"type": "word",
"position":
}
]
}
证明pinyin插件安装成功
6.繁简体转化分词器
进入es容器
sudo docker exec -it es1 /bin/bash
进入plugins目录
cd plugins/
创建繁简体转化目录
mkdir elasticsearch-analysis-stconvert
进入目录
cd elasticsearch-analysis-stconvert/
下载插件压缩包
wget https://github.com/medcl/elasticsearch-analysis-stconvert/releases/download/v6.5.4/elasticsearch-analysis-stconvert-6.5.4.zip
解压压缩包
unzip elasticsearch-analysis-stconvert-6.5.4.zip
解压完成后,移除原压缩包
rm -f elasticsearch-analysis-stconvert-6.5.4.zip
退出容器
exit
重启es
docker restart es1
查看日志

检验繁简体转化是否安装成功
URL:POST
http://192.168.92.130:9200/_analyze
请求体:
{
"analyzer":"stconvert",
"text" : "国际电视台"
}
请求结果:
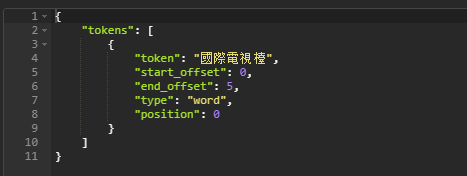
繁简体转化安装成功
7.安装启动logstash
docker拉取logstash
docker pull logstash:6.5.
启动logstash
docker run -d -p 5044:5044 -p 9600:9600 --restart=always --name logstash logstash:6.5.4
查看日志
docker logs -f logstash
查看日志可以看出,虽然启动成功,但是并未连接上es,

这就需要修改logstash中的对接配置
进入logstash容器内
docker exec -it logstash /bin/bash
进入config目录
cd /usr/share/logstash/config/
修改logstash.yml文件中的es.url
vi logstash.yml
修改url为自己的es所在IP:port

