C#网络爬虫--多线程处理强化版
上次做了一个帮公司妹子做了爬虫,不是很精致,这次公司项目里要用到,于是有做了一番修改,功能添加了网址图片采集,下载,线程处理界面网址图片下载等。
说说思路:首相获取初始网址的所有内容 在初始网址采集图片 去初始网址采集链接 把采集到的链接放入队列 继续采集图片,然后继续采集链接,无限循环
还是上图片大家看一下,在上代码!
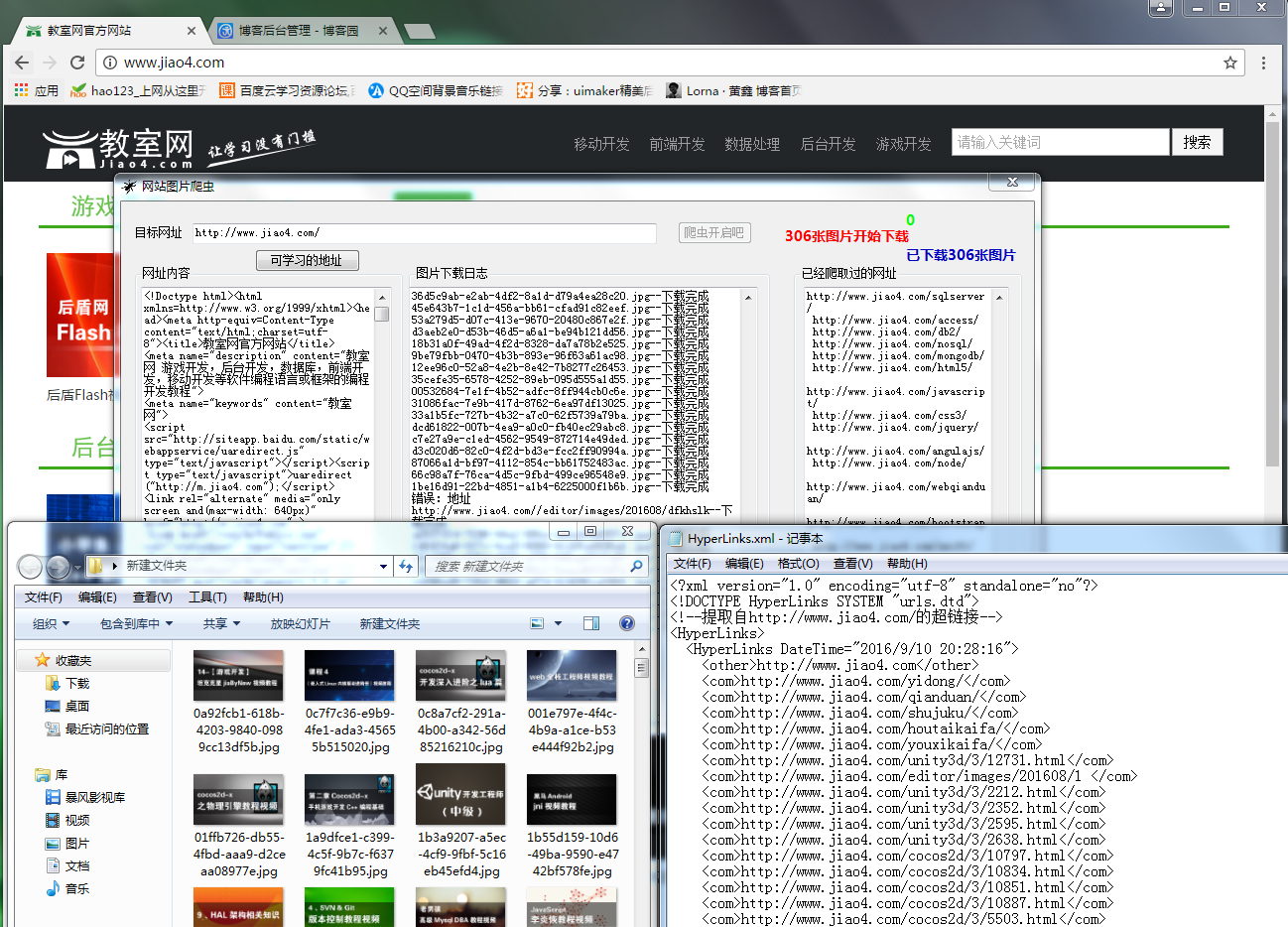
处理网页内容抓取跟网页网址爬取都做了改进,下面还是大家来看看代码,有不足之处,还请之处!
