Glusterfs初试
Gluster的模式及介绍在此不表,这里只记录安装及配置过程。
1.整体环境
server1 : gfs1.cluster.com
server2 : gfs2.cluster.com
Client:
2.安装Gluster
- 下载软件
https://access.redhat.com/downloads/content/186/ver=3/rhel---7/3.4/x86_64/product-software
下载 Red Hat Gluster Storage Server 3.4 on RHEL 7 Installation DVD
安装RHEL 7.6的最小软件安装,将iso文件mount成cdrom, 然后修改yum源
mkdir -p /repo/base
mount /dev/cdrom /repo/base
vi /etc/yum.repos.d/base.repo
[rhel7.]
name=rhel7.
baseurl=file:///repo/base/
enabled=
gpgcheck=
- 安装
yum install -y redhat-storage-server
systemctl start glusterd
systemctl enable glusterd
systemctl status glusterd验证一下
[root@gfs1 mnt]# systemctl status glusterd
● glusterd.service - GlusterFS, a clustered file-system server
Loaded: loaded (/usr/lib/systemd/system/glusterd.service; enabled; vendor preset: disabled)
Active: active (running) since Fri -- :: CST; 6min ago
Process: ExecStart=/usr/sbin/glusterd -p /var/run/glusterd.pid --log-level $LOG_LEVEL $GLUSTERD_OPTIONS (code=exited, status=/SUCCESS)
Main PID: (glusterd)
Tasks:
CGroup: /system.slice/glusterd.service
├─ /usr/sbin/glusterd -p /var/run/glusterd.pid --log-level INFO
├─ /usr/sbin/glusterfs -s localhost --volfile-id gluster/glustershd -p /var/run/gluster/glustershd/glustershd.pid -l /var/lo...
└─ /usr/sbin/glusterfsd -s gfs1.cluster.com --volfile-id gv0.gfs1.cluster.com.data-gluster-gv0 -p /var/run/gluster/vols/gv0/... Feb :: gfs1.cluster.com systemd[]: Starting GlusterFS, a clustered file-system server...
