机器学习中规范化项:L1和L2
规范化(Regularization)
机器学习中几乎都可以看到损失函数后面会添加一个额外项,常用的额外项一般有两种,一般英文称作ℓ1-norm和ℓ2-norm,中文称作L1正则化和L2正则化,或者L1范数和L2范数。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。下图是Python中Lasso回归的损失函数,式中加号后面一项α||w||1即为L1正则化项。
下图是Python中Ridge回归的损失函数,式中加号后面一项α||w||2即为L2正则化项。
一般回归分析中回归w表示特征的系数,从上式可以看到正则化项是对系数做了处理(限制)。L1正则化和L2正则化的说明如下:
- L1正则化是指权值向量w中各个元素的绝对值之和,通常表示为||w||1
- L2正则化是指权值向量w中各个元素的平方和然后再求平方根(可以看到Ridge回归的L2正则化项有平方符号),通常表示为||w||2
一般都会在正则化项之前添加一个系数,Python中用α表示,一些文章也用λ表示。这个系数需要用户指定。
那添加L1和L2正则化有什么用?下面是L1正则化和L2正则化的作用,这些表述可以在很多文章中找到。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
稀疏模型与特征选择
上面提到L1正则化有助于生成一个稀疏权值矩阵,进而可以用于特征选择。为什么要生成一个稀疏矩阵?
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵,即得到的线性回归模型的大部分系数都是0. 通常机器学习中特征数量很多,例如文本处理时,如果将一个词组(term)作为一个特征,那么特征数量会达到上万个(bigram)。在预测或分类时,那么多特征显然难以选择,但是如果代入这些特征得到的模型是一个稀疏模型,表示只有少数特征对这个模型有贡献,绝大部分特征是没有贡献的,或者贡献微小(因为它们前面的系数是0或者是很小的值,即使去掉对模型也没有什么影响),此时我们就可以只关注系数是非零值的特征。这就是稀疏模型与特征选择的关系。
L1和L2正则化的直观理解
这部分内容将解释为什么L1正则化可以产生稀疏模型(L1是怎么让系数等于零的),以及为什么L2正则化可以防止过拟合。
L1正则化和特征选择
假设有如下带L1正则化的损失函数:
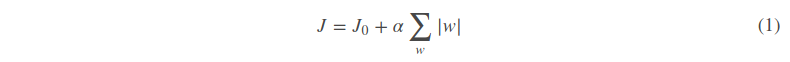
其中J0是原始的损失函数,加号后面的一项是L1正则化项,α是正则化系数。注意到L1正则化是权值的绝对值之和,J是带有绝对值符号的函数,因此JJ是不完全可微的。机器学习的任务就是要通过一些方法(比如梯度下降)求出损失函数的最小值。当我们在原始损失函数J0后添加L1正则化项时,相当于对J0做了一个约束。令L=α∑w|w|,则J=J0+L,此时我们的任务变成在LL约束下求出J0取最小值的解。考虑二维的情况,即只有两个权值w1和w2,此时L=|w1|+|w2|对于梯度下降法,求解J0J0的过程可以画出等值线,同时L1正则化的函数LL也可以在w1w2w1w2的二维平面上画出来。如下图:
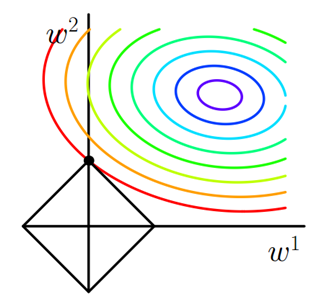
图1 L1正则化