网页内容抓取HtmlCodeRequest,
网页网址爬取GetHttpLinks,用正则去筛选html中的Links
图片抓取GetHtmlImageUrlList,用正则去筛选html中的Img
都写进了一个封装类里面 HttpHelper
/// <summary>
/// 取得HTML中所有图片的 URL。
/// </summary>
/// <param name="sHtmlText">HTML代码</param>
/// <returns>图片的URL列表</returns>
public static string HtmlCodeRequest(string Url)
{
if (string.IsNullOrEmpty(Url))
{
return "";
}
try
{
//创建一个请求
HttpWebRequest httprequst = (HttpWebRequest)WebRequest.Create(Url);
//不建立持久性链接
httprequst.KeepAlive = true;
//设置请求的方法
httprequst.Method = "GET";
//设置标头值
httprequst.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
httprequst.Accept = "*/*";
httprequst.Headers.Add("Accept-Language", "zh-cn,en-us;q=0.5");
httprequst.ServicePoint.Expect100Continue = false;
httprequst.Timeout = ;
httprequst.AllowAutoRedirect = true;//是否允许302
ServicePointManager.DefaultConnectionLimit = ;
//获取响应
HttpWebResponse webRes = (HttpWebResponse)httprequst.GetResponse();
//获取响应的文本流
string content = string.Empty;
using (System.IO.Stream stream = webRes.GetResponseStream())
{
using (System.IO.StreamReader reader = new StreamReader(stream, System.Text.Encoding.GetEncoding("utf-8")))
{
content = reader.ReadToEnd();
}
}
//取消请求
httprequst.Abort();
//返回数据内容
return content;
}
catch (Exception)
{ return "";
}
}
/// <summary>
/// 提取页面链接
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
public static List<string> GetHtmlImageUrlList(string url)
{
string html = HttpHelper.HtmlCodeRequest(url);
if (string.IsNullOrEmpty(html))
{
return new List<string>();
}
// 定义正则表达式用来匹配 img 标签
Regex regImg = new Regex(@"<img\b[^<>]*?\bsrc[\s\t\r\n]*=[\s\t\r\n]*[""']?[\s\t\r\n]*(?<imgUrl>[^\s\t\r\n""'<>]*)[^<>]*?/?[\s\t\r\n]*>", RegexOptions.IgnoreCase); // 搜索匹配的字符串
MatchCollection matches = regImg.Matches(html);
List<string> sUrlList = new List<string>(); // 取得匹配项列表
foreach (Match match in matches)
sUrlList.Add(match.Groups["imgUrl"].Value);
return sUrlList;
} /// <summary>
/// 提取页面链接
/// </summary>
/// <param name="html"></param>
/// <returns></returns>
public static List<string> GetHttpLinks(string url)
{
//获取网址内容
string html = HttpHelper.HtmlCodeRequest(url);
if (string.IsNullOrEmpty(html))
{
return new List<string>();
}
//匹配http链接
const string pattern2 = @"http(s)?://([\w-]+\.)+[\w-]+(/[\w- ./?%&=]*)?";
Regex r2 = new Regex(pattern2, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m2 = r2.Matches(html);
List<string> links = new List<string>();
foreach (Match url2 in m2)
{
