python---RabbitMQ(5)消息RPC(远程过程调用)
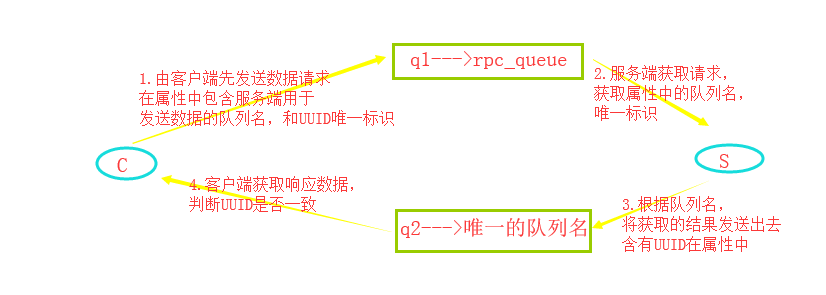
服务器端:
import pika #创建socket
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) #获取通道
channel = connection.channel() #生成队列
channel.queue_declare(queue='rpc_queue') def fib(n):
'''用于获取斐波那契数列'''
if n == :
return
elif n == :
return
else:
return fib(n - ) + fib(n - ) def on_request(ch, method, props, body):
'''获取数据的回调函数'''
n = int(body) print(" [.] fib(%s)" % n)
response = fib(n) ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id= \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag=method.delivery_tag) #设置为空闲的客户端减少压力
channel.basic_qos(prefetch_count=)
#预备开始消费
channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests")
#开始消费,从客户端获取
channel.start_consuming()
客户端:
import pika
import uuid class FibonacciRpcClient(object):
def __init__(self):
#生成socket连接
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
#生成管道连接
self.channel = self.connection.channel()
#获取一个唯一队列名
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
#预备消费,设置回调函数,队列名
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
#注意,在这里不使用start_consuming去获取数据,因为这样会堵塞再这里,我们使用了另一种方法self.connection.process_data_events()
def on_response(self, ch, method, props, body):
print("on_response")
if self.corr_id == props.correlation_id:
self.response = body
def call(self, n):
self.response = None
#生成一个唯一标识符
self.corr_id = str(uuid.uuid4())
#先向服务器端发送数据,传递属性有:唯一队列名和唯一标识符
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to=self.callback_queue,
correlation_id=self.corr_id,
),
body=str(n))
while self.response is None:
print("process_data_events start")
self.connection.process_data_events()
print("process_data_events end")
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call()
print(" [.] Got %r" % response)
注意:
self.connection.process_data_events()会去队列中获取处理数据事件,当数据来临的时候,会直接去调用回调函数去处理数据
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start
process_data_events end
process_data_events start #事件到来
on_response #调用回调函数去处理数据
process_data_events end #事件结束
[.] Got
python---RabbitMQ(5)消息RPC(远程过程调用)的更多相关文章
- rabbitmq(中间消息代理)在python中的使用
在之前的有关线程,进程的博客中,我们介绍了它们各自在同一个程序中的通信方法.但是不同程序,甚至不同编程语言所写的应用软件之间的通信,以前所介绍的线程.进程队列便不再适用了:此种情况便只能使用socke ...
- [译]RabbitMQ教程C#版 - 远程过程调用(RPC)
先决条件 本教程假定 RabbitMQ 已经安装,并运行在localhost标准端口(5672).如果你使用不同的主机.端口或证书,则需要调整连接设置. 从哪里获得帮助 如果您在阅读本教程时遇到困难, ...
- rabbitmq系列五 之远程过程调用(RPC)
1.远程过程调用(RPC) 在第二篇教程中我们介绍了如何使用工作队列(work queue)在多个工作者(woker)中间分发耗时的任务. 可是如果我们需要将一个函数运行在远程计算机上并且等待从那儿获 ...