退出容器,重启logstash
exit
docker restart logstash
查看日志可以看到启动成功并且es连接池中刚刚配置的连接地址已经连接成功

回到kibana,查看ELK状态以及运转情况
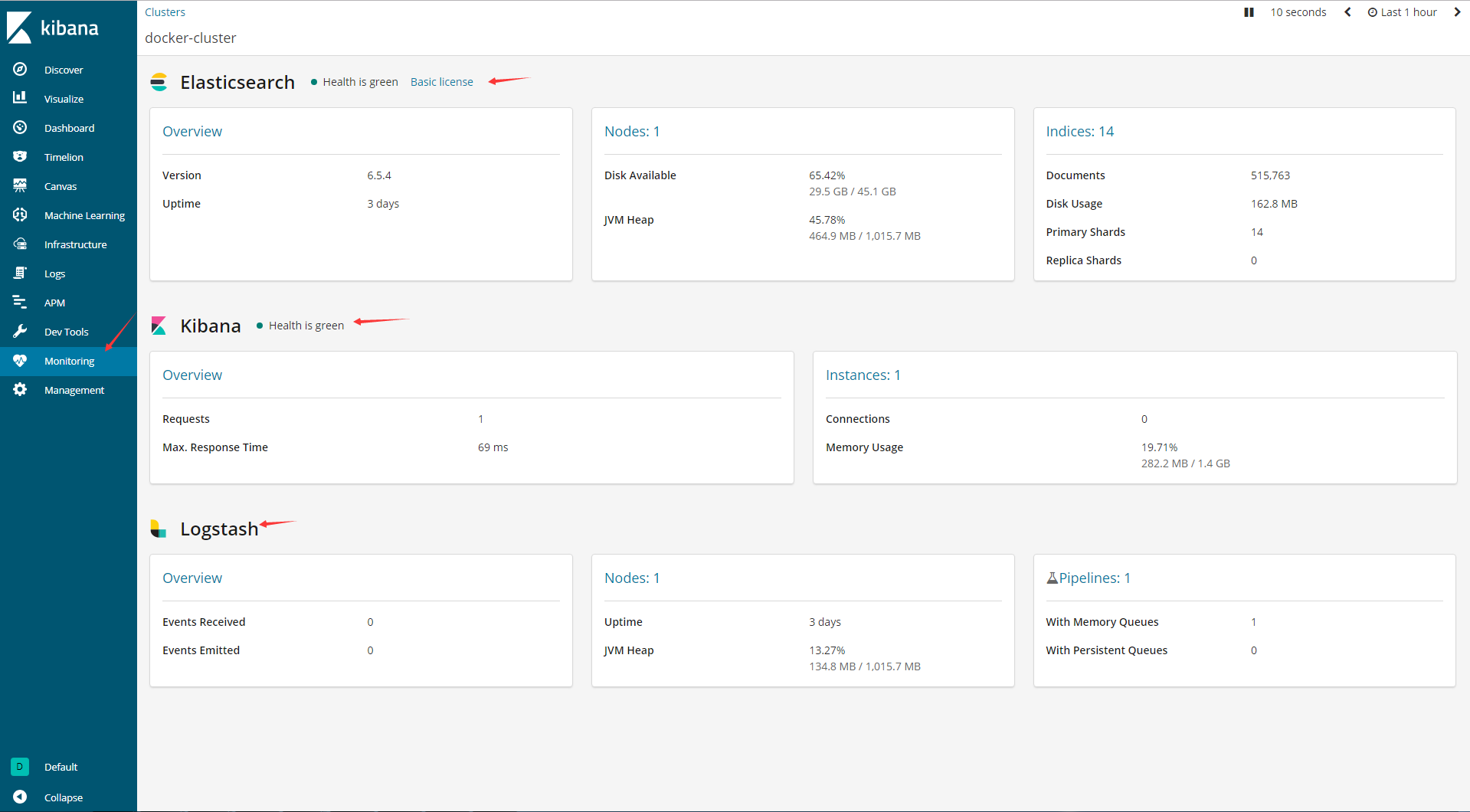
OK,ELK搭建完成!!!
=================================================附录=============================================================================
一、ELK概念描述
看到这里,有很多地方都是迷迷糊糊的吧。
这里简单一说:
ELK是一整套的分布式日志分析平台的解决方案。
在ELK【都是开源软件】中,
E代表 es,用于存储日志信息【就是一个开源可持久化的分布式全文搜索引擎】
L代表logstash,用于收集日志信息【开源数据收集引擎】
K代表kibana,用于展示日志信息【开源的分析和可视化平台】
二、关于logstash插件的知识
这里就要了解一些logstash的知识logstash插件详解
而对于logstash的收集功能,其实是由它的一个一个插件完成的。而主体的三个插件配置就是input--->filter--->output,如下图所示。