Feb :: gfs1.cluster.com systemd[]: Started GlusterFS, a clustered file-system server.
- 配置防火墙
简单起见直接关闭了,以后补充开放具体网段
systemctl stop firewalld
systemctl disable firewalld
- 修改主机名以及/etc/hosts
每台机器执行,并修改/etc/hosts
hostnamectl set-hostname gfs1.cluster.com
- 添加存储
在每台glusterfs的server上加入一块存储盘,并进行初始化
fdisk /dev/sdb
mkfs.ext4 /dev/sdb1
在每个节点上运行以下命令挂载
mkdir -p /data/gluster
mount /dev/sdb1 /data/gluster
echo "/dev/sdb1 /data/gluster ext4 defaults 0 0" | tee --append /etc/fstab
3.配置Glusterfs
在节点1上运行
gluster peer probe gfs2.cluster.com
验证
[root@gfs1 mnt]# gluster peer status
Number of Peers: Hostname: gfs2.cluster.com
Uuid: 818cc628-85a7-4f5e-bd4e-34932c05de97
State: Peer in Cluster (Connected) [root@gfs1 mnt]# gluster pool list
UUID Hostname State
818cc628-85a7-4f5e-bd4e-34932c05de97 gfs2.cluster.com Connected
dbcc01fc-3d2c-466f--57c46a9974be localhost Connected
volume和brick的概念
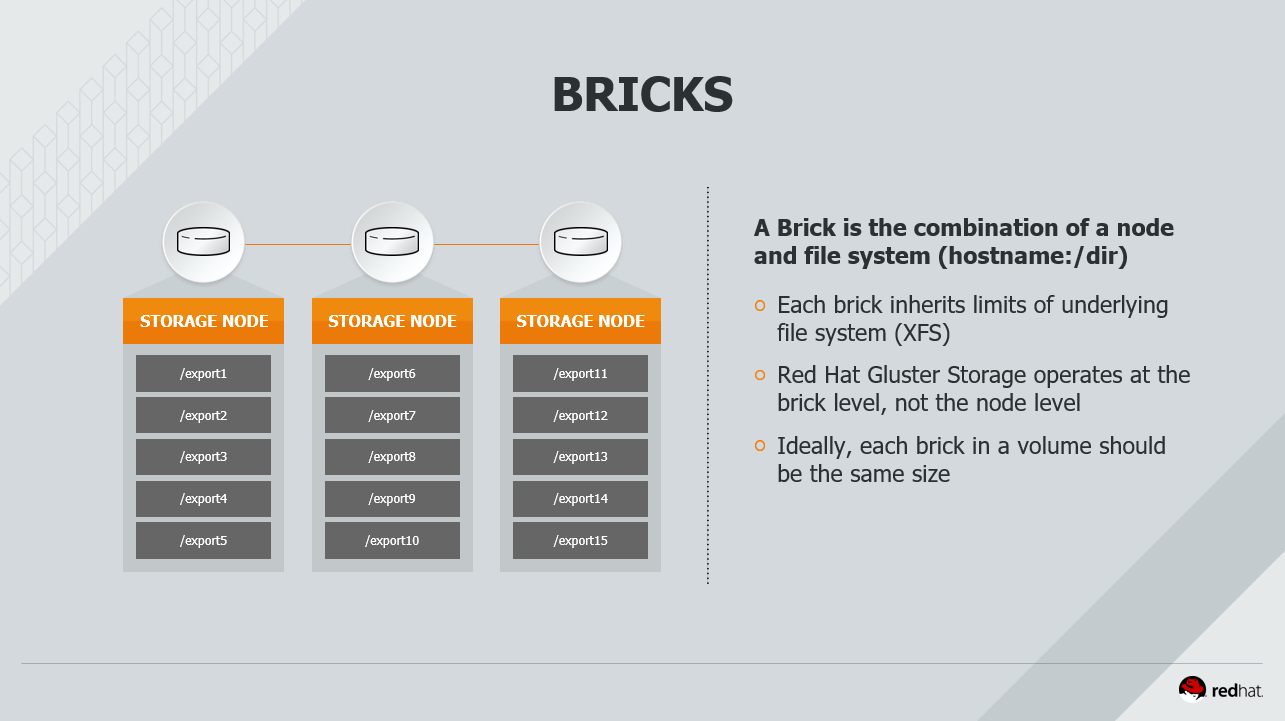
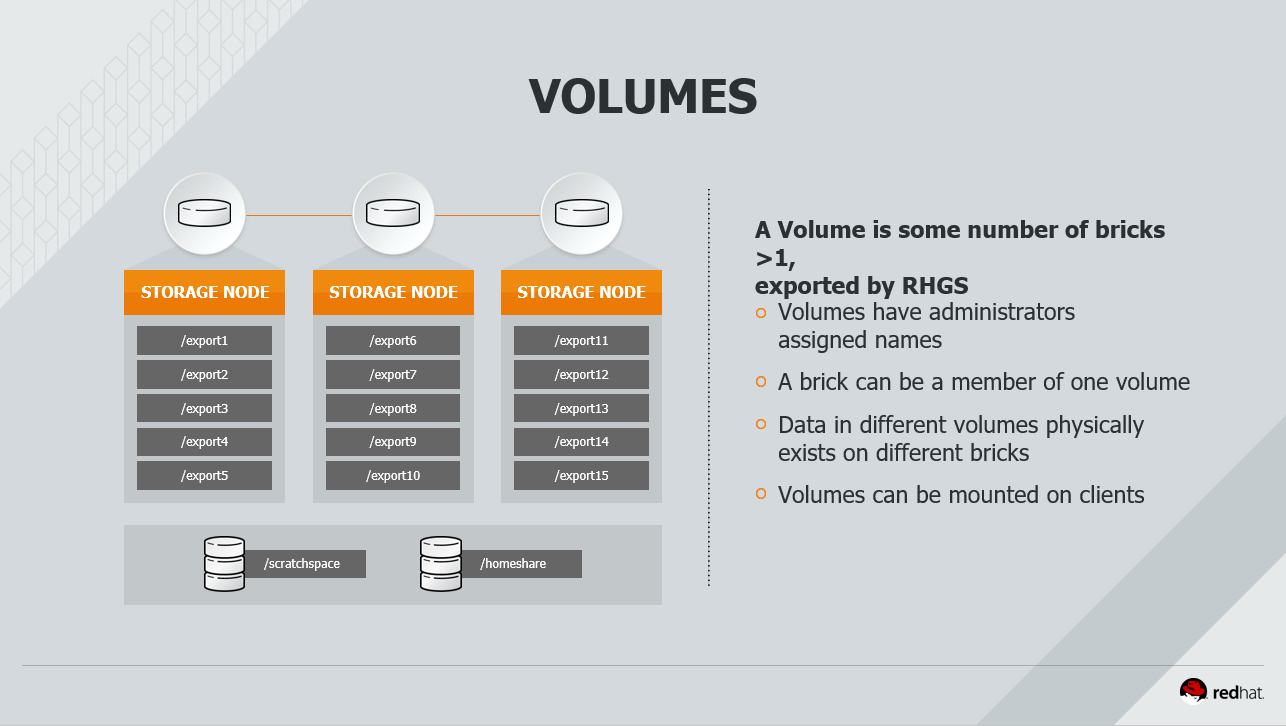
3.1 复制卷
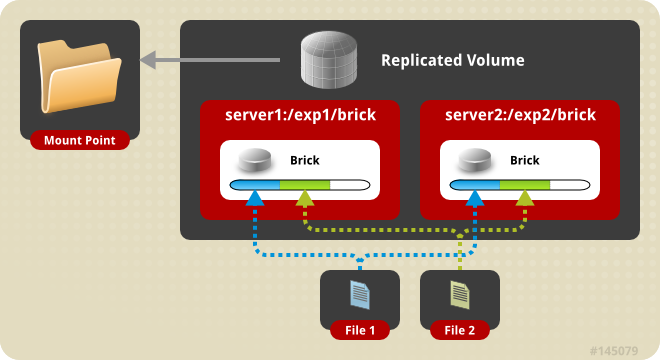
创建GFS卷gv0并配置复制模式
mkdir -p /data/gluster/gv0(在gfs1和gfs2上都建立brick)
gluster volume create gv0 replica gfs1.cluster.local:/data/gluster/gv0 gfs2.cluster.local:/data/gluster/gv0
启动gv0卷
gluster volume start gv0
gluster volume info gv0
[root@gfs1 mnt]# gluster volume info gv0 Volume Name: gv0
Type: Replicate
Volume ID: 26d05ac6---ada4-5a423793fa20
