24.API爬天气预报数据
1.免费注册API 地址: https://console.heweather.com/
必须要用IE浏览器打开,注册邮箱激活,打开控制台,如图:

认证key是访问api的钥匙
2.阅读api说明开发文档 地址:https://www.heweather.com/documents/api/v5/url
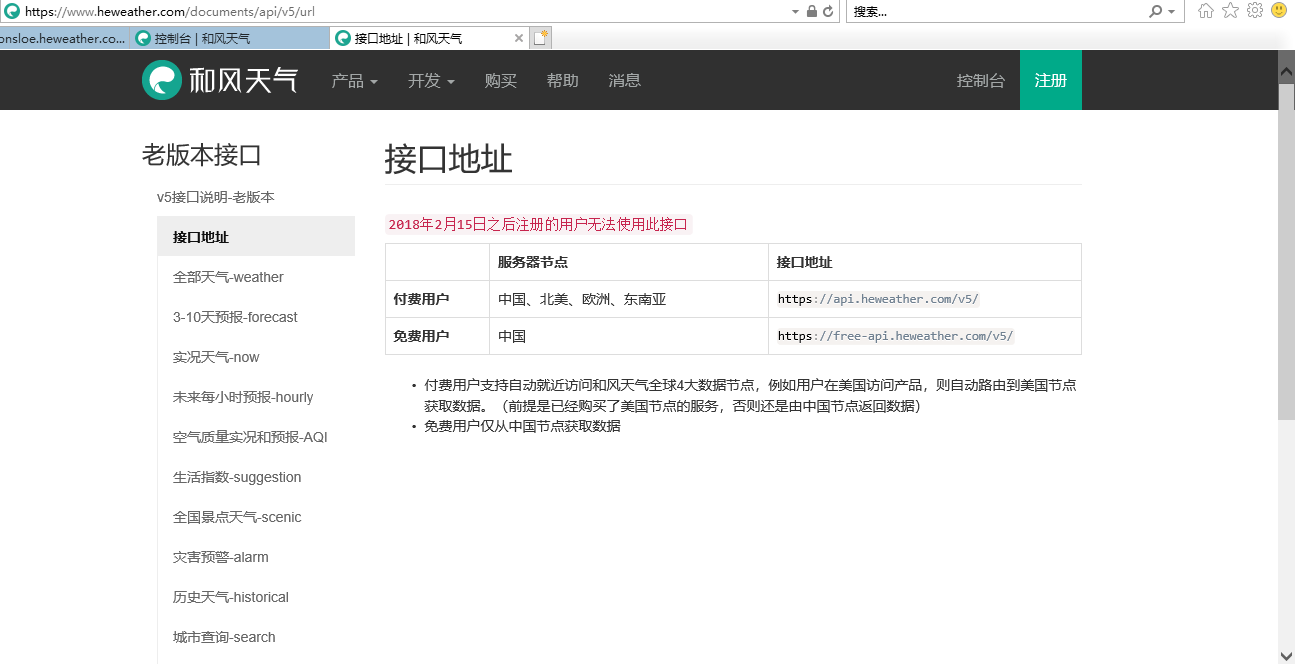
可以看到免费的用户只能访问一个服务器节点:

3.了解调用接口的方法
请求参数如下:

之后就需要拼接参数组成请求urlhttps://free-api.heweather.com/v5/weather?city=yourcity&key=yourkey
4.获取城市ID代码
链接地址:https://cdn.heweather.com/china-city-list.txt
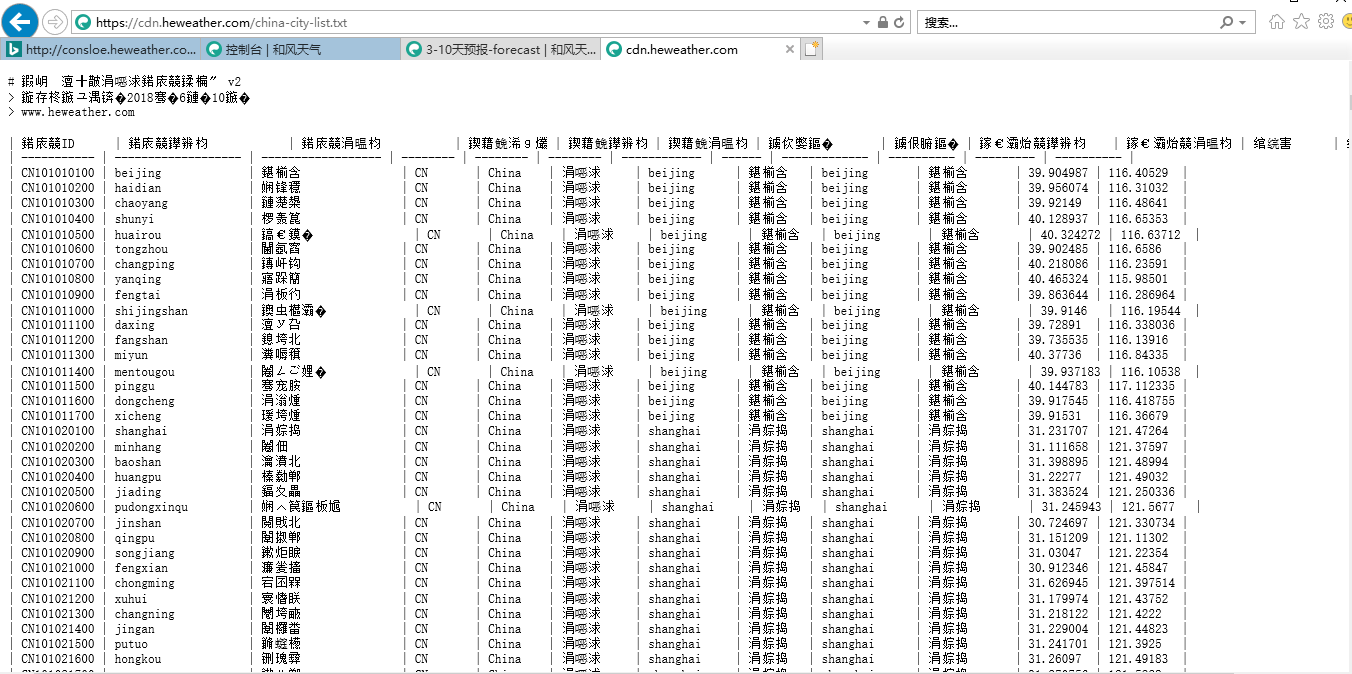
这里数据是乱码的,跟网页编码有关系。
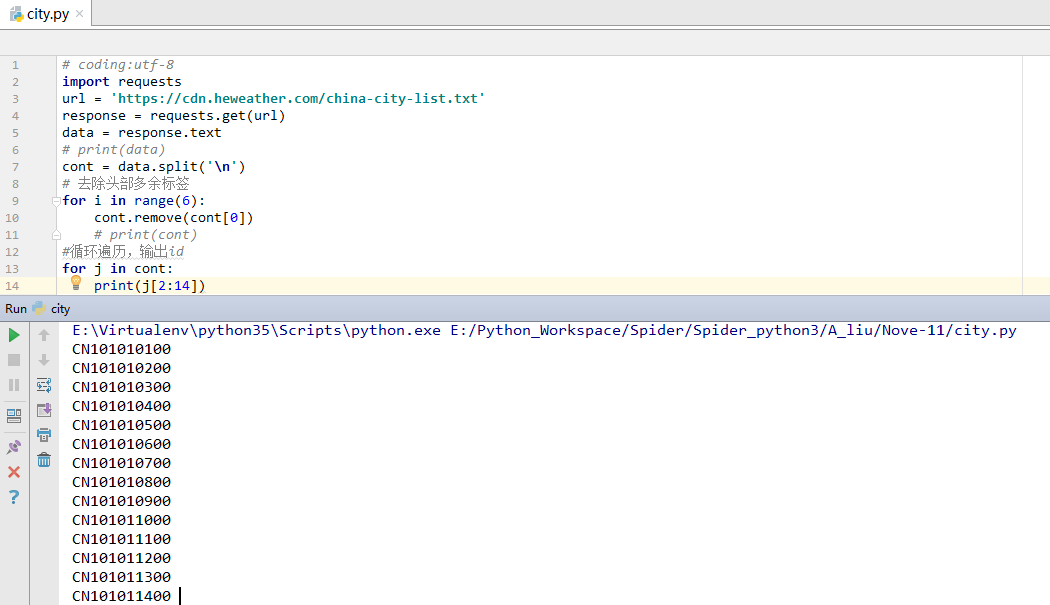
5.获取城市代码
# coding:utf-8
import requests
url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
data = response.text
# print(data)
cont = data.split('\n')
# 去除头部多余标签
for i in range(6):
cont.remove(cont[0])
# print(cont)
#循环遍历,输出id
for j in cont:
print(j[2:14])
执行效果如下:
6.拼接url完善代码 # coding:utf-8
import requests
import random,time
url = 'https://cdn.heweather.com/china-city-list.txt'
response = requests.get(url)
data = response.text
# print(data)
cont = data.split('\n')
# 去除头部多余标签
for i in range(6):
cont.remove(cont[0])
# print(cont)
#循环遍历,输出id
for j in cont:
# print(j[2:14])=
link_url= 'https://free-api.heweather.com/v5/weather?city={}'.format(j[2:14])+'&key=a3a4f84e9d68491e8b2e9d61c61df7c2'
print(link_url)
html = requests.get(link_url)
time.sleep(random.randint(1,2))
print(html.text)
代码报错:


是由于网站把这个借口给关闭了,已经无法使用,但调用api接口的方式大概就是这样。
模拟获取请求参数拼接请求url去获取数据,其实就和使用代理ip差不多。
24.API爬天气预报数据的更多相关文章
- 和风api爬取天气预报数据
''' 和风api爬取天气预报数据 目标:https://free-api.heweather.net/s6/weather/forecast?key=cc33b9a52d6e48de85247779 ...
