Selenium2+python自动化37-爬页面源码(page_source)
前言
有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息。selenium的page_source方法可以获取到页面源码。
selenium的page_source方法很少有人用到,小编最近看api不小心发现这个方法,于是突发奇想,这里结合python的re模块用正则表达式爬出页面上所有的url地址,可以批量请求页面url地址,看是否存在404等异常
一、page_source
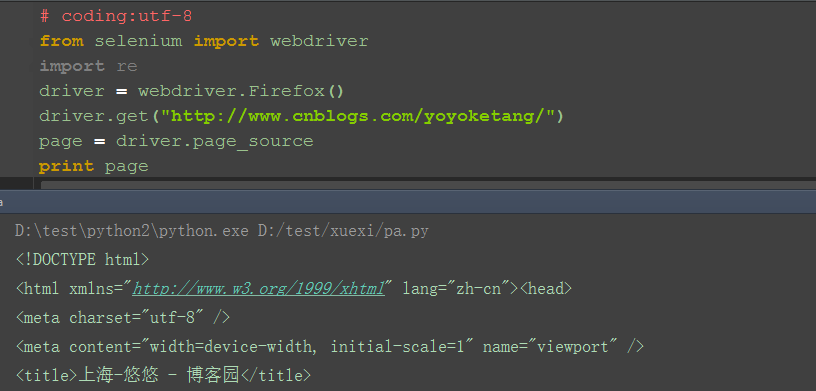
1.selenium的page_source方法可以直接返回页面源码
2.重新赋值后打印出来
二、re非贪婪模式
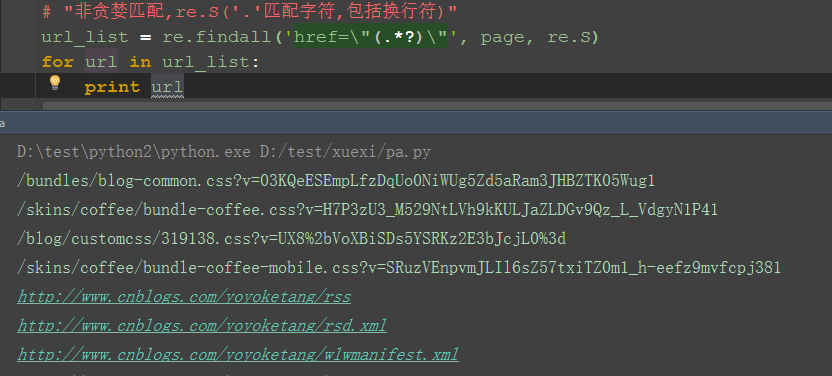
1.这里需导入re模块
2.用re的正则匹配:非贪婪模式
3.findall方法返回的是一个list集合
4.匹配出来之后发现有一些不是url链接,可以删选下
三、删选url地址出来
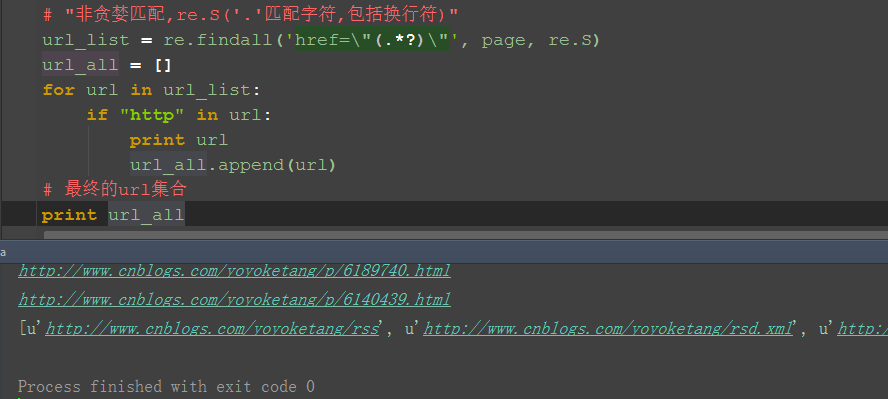
1.加个if语句判断,‘http’在url里面说明是正常的url地址了
2.把所有的url地址放到一个集合,就是我们想要的结果啦
四、参考代码
# coding:utf-8
from selenium import webdriver
import re
driver = webdriver.Firefox()
driver.get("http://www.cnblogs.com/yoyoketang/")
page = driver.page_source
# print page
# "非贪婪匹配,re.S('.'匹配字符,包括换行符)"
url_list = re.findall('href=\"(.*?)\"', page, re.S)
url_all = []
for url in url_list:
if "http" in url:
print url
url_all.append(url)
# 最终的url集合
print url_all
学习过程中有遇到疑问的,可以加selenium(python+java) QQ群交流:646645429
selenium+python高级教程》已出书:selenium webdriver基于Python源码案例
(购买此书送对应PDF版本)

Selenium2+python自动化37-爬页面源码(page_source)的更多相关文章
- selenium3+python3.6爬页面源码的代码
from selenium import webdriver import unittest,time class my_test(unittest.TestCase): def setUp(self ...
