Python学习--Selenium模块学习(2)
Selenium的基本操作
获取浏览器驱动寻找方式
1. 通过手动指定浏览器驱动路径
2. 通过 `$PATH`环境变量找寻浏览器驱动
可参考Python学习--Selenium模块简单介绍(1)
控制浏览器访问URL
browser.get(https://www.baidu.com/)
find系列函数定位元素
- `find_element_by_xxx` 返回第一个符合条件 `WebElement`
- `find_elements_by_xxx` 返回符合条件所有元素包含了`WebEelemnt`列表
- `find`函数系列说明
- `find_element_by_class_name` 通过class 查询元素
- `find_element_by_id` 通过 ID
- `find_element_by_name` 通过name
- `find_element_by_tag_name` 通过标签名称
- `find_element_by_css_selector` css样式选择
- `find_element_by_link_text` 通过链接内容查找
- `find_element_by_partial_link_text` 通过链接内容包含的内容查找,模糊查询
- `find_element_by_xpath` 通过 xpath 查找数据


获取元素属性和文本内容
# 获取属性
element.get_attribute('属性名')
# 获取文本内容
element.text
输入框输入内容
input_element.send_keys('博客园')
自动百度查找博客园
import time # 1. 导入模块
from selenium import webdriver # 2. 创建浏览器对象,
browser = webdriver.Chrome() # 参数驱动路径,默认参数也是当前路径的chromedriver驱动 # 3. 输入网址
browser.get("https://www.baidu.com/") timeout = 60
start_time = time.time()
while True:
try:
time.sleep(0.1) # 兼顾其他程序使用CPU资源
# 4. 找到输入框,输入关键词
input_element = browser.find_element_by_id('kw')
input_element.send_keys("小a玖拾柒-博客园") # 查询博客园
# 5. 找到“百度一下”的按钮,点击一下按钮
button = browser.find_element_by_id('su')
button.click()
time.sleep(3) # 让网页加载完成
# 6. 找到作者的博客园链接
url_element = browser.find_element_by_link_text("小a玖拾柒 - 博客园")
url_element.click()
break
except Exception as e:
if time.time() > start_time: # 超时
print(e)
break # 退出浏览器
time.sleep(3)
browser.quit()
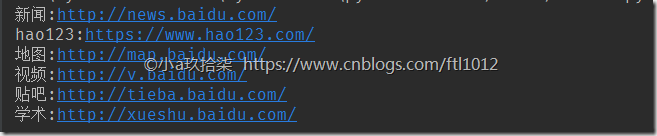
查看百度首页的链接(获取元素是文本内容和元素属性)
import time
# 1. 导入模块
from selenium import webdriver # 2. 创建浏览器对象,
browser = webdriver.Chrome() # 参数驱动路径,默认参数也是当前路径的chromedriver驱动 # 3. 输入网址
browser.get("https://www.baidu.com/") baidu_list = browser.find_elements_by_class_name("mnav")
for item in baidu_list:
# 获取元素是文本内容和元素属性
print("{0}:{1}".format(item.text, item.get_attribute("href"))) # 退出浏览器
time.sleep(5)
browser.quit()
扩展:Selenium的自动等待方式
当控制浏览器时,浏览器正在加载页面同时又去获取数据导致浏览器寻找不到需要操作的元素引发异常。
- 方式一:强制等待,浪费时间
import time
time.sleep(秒数)
- 方式二:隐性等待,缺点:无法控制 AJAX请求
browser.implicitly_wait(等待时间)
- 方式三:显性等待,每个元素都可以自己定义检查条件
手动编写:
timeout = 60
start_time = time.time()
while True:
try:
time.sleep(0.1) # 兼顾其他程序使用CPU资源
# 4. 找到输入框,输入关键词
input_element = browser.find_element_by_id('kw')
input_element.send_keys("小a玖拾柒-博客园") # 查询博客园
# 5. 找到“百度一下”的按钮,点击一下按钮
button = browser.find_element_by_id('su')
button.click()
time.sleep(3) # 让网页加载完成
# 6. 找到作者的博客园链接
url_element = browser.find_element_by_link_text("小a玖拾柒 - 博客园")
url_element.click()
break
except Exception as e:
if time.time() > start_time: # 超时
print(e)
break
Selenium提供:
# 导入显性等待的API需要的模块
# 1> 等待对象模块
from selenium.webdriver.support.wait import WebDriverWait
# 2> 导入等待条件模块
from selenium.webdriver.support import expected_conditions as EC
# 3> 导入查询元素模块
from selenium.webdriver.common.by import By # 使用selenium api 实现显性等待
# 1> 创建等待对象
# 参数一 浏览器对象
# 参数二 超时时间
# 参数三 检查元素时间间隔
wait = WebDriverWait(browser,60,0.1)
# presence_of_element_located 检查元素是否存在,参数是一个元祖,元祖内部描述等待元素查询方案
# visibility_of_element_located 检查元素是否可见
url_element= wait.until(EC.presence_of_element_located((By.CLASS_NAME,"favurl")))
url_element.click()
Python学习--Selenium模块学习(2)的更多相关文章
- Python学习--Selenium模块
1. Python学习--Selenium模块介绍(1) 2.Python学习--Selenium模块学习(2) 其他: 1. Python学习--打码平台
- python中confIgparser模块学习
python中configparser模块学习 ConfigParser模块在python中用来读取配置文件,配置文件的格式跟windows下的ini配置文件相似,可以包含一个或多个节(section ...