其中input和output是必须的,而filter是非必须的。
input插件配置,是指定数据的输入源,配置标明要收集的数据是从什么地方来的。一个 pipeline是可以指定多个input插件的。
input可以是stdin、file、kafka
filter插件配置,是对原始数据进行类型转化、删除字段、格式化数据的。不是必须的配置。
filter可以是date、grok、dissect、mutate、json、geoip、ruby
output插件配置,是将数据输出到指定位置。
output可以是stdout、file、elasticsearch
====================================================================================================
【ELK】【docker】【elasticsearch】2.使用elasticSearch+kibana+logstash+ik分词器+pinyin分词器+繁简体转化分词器 6.5.4 启动 ELK+logstash概念描述的更多相关文章
- ELK学习记录二 :elasticsearch、logstash及kibana的安装与配置
注意事项: 1.ELK版本要求5.X以上,本人使用版本:elasticsearch-6.0.0.kibana-6.0.0-linux-x86_64.logstash-6.0.0.tar 2.Elast ...
- 使用Docker安装ElasticSearch和可视化界面Kibana【图文教学】
一.前言 Elasticsearch是一个基于Lucene的搜索服务器.它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口.Elasticsearch是用Java语言开发的,并 ...
- ELK日志分析系统(4)-elasticsearch数据存储
1. 概述 logstash把格式化的数据发送到elasticsearch以后,elasticsearch负责存储搜索日志数据 elasticsearch的搜索接口还是很强大的,这边不详细展开,因为k ...
- 服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana
服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana https://www.cnblogs.com/xishuai/p/elk- ...
- 批量搞机(二):分布式ELK平台、Elasticsearch介绍、Elasticsearch集群安装、ES 插件的安装与使用
一.分布式ELK平台 ELK的介绍: ELK 是什么? Sina.饿了么.携程.华为.美团.freewheel.畅捷通 .新浪微博.大讲台.魅族.IBM...... 这些公司都在使用 ELK!ELK! ...
- ELK学习实验002:Elasticsearch介绍及单机安装
一 简介 ElasticSearch是一个基于Luncene的搜索服务器.它提供了一个分布式多用户能力全文搜索引擎,基于RESTful web接口,ElsticSearch使用Java开发的,并作为A ...
- docker上安装elasticsearch和ik分词器插件和header,实现分词功能
docker run -di --name=tensquare_es -p 9200: -p 9300:9300 elasticsearch:5.6.8 创建elasticsearch容器(如果版本不 ...
- Elasticsearch 插件head和kibana
本次安装在win7下,linux操作差不多. Elasticsearch的版本是6.5.1 一.前置条件 1.安装nodejs,如果已经安装了,检查一下版本,最好大于6以上,不然后面会失败,官网上已经 ...
- 搜索引擎elasticsearch + kibana + X-pack + IK安装部署
目录 准备安装环境 配置启动 启动elasticsearch 启动kibana 启用X-pack 安装使用IK 使用示例 官方Clients 准备安装环境 这次我们安装以下软件或插件: elastic ...
随机推荐
- vue里面使用Velocity.js
英文文档:http://velocityjs.org/ https://github.com/julianshapiro/velocity 中文手册(教程):http://www.mrfront.co ...
- wpf XAML 设计器异常,提示NullReferenceException 未将对象引用设置到对象例
设计了一个控件,然后在使用该控件的界面上,出现上图,这个应该是设计器的bug,解决办法 不要在界面上直接写Load事件 在cs构造函数里手动注册,并且在控件的构造函数里增加判断 if (Designe ...
- 细说MySQL备份的基本原理(系列一 ) 备份与锁
数据库作为一个系统中唯一或者主要的持久化组件,对服务的可用性和数据的可靠性要求极高. 作为能够有效应对因为系统软硬件故障.人工误操作导致数据丢失的预防手段,备份是目前最为常见的数据库运维操作. 考虑到 ...
- TcxGrid 选中 整行
- Linux 基础——权限管理命令chmod
一.Linux中的文件权限与目录权限 Linux中定义了3种访问权限,分别是r.w.x.其中r表示对象是可读的,w表示对象是可写的,x表示对象是可执行的,这3种权限组成一组rwx分别对应对象的3个安全 ...
- yum源安装php报错缺少libmcrypt.so.4()(64bit)库
https://blog.csdn.net/programercch/article/details/56282184
- webstorm减少内存占用
首先,按照我说的设置之后要重启才行. 在项目里找到不需要监听的文件夹右键:Mark Directory As => Cancel Exclusion 然后重启,嘿嘿,成功了!
- springBoot事物
1.事物 只是需要一个注解即可 2.事物程序 package com.caojun.springboot; import org.springframework.beans.factory.annot ...
- JSR教程2——Spring MVC数据校验与国际化
SpringMVC数据校验采用JSR-303校验. • Spring4.0拥有自己独立的数据校验框架,同时支持JSR303标准的校验框架. • Spring在进行数据绑定时,可同时调用校验框架完成数据 ...
- Django -- settings 详解(转)
Django -- settings 详解 Django settings详解 1.基础 DJANGO_SETTING_MODULE环境变量:让settings模块被包含到python可以找到的目 ...