if (StringHelper.CheckUrlIsLegal(url2.ToString()) || !StringHelper.IsPureUrl(url2.ToString()) || links.Contains(url2.ToString()))
continue;
links.Add(url2.ToString());
}
//匹配href里面的链接
const string pattern = @"(?i)<a\s[^>]*?href=(['""]?)(?!javascript|__doPostBack)(?<url>[^'""\s*#<>]+)[^>]*>"; ;
Regex r = new Regex(pattern, RegexOptions.IgnoreCase);
//获得匹配结果
MatchCollection m = r.Matches(html);
foreach (Match url1 in m)
{
string href1 = url1.Groups["url"].Value;
if (!href1.Contains("http"))
{
href1 = Global.WebUrl + href1;
}
if (!StringHelper.IsPureUrl(href1) || links.Contains(href1)) continue;
links.Add(href1);
}
return links;
}
这边下载图片有个任务条数限制,限制是200条。如果超过的话线程等待5秒,这里下载图片是异步调用的委托
public string DownLoadimg(string url)
{
if (!string.IsNullOrEmpty(url))
{
try
{
if (!url.Contains("http"))
{
url = Global.WebUrl + url;
}
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Timeout = ;
request.UserAgent = "User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.0.3705";
//是否允许302
request.AllowAutoRedirect = true;
WebResponse response = request.GetResponse();
Stream reader = response.GetResponseStream();
//文件名
string aFirstName = Guid.NewGuid().ToString();
//扩展名
string aLastName = url.Substring(url.LastIndexOf(".") + , (url.Length - url.LastIndexOf(".") - ));
FileStream writer = new FileStream(Global.FloderUrl + aFirstName + "." + aLastName, FileMode.OpenOrCreate, FileAccess.Write);
byte[] buff = new byte[];
//实际读取的字节数
int c = ;
while ((c = reader.Read(buff, , buff.Length)) > )
{
writer.Write(buff, , c);
}
writer.Close();
writer.Dispose();
reader.Close();
reader.Dispose();
response.Close();
return (aFirstName + "." + aLastName);
}
catch (Exception)
{
return "错误:地址" + url;
}
}
return "错误:地址为空";
}
话不多说,更多的需要大家自己去改进咯!欢迎读者来与楼主进行交流。如果本文对您有参考价值,欢迎帮博主点下文章下方的推荐,谢谢
有兴趣可加入企鹅群一起进步:495104593
下面源码送上:嘿嘿要分的哦!
http://download.csdn.net/detail/nightmareyan/9627215
C#网络爬虫--多线程处理强化版的更多相关文章
- C# 多线程网络爬虫
原文 C#制作多线程处理强化版网络爬虫 上次做了一个帮公司妹子做了爬虫,不是很精致,这次公司项目里要用到,于是有做了一番修改,功能添加了网址图片采集,下载,线程处理界面网址图片下载等. 说说思路:首相 ...
- swing版网络爬虫-丑牛迷你采集器2.0
swing版网络爬虫-丑牛迷你采集器2.0 http://www.javacoo.com/code/704.jhtml 整合JEECMS http://bbs.jeecms.com/fabu/3186 ...
- 用Python写网络爬虫 第二版
书籍介绍 书名:用 Python 写网络爬虫(第2版) 内容简介:本书包括网络爬虫的定义以及如何爬取网站,如何使用几种库从网页中抽取数据,如何通过缓存结果避免重复下载的问题,如何通过并行下载来加速数据 ...
- Java版网络爬虫基础(转)
网络爬虫不仅仅可以爬取网站的网页,图片,甚至可以实现抢票功能,网上抢购,机票查询等.这几天看了点基础,记录下来. 网页的关系可以看做是一张很大的图,图的遍历可以分为深度优先和广度优先.网络爬虫采取的广 ...
- Java版网络爬虫基础
网络爬虫不仅仅可以爬取网站的网页,图片,甚至可以实现抢票功能,网上抢购,机票查询等.这几天看了点基础,记录下来. 网页的关系可以看做是一张很大的图,图的遍历可以分为深度优先和广度优先.网络爬虫采取的广 ...