- 2.18 爬页面源码(page_source)
2.18 爬页面源码(page_source) 前言有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息.selenium的page_source方法可以获取到页 ...
- Selenium2+python自动化13-Alert
不是所有的弹出框都叫alert,在使用alert方法前,先要识别出它到底是不是alert.先认清楚alert长什么样子,下次碰到了,就可以用对应方法解决.alert\confirm\prompt弹出框 ...
- Selenium2+python自动化64-100(大结局)[已出书]
前言 小编曾经说过要写100篇关于selenium的博客文章,前面的64篇已经免费放到博客园供小伙伴们学习,后面的内容就不放出来了,高阶内容直接更新到百度阅读了. 一.百度阅读地址: 1.本书是在线阅 ...
- Selenium2+python自动化37-爬页面源码(page_source)【转载】
前言 有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息.selenium的page_source方法可以获取到页面源码. selenium的page_sour ...
- UI自动化之特殊处理四(获取元素属性\爬取页面源码\常用断言)
获取元素属性\爬取页面源码\常用断言,最终目的都是为了验证我们实际结果是否等于预期结果 目录 1.获取元素属性 2.爬取页面源码 3.常用断言 1.获取元素属性 获取title:driver.titl ...
- selenium3 + python - page_source页面源码
前言: 有时候通过元素的属性的查找页面上的某个元素,可能不太好找,这时候可以从源码中爬出想要的信息.selenium的page_source方法可以获取到页面源码. 本次以博客园为例,先爬取页面源码, ...
- Selenium2+python自动化39-关于面试的题
前言 最近看到群里有小伙伴贴出一组面试题,最近又是跳槽黄金季节,小编忍不住抽出一点时间总结了下, 回答不妥的地方欢迎各位高手拍砖指点. 一.selenium中如何判断元素是否存在? 首先selen ...
- Selenium2+python自动化39-关于面试的题【转载】
前言 最近看到群里有小伙伴贴出一组面试题,最近又是跳槽黄金季节,小编忍不住抽出一点时间总结了下, 回答不妥的地方欢迎各位高手拍砖指点. 一.selenium中如何判断元素是否存在? 首先selen ...
随机推荐
- 【转】AndroidStudio升到最新版本(3.1.2)之后
AndroidStudio升到最新版本(3.1.2)之后 暂时发现的需要大家注意的地方 1.androidstudio3无法导入moudle? 例如:我写了一个简单的项目,需要导入一个第三方的mo ...
- CCF CSP 201312-3 最大的矩形
CCF计算机职业资格认证考试题解系列文章为meelo原创,请务必以链接形式注明本文地址 CCF CSP 201312-3 最大的矩形 问题描述 在横轴上放了n个相邻的矩形,每个矩形的宽度是1,而第i( ...
- nodejs 项目,请求返回Invalid Host header问题
今天在linux上安装node,使用node做一个web服务器,在linux上安装各种依赖以后开始运行但是,出现了:Invalid Host header 的样式,在浏览器调试中发现是node返回的错 ...
- Django实战(16):Django+jquery
现在我们有了一个使用json格式的RESTful API,可以实现这样的功能了:为了避免在产品列表和购物车之间来回切换,需要在产品列表界面显示购物车,并且通过ajax的方式不刷新界面就更新购物车的显示 ...
- 初始Winsock编程
1.套接字的创建和关闭 使用套接字之前,必须使用socket函数创建一个套接字,此函数调用成功将返回一个套接字句柄. 1 SOCKET socket( 2 int af, //用来指定套接字使用的地址 ...
- sql developer连接mysql
刚刚安装sql developer之后,数据库连接时没有mysql的选项,需要增加一个jar包 mysql-connector-java-6.0.5.zip 工具--->首选项--->数据 ...
- hdoj1171 Big Event in HDU(01背包 || 多重背包)
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=1171 题意 老师有一个属性:价值(value).在学院里的老师共有n种价值,每一种价值value对应着 ...
- grep、find命令整理
一.grep格式: grep [选项]... PATTERN [FILE]...(默认的PATTERN是一个基本的正则表达式(BRE)) 参数选项 1.杂项: -s, --no-messages 不显 ...
- MacBook Apache服务
想着如何在Mac OS下部署静态网页(纯粹的html,css,js),用惯了windows下的iis,可惜Mac OS下也许只能通过Tomcat或者Apache之类的作为部署容器.听说Mac OS下自 ...
- iOS 11开发教程(一)
iOS 11开发概述 iOS 11是目前苹果公司用于苹果手机和苹果平板电脑的最新的操作系统.该操作系统的测试版于2017年6月6号(北京时间)被发布.本章将主要讲解iOS 11的新特性.以及使用Xco ...