Status: Started
Snapshot Count:
Number of Bricks: x =
Transport-type: tcp
Bricks:
Brick1: gfs1.cluster.com:/data/gluster/gv0
Brick2: gfs2.cluster.com:/data/gluster/gv0
Options Reconfigured:
performance.client-io-threads: off
nfs.disable: on
transport.address-family: inet
3.2 分布式卷(Distributed volume)
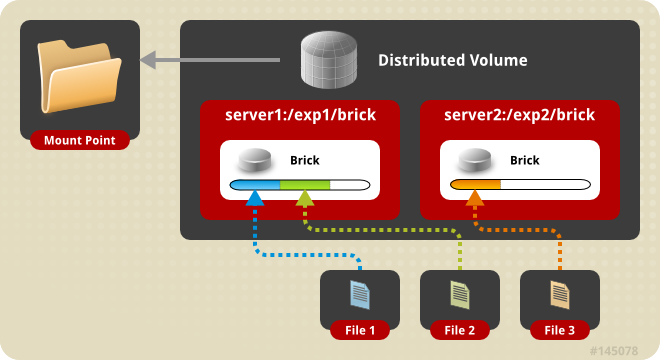
mkdir -p /data/gluster/brick gluster volume create gv1 gfs1.cluster.com:/data/gluster/brick gfs2.cluster.com:/data/gluster/brick gluster volume start gv1
[root@gfs1 mnt]# mkdir -p /data/gluster/brick
[root@gfs1 mnt]# gluster volume create gv1 gfs1.cluster.com:/data/gluster/brick gfs2.cluster.com:/data/gluster/brick
volume create: gv1: success: please start the volume to access data
[root@gfs1 mnt]# gluster volume start gv1
volume start: gv1: success
[root@gfs1 mnt]# gluster volume info gv1 Volume Name: gv1
Type: Distribute
Volume ID: 4782dd87-a411-44b3--70dfb072b5d0
Status: Started
Snapshot Count:
Number of Bricks:
Transport-type: tcp
Bricks:
Brick1: gfs1.cluster.com:/data/gluster/brick
Brick2: gfs2.cluster.com:/data/gluster/brick
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
3.3 条带化卷(Stripe Volume)

mkdir -p /data/gluster/stripebrick gluster volume create gv3 stripe transport tcp gfs1.cluster.com:/data/gluster/stripebrick gfs2.cluster.com:/data/gluster/stripebrick gluster volume start gv3
[root@gfs1 mnt]# mkdir -p /data/gluster/stripebrick