- 百度地图POI数据爬取,突破百度地图API爬取数目“400条“的限制11。
1.POI爬取方法说明 1.1AK申请 登录百度账号,在百度地图开发者平台的API控制台申请一个服务端的ak,主要用到的是Place API.检校方式可设置成IP白名单,IP直接设置成了0.0.0.0 ...
- Android访问中央气象台的天气预报API得到天气数据
最新说明:该接口已失效! 2014-03-04 可申请它公布的API,需申请:http://smart.weather.com.cn/wzfw/smart/weatherapi.shtml 在用A ...
- 小试牛刀--利用豆瓣API爬取豆瓣电影top250
最近得赶进度爬点东西,对于豆瓣,它为开发者提供了API,目前是v2版本,目前key不对个人开放,但是可以正常通过其提供的API获取数据.豆瓣V2版API权限分3类:公开.高级.商务,我们用开放基本数据 ...
- node.js爬取数据并定时发送HTML邮件
node.js是前端程序员不可不学的一个框架,我们可以通过它来爬取数据.发送邮件.存取数据等等.下面我们通过koa2框架简单的只有一个小爬虫并使用定时任务来发送小邮件! 首先我们先来看一下效果图 差不 ...
- 用python+sklearn(机器学习)实现天气预报数据 数据
用python+sklearn机器学习实现天气预报 数据 项目地址 系列教程 勘误表 0.前言 1.爬虫 a.确认要被爬取的网页网址 b.爬虫部分 c.网页内容匹配取出部分 d.写入csv文件格式化 ...
- Python解析Yahoo的XML格式的天气预报数据
以下是Yahoo天气预报接口xml格式数据: <rss xmlns:yweather="http://xml.weather.yahoo.com/ns/rss/1.0" xm ...
- 【个人】爬虫实践,利用xpath方式爬取数据之爬取虾米音乐排行榜
实验网站:虾米音乐排行榜 网站地址:http://www.xiami.com/chart 难度系数:★☆☆☆☆ 依赖库:request.lxml的etree (安装lxml:pip install ...
- 用JSON-server模拟REST API(二) 动态数据
用JSON-server模拟REST API(二) 动态数据 上一篇演示了如何安装并运行 json server , 在这里将使用第三方库让模拟的数据更加丰满和实用. 目录: 使用动态数据 为什么选择 ...
随机推荐
- JScript 正则表达式语法表
字符 描述 \ 标记下一个字符是特殊字符或文字.例如,"n" 和字符 "n" 匹配."\n" 则和换行字符匹配.序列 "\\&qu ...
- 开启和关闭HBase的thrift进程
开启 $HBASE_HOME/bin/hbase-daemon.sh start thrift [hadoop@bigdatamaster hbase]$ jps 3543 ThriftServer ...
- Ubuntu 14.10 下Hadoop代码编译问题总结
问题1 protoc (compile-protoc) on project hadoop-common: org.apache.maven.plugin.MojoExecutionExceptio ...
- 学习笔记之Data Visualization
Data visualization - Wikipedia https://en.wikipedia.org/wiki/Data_visualization Data visualization o ...
- echarts饼图配置
js引用和配置div <div id="container" style="height: 100%"></div> <scrip ...
- CTF PHP文件包含--session
PHP文件包含 Session 首先了解一下PHP文件包含漏洞----包含session 利用条件:session文件路径已知,且其中内容部分可控. 姿势: php的session文件的保存路径可以在 ...
- 第9章 应用层(6)_SMTP和POP3/IMAP协议
7. 电子邮件 7.1 电子邮件发送和接收过程 (1)图解电子邮件的发送 ①一个电子邮件系统应具备三个主要组成构件:A用户代理(如Outlook).B邮件服务器.C邮件发送和接收协议(分别为SMTP和 ...
- 获取Android文件路径
Environment.getDataDirectory().getPath() : /data Environment.getDownloadCacheDirectory().getPath() : ...
- sql语句中order by 多个字段同时排序的应用
order by 后面可以跟多个字段进行排序 用A1代表第一个字段,A2代表第二个字段 一.order by A1 , A2 desc 指的是用A1升序A2降序 二.order by A1 a ...
- 16 Linux系统的文件压缩、解压与归档
这一节的内容,我们详细介绍下Linux的文件压缩.解压缩与文件归档的内容,也就是tar.gzip.bzip2.xz等命令的内容: 压缩(compress)与解压缩(uncompress) Linux系 ...