- .Net RabbitMQ之消息通信 构建RPC服务器
1.消息投递服务 RabbitMQ是一种消息投递服务,怎么理解这句话呢?即RabbitMQ即不是消息的生产者,也是消息的消费者.他就像现实生活中快递模式,消费者在电商网站上下单买了一件商品,此时对应的 ...
- Python RabbitMQ消息队列
python内的队列queue 线程 queue:不同线程交互,不能夸进程 进程 queue:只能用于父进程与子进程,或者同一父进程下的多个子进程,进行交互 注:不同的两个独立进程是不能交互的. ...
- 【python】-- RabbitMQ 队列消息持久化、消息公平分发
RabbitMQ 队列消息持久化 假如消息队列test里面还有消息等待消费者(consumers)去接收,但是这个时候服务器端宕机了,这个时候消息是否还在? 1.队列消息非持久化 服务端(produc ...
- Python之路-python(rabbitmq、redis)
一.RabbitMQ队列 安装python rabbitMQ module pip install pika or easy_install pika or 源码 https://pypi.pytho ...
- python RabbitMQ队列/redis
RabbitMQ队列 rabbitMQ是消息队列:想想之前的我们学过队列queue:threading queue(线程queue,多个线程之间进行数据交互).进程queue(父进程与子进程进行交互或 ...
- Python—RabbitMQ
RabbitMQ RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统 安装 因为RabbitMQ由erlang实现,先安装erlang #安装配置epel源 rpm -ivh http ...
- twsited(5)--不同模块用rabbitmq传递消息
上一章,我们讲到,用redis共享数据,以及用redis中的队列来实现一个简单的消息传递.其实在真实的过程中,不应该用redis来传递,最好用专业的消息队列,我们python中,用到最广泛的就是rab ...
随机推荐
- c# 判断两条线段是否相交(判断地图多边形是否相交)
private void button1_Click(object sender, EventArgs e) { //var result = intersect3(point1, point2, p ...
- javascript 组件化(转载)
这边只是很简陋的实现了类的继承机制.如果对类的实现有兴趣可以参考我另一篇文章javascript oo实现 我们看下使用方法: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ...
- git常用命令复习及其基本使用示例
年后回来新上到项目,对于git的一些操作命令记得有点混乱了,所以特整理笔记如下: 一.git常用命令复习 查看当前分支:git branch (显示结果中带有*号的是当前分支)查看所有分支: git ...
- cxVerticalGrid
cxVerticalGrid can't get values procedure TForm1.Button1Click(Sender: TObject); var i: Integer; lvNa ...
- express和数据库(MySQL)的交互(二)
一.安装express前面都讲了 1.express. cnpm || npm install express --save 2.中间件 a.cnpm || npm install body-pars ...
- TP5 多入口文件配置的坑
闲话不多说,TP5(5.0.20) 在配置多入口文件的时候你是否遇到过一下的问题呢? 开发设计的需求吧网站拆分为前台.后台.API 3 个模块,对应的也需要3个入口文件,后台和API入口文件是用PAT ...
- Json的JsonValueProcessor方法
将对象转换成字符串,是非常常用的功能,尤其在WEB应用中,使用 JSON lib 能够便捷地完成这项工作. JSON lib能够将Java对象转成json格式的字符串,也可以将Java对象转换成xml ...
- sqlserver 对比数据库表是否完全一致的简单方法
1. 使用数据库的工具进行处理 tablediff.exe 工具目录 C:\Program Files\Microsoft SQL Server\\COM 工具使用说明 tablediff.exe - ...
- Windows系统下Log4Net+FileBeat+ELK日志分析系统问题总结
问题如下:1.FileBeat日志报 "dial tcp 127.0.0.1:5544: connectex: No connection could be made because the ...
- Java中LinkedList的fori和foreach效率比较
在<Java中ArrayList的fori和foreach效率比较>中对ArrayList的两种循环方式进行了比较,本次对LinkedList的两种遍历方式进行效率的比较. 1. list ...