- Atitit.数据检索与网络爬虫与数据采集的原理概论
Atitit.数据检索与网络爬虫与数据采集的原理概论 1. 信息检索1 1.1. <信息检索导论>((美)曼宁...)[简介_书评_在线阅读] - dangdang.html1 1.2. ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用青花瓷抓取网络数据
网络爬虫-使用青花瓷抓取网络数据 由于最近在研究网络爬虫相关技术,刚好看到一篇的的搬了过来! 望谅解..... 写本文的契机主要是前段时间有次用青花瓷抓包有一步忘了,在网上查了半天也没找到写的完整的教 ...
- GJM:用C#实现网络爬虫(二) [转载]
上一篇<用C#实现网络爬虫(一)>我们实现了网络通信的部分,接下来继续讨论爬虫的实现 3. 保存页面文件 这一部分可简单可复杂,如果只要简单地把HTML代码全部保存下来的话,直接存文件就行 ...
- HTTP请求中的User-Agent 判断浏览器类型的各种方法 网络爬虫的请求标示
我们知道,当用户发送一个http请求的时候,浏览的的版本信息也包含在了http请求信息中: 如上图所示,请求 google plus 请求头就包含了用户的浏览器信息: User-Agent:Mozil ...
随机推荐
- WPF设计时
资料太少.中文没有.英文的也残缺不全.待补充.问题暂时解决. 设计器通过使用命名约定来发现自定义设计时程序集 运行时程序集与设计时程序集对应关系 加载顺序 程序集名称(*表示版本号,可省略) 0 ...
- Lerning Entity Framework 6 ------ Defining Relationships
There are three types of relationships in database. They are: One-to-Many One-to-One Many-to-Many Th ...
- python项目实现配置统一管理的方法
一个比较大的项目总是会涉及到很多的参数,最好的方法就是在一个地方统一管理这些参数.最近看了不少的python项目,总结了两种很有意思的配置管理方法. 第一种 基于easydict实现的配置管理 首先需 ...
- Java Listener中Spring接口注入的使用
在项目中使用Spring通常使用他的依赖注入可以很好的处理,接口与实现类之间的耦合性,但是通常的应用场景中都是Service层和DAO层,或者web层的话, 也是与Strust2来整合,那么如何在Li ...
- Swift5 语言指南(二十四) 泛型
通用代码使您能够根据您定义的要求编写可以使用任何类型的灵活,可重用的函数和类型.您可以编写避免重复的代码,并以清晰,抽象的方式表达其意图. 泛型是Swift最强大的功能之一,Swift标准库的大部分内 ...
- C#6.0语言规范(十一) 结构
结构与类类似,因为它们表示可以包含数据成员和函数成员的数据结构.但是,与类不同,结构是值类型,不需要堆分配.结构类型的变量直接包含结构的数据,而类类型的变量包含对数据的引用,后者称为对象. 结构对于具 ...
- Tools - Others
01 - 一些网络工具 文档查阅 https://devdocs.io/ API文档 http://overapi.com/ 开源代码及文档搜索 https://searchcode.com/ 电子书 ...
- 【并发】1、关于线程的几种状态&关于yield的理解
最近在看disruptor源码,在获取ringbuffer的下一个序列的时候,disruptor有几种等待策略,其中有YieldingWaitStrategy类,是使用java的Thread.yiel ...
- 这两周服务器被攻击,封锁了600多个IP地址段后今天服务器安静多了
这两周服务器被攻击,封锁了600多个IP地址段后今天服务器安静多了 建议大家在自己的服务器上也封杀这些瘪三的地址 iptables -I INPUT -s 123.44.55.0/24 -j DROP ...
- Error: insufficient funds for gas * price + value
有位同学今天用 web3+infura 获取 Rinkeby测试网络 的账号信息,报错如下: (node:18356) UnhandledPromiseRejectionWarning: Error: ...