[root@gfs1 mnt]# gluster volume create gv3 stripe transport tcp gfs1.cluster.com:/data/gluster/stripebrick gfs2.cluster.com:/data/gluster/stripebrick
volume create: gv3: success: please start the volume to access data
[root@gfs1 mnt]# gluster volume start gv3
volume start: gv3: success
[root@gfs1 mnt]# gluster volume info gv3 Volume Name: gv3
Type: Stripe
Volume ID: c25a10b8-a943-4c40-93be-088b972cbbaa
Status: Started
Snapshot Count:
Number of Bricks: x =
Transport-type: tcp
Bricks:
Brick1: gfs1.cluster.com:/data/gluster/stripebrick
Brick2: gfs2.cluster.com:/data/gluster/stripebrick
Options Reconfigured:
transport.address-family: inet
nfs.disable: on
3.4 分布式复制卷
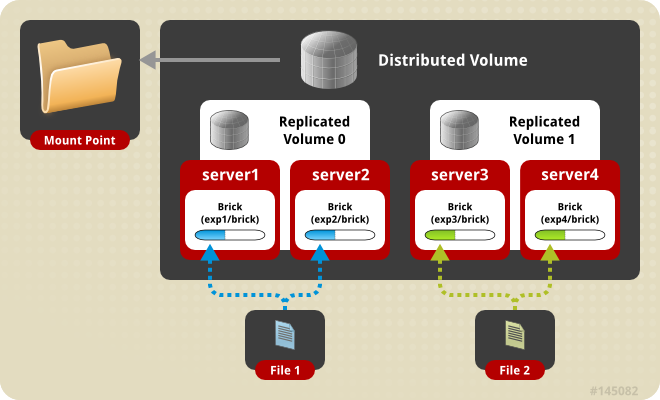
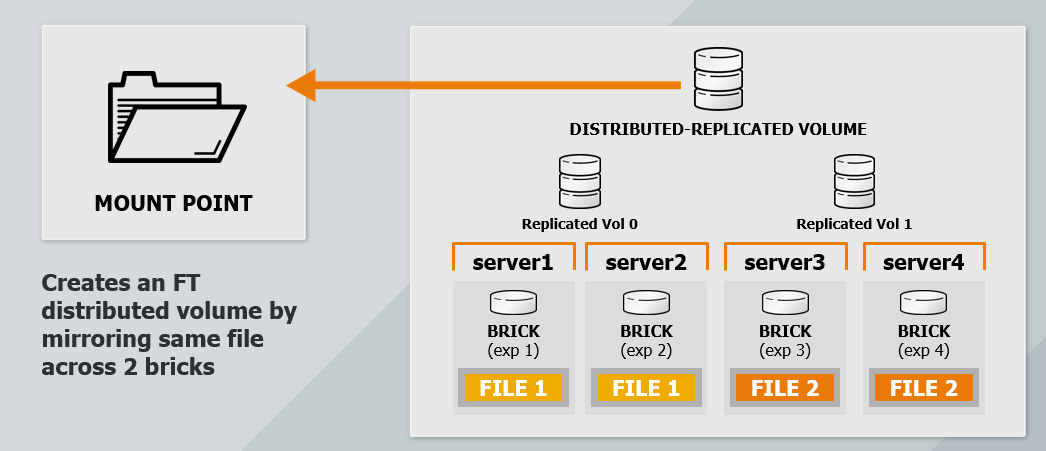
更详细拓扑结构和管理说明参考官方文档,值得你阅读
https://access.redhat.com/documentation/en-us/red_hat_gluster_storage/3/html/administration_guide/
4.客户端配置
支持的客户端协议

yum install -y glusterfs-client
mkdir -p /mnt/glusterfs
mount -t glusterfs gfs1.cluster.com:/gv0 /mnt/glusterfs
验证挂载
[root@master ~]# df -hP /mnt/glusterfs
Filesystem Size Used Avail Use% Mounted on
gfs1.cluster.com:/gv0 .8G 136M .2G % /mnt/glusterfs
在node1和node2上也mount上glusterfs gv0,便于查看里面内容
[root@gfs1 ~]# mount -t glusterfs gfs2.cluster.com:/gv0 /mnt
[root@gfs2 ~]# mount -t glusterfs gfs1.cluster.com:/gv0 /mnt
然后基于客户端进行文件创建删除,同时将node1进行停机的高可用测试。
Glusterfs初试的更多相关文章
- CentOS 6 部署GlusterFS