图中等值线是J0的等值线,黑色方形是L函数的图形。在图中,当J0等值线与L图形首次相交的地方就是最优解。上图中J0与L在L的一个顶点处相交,这个顶点就是最优解。注意到这个顶点的值是(w1,w2)=(0,w)。可以直观想象,因为LL函数有很多『突出的角』(二维情况下四个,多维情况下更多),J0与这些角接触的机率会远大于与LL其它部位接触的机率,而在这些角上,会有很多权值等于0,这就是为什么L1正则化可以产生稀疏模型,进而可以用于特征选择。
而正则化前面的系数α,可以控制LL图形的大小。α越小,L的图形越大(上图中的黑色方框);α越大,L的图形就越小,可以小到黑色方框只超出原点范围一点点,这是最优点的值(w1,w2)=(0,w)中的w可以取到很小的值。
类似,假设有如下带L2正则化的损失函数:
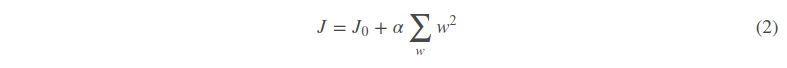
同样可以画出他们在二维平面上的图形,如下:
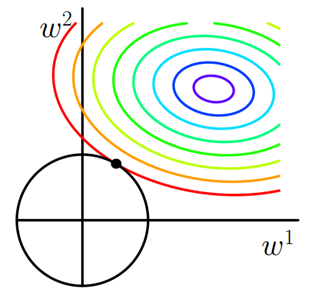
图2 L2正则化
二维平面下L2正则化的函数图形是个圆,与方形相比,被磨去了棱角。因此J0与LL相交时使得w1或w2等于零的机率小了许多,这就是为什么L2正则化不具有稀疏性的原因。
L2正则化和过拟合
拟合过程中通常都倾向于让权值尽可能小,最后构造一个所有参数都比较小的模型。因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是『抗扰动能力强』。
那为什么L2正则化可以获得值很小的参数?
以线性回归中的梯度下降法为例。假设要求的参数为θθ,hθ(x)是我们的假设函数,那么线性回归的代价函数如下:
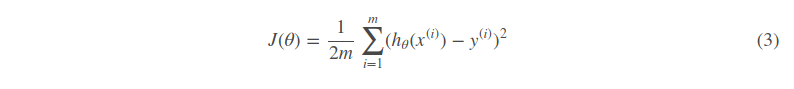
那么在梯度下降法中,最终用于迭代计算参数θθ的迭代式为:
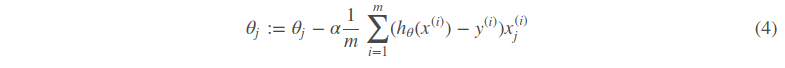
其中α是learning rate. 上式是没有添加L2正则化项的迭代公式,如果在原始代价函数之后添加L2正则化,则迭代公式会变成下面的样子:
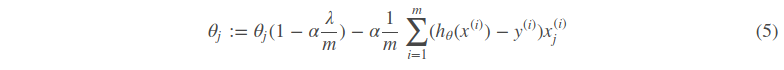
其中λ就是正则化参数。从上式可以看到,与未添加L2正则化的迭代公式相比,每一次迭代,θj都要先乘以一个小于1的因子,从而使得θjθj不断减小,因此总得来看,θ是不断减小的。
最开始也提到L1正则化一定程度上也可以防止过拟合。之前做了解释,当L1的正则化系数很小时,得到的最优解会很小,可以达到和L2正则化类似的效果。
正则化参数的选择
L1正则化参数
通常越大的λλ可以让代价函数在参数为0时取到最小值。下面是一个简单的例子,这个例子来自Quora上的问答。为了方便叙述,一些符号跟这篇帖子的符号保持一致。
假设有如下带L1正则化项的代价函数:
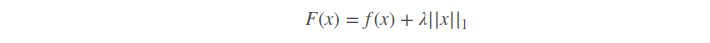
其中x是要估计的参数,相当于上文中提到的w以及θ. 注意到L1正则化在某些位置是不可导的,当λ足够大时可以使得F(x)在x=0时取到最小值。如下图:
图3 L1正则化参数的选择
分别取λ=0.5和λ=2,可以看到越大的λ越容易使F(x)在x=0时取到最小值。
L2正则化参数
从公式5可以看到,λ越大,θj衰减得越快。另一个理解可以参考图2,λ越大,L2圆的半径越小,最后求得代价函数最值时各参数也会变得很小。
机器学习中规范化项:L1和L2的更多相关文章
- 机器学习中正则化项L1和L2的直观理解
正则化(Regularization) 概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. L0正则化 稀疏的参数可以防止 ...