- 【Python】logging模块学习笔记
因为做接口自动化测试遇到的一个代码逻辑上的问题,又不知道具体问题出在哪里,所以在模块化代码之前,先学习下python的日志模块logging. 入门1 入门2 日志级别大小关系为:CRITICAL & ...
- python(五)常用模块学习
版权声明:本文为原创文章,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明. https://blog.csdn.net/fgf00/article/details/52357 ...
- Python之常用模块学习(一)
本节大纲: 模块介绍 time &datetime模块 random os sys shutil json & picle shelve xml处理 yaml处理 configpars ...
- Python爬虫——selenium模块
selenium模块介绍 selenium最初是一个测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题 selenium本质是通过驱动浏览器,完全模拟浏览 ...
- Python中Selenium模块的使用
目录 Selenium的介绍.配置和调用 Selenium的配置 Selenium的调用 Selenium的使用 定位 定位元素的使用 定位下拉标签元素 在iframe框架之间切换 上传文件 Webd ...
- day5模块学习 -- os模块学习
python基础之模块之os模块 os模块 os模块的作用: os,语义为操作系统,所以肯定就是操作系统相关的功能了,可以处理文件和目录这些我们日常手动需要做的操作,就比如说:显示当前目录下所有文件/ ...
- Python学习--Selenium模块简单介绍(1)
简介及运行流程 Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozi ...
随机推荐
- el-upload源码跳坑2
产品又加了一个需求,要求删除图片时候弹一个提示框,如果确定就直接发请求从服务器删除图片 一开始想的比较简单,直接在on-remove的钩子函数上做弹框提示,如果取消就撤销,代码如下: <el ...
- Jquery停止动画
stop方法 第一个参数:是否清除动画队列 true | false 第二个参数:是否跳转到动画最终效果 true | false 使用stop()方法的技巧 当下拉菜单和手风琴产生动画队列的问题 ...
- SQL Server复制入门(二)----复制的几种模式
简介 本系列文章的上一篇对复制是什么做了一个概述.本篇文章根据发布服务器,分发服务器和订阅服务器的组织方式和复制类型来讲述常用复制的几种模式. 模式的选择 选择复制的模式取决于多个方面.首先需要考虑具 ...
- C#多线程和线程池[转]
1.概念 1.0 线程的和进程的关系以及优缺点 windows系统是一个多线程的操作系统.一个程序至少有一个进程,一个进程至少有一个线程.进程是线程的容器,一个C#客户端程序开始于一个单独的线程,C ...
- EF批量操作数据与缓存扩展框架
前言 在原生的EF框架中,针对批量数据操作的接口有限,EF扩展框架弥补了EF在批量操作时的接口,这些批量操作包括:批量修改.批量查询.批量删除和数据缓存,如果您想在EF中更方便的批量操作数据,这个扩展 ...
- 【转】SAP HANA学习资料大全[非常完善的学习资料汇总]
Check out this SDN blog if you plan to write HANA Certification exam http://scn.sap.com/community/ha ...
- [android] fragment的动态创建
在一个商业软件中,会有很多的界面,如果没一个界面对应一个activity,那么activity会非常的多,清单文件也会非常的乱,谷歌在android3.0以后引入了新的概念叫fragment frag ...
- [css3] 看博客学习别人的旋转的星球
定义一个div 太阳轨道sunline,边框显示出来,定义position为relative #sunline{ width: 500px; height: 500px; border:2px sol ...
- Docker的下载与安装
一丶下载 1.win10之外的 Docker下载地址: https://www.docker.com/products/docker-toolbox 2.win10 Docker下载地址: https ...
- java自动探测文件的字符编码
Mozilla有一个C++版的自动字符集探测算法代码,然后sourceforge上有人将其改成java版的~~ 主页:http://jchardet.sourceforge.net/ jchardet ...