- 神经网络损失函数中的正则化项L1和L2
神经网络中损失函数后一般会加一个额外的正则项L1或L2,也成为L1范数和L2范数.正则项可以看做是损失函数的惩罚项,用来对损失函数中的系数做一些限制. 正则化描述: L1正则化是指权值向量w中各个元素 ...
- 正则化项L1和L2
本文从以下六个方面,详细阐述正则化L1和L2: 一. 正则化概述 二. 稀疏模型与特征选择 三. 正则化直观理解 四. 正则化参数选择 五. L1和L2正则化区别 六. 正则化问题讨论 一. 正则化概 ...
- 正则化项L1和L2的区别
https://blog.csdn.net/jinping_shi/article/details/52433975 https://blog.csdn.net/zouxy09/article/det ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- L1和L2:损失函数和正则化
作为损失函数 L1范数损失函数 L1范数损失函数,也被称之为最小绝对值误差.总的来说,它把目标值$Y_i$与估计值$f(x_i)$的绝对差值的总和最小化. $$S=\sum_{i=1}^n|Y_i-f ...
- 机器学习中的范数规则化 L0、L1与L2范数 核范数与规则项参数选择
http://blog.csdn.net/zouxy09/article/details/24971995 机器学习中的范数规则化之(一)L0.L1与L2范数 zouxy09@qq.com http: ...
- 机器学习中的范数规则化之 L0、L1与L2范数、核范数与规则项参数选择
装载自:https://blog.csdn.net/u012467880/article/details/52852242 今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理 ...
随机推荐
- 从窗口句柄得到菜单句柄(从HWND得到HMENU)
1. 如果HWND是主窗口,可以使用API: GetMenu(...) 得到属于主窗口的句柄,原型如下: HMENU GetMenu(HWND hWnd); 在MFC中原型如下: CMenu* Get ...
- 转:ObjectInputStream类和ObjectInputStream类的使用
ObjectInputStream和ObjectInputStream类创建的对象被称为对象输入流和对象输出流. 创建文件输出流代码: FileOutputStream file_out = new ...
- 团队项目第六周——Alpha阶段项目复审
排名 队名 项目名 优点 缺点 1 大猪蹄子队 四六级背单词游戏 功能开发出来了,界面简洁美观. 功能的确开发出来了,但是还未完成整个程序.不过考虑到开发时长问题,可以理解.页面还是比较简洁,但是测试 ...
- Asp.net Core2.0, 基于 claims 实现权限验证
https://www.cnblogs.com/KimmyLee/p/6430474.html
- Git安全配置
今天收到了阿里云异地登录的短信报警,登录阿里云后台发现,有人从深圳登录了我的服务器(本人在北京),查看详细信息一共登录了5次,前两次是使用的git用户进行登录,后两次已经变成了root用户,怀疑是 ...
- Layui 手册一
icon-图标 1:√2:×3:问号4:锁5:哭脸6:笑脸7:感叹号 使用layer.msg('',{ icon:1 }); 目前只提供7种图标可选,用的适当还是很好看的. 表格刷新 parent. ...
- Basic Auth
开放平台 把网站服务封装成一系列接口供第三方开发者使用,这种行为就叫做Open API,提供开放API的平台本身就被称为开放平台.比如一些网站支持QQ登录,那QQ就相当于开放平台,QQ提供了一些OPE ...
- Ruby for Sketchup 贪吃蛇演示源码(naive_snake)
sketchup是非常简单易用的三维建模软件,可以利用ruby 做二次开发, api文档 http://www.rbc321.cn/api 今天在su中做了一款小游戏 贪吃蛇,说一下步骤 展示 主要思 ...
- 认识与学习shell
linux的终端机执行命令的方式,是通过bash环境来处理的.bash包括变量的设置与使用,.bash操作环境的构建.数据流重定向的功能.下面的知识,对主机的维护与管理有重要的帮助. 管理整个计算机硬 ...
- OpenVswitch mirror 镜像功能
# 从int-br-eth1进入的包镜像一份给dummy0 # 现象:dummy0 可以抓到 int-br-eth1 进入的包 modprobe dummy ip link set up dummy0 ...