首先需要关闭CentOS的防火墙和selinux,否则glusterfs将可能无法正常工作. /etc/init.d/iptables status 会得到一系列信息,说明防火墙开着. /etc/in ...
- Ubuntu Server 12.04下部署glusterfs
1.安装环境 Linux:Ubuntuserver 12.04.1 LTS 64bit 2台 分布式文件系统:Gluster 测试环境:一台作文件服务器端(192.168.56.133),一台作客户端 ...
- glusterFS系统中文管理手册(转载)
GlusterFS系统中文管理手册 1文档说明 该文档主要内容出自 www.gluster.org 官方提供的英文系统管理手册<Gluster File System 3.3.0 A ...
- caffe初试(一)happynear的caffe-windows版本的配置及遇到的问题
之前已经配置过一次caffe环境了: Caffe初试(一)win7_64bit+VS2013+Opencv2.4.10+CUDA6.5配置Caffe环境 但其中也提到,编译时,用到了cuda6.5,但 ...
- centos7 搭建GlusterFS
centos7 搭建GlusterFS 转载http://zhaijunming5.blog.51cto.com/10668883/1704535 实验需求:4台机器安装GlusterFS组成一个集群 ...
- glusterfs 中的字典查询
glusterfs文件系统是一个分布式的文件系统,但是与很多分布式文件系统不一样,它没有元数服务器,听说swift上也是应用了这个技术的.glusterfs中每个xlator的配置信息都是用dict进 ...
- glusterfs 内存管理方式
glusterfs中的内存管理方式: 首先来看看glusterfs的内存管理结构吧: struct mem_pool { struct list_head list; int hot_count; i ...
- 初试Nodejs——使用keystonejs创建博客网站2(修改模板)
上一篇(初试Nodejs——使用keystonejs创建博客网站1(安装keystonejs))讲了keystonejs的安装.安装完成后,已经具备了基本的功能,我们需要对页面进行初步修改,比如,增加 ...
- 项目中初试PHP单元测试
只能叫初试,前面虽然做了一些PHPUnit与团队所用框架的整合,但在整个团队还没有人可以主动推动这个事情,而作为Leader最重要的一种能力应该是"让正确的事情发生",所以今天开始 ...
随机推荐
- 【转】TCP建立连接三次握手和释放连接四次握手
在谈及TCP建立连接和释放连接过程,先来简单认识一下TCP报文段首部格式的的几个名词(这里只是简单说明,具体请查看相关教程) 序列号seq:占4个字节,用来标记数据段的顺序,TCP把连接中发送的所有数 ...
- 2017-2018 ACM-ICPC, NEERC, Moscow Subregional Contest B - Byteland Trip dp
B - Byteland Trip 题目大意:给你一个由'<' 和 '>'组成的串, 如果在'<' 只能前往编号比它小的任意点, 反之只能前往比它大的任意点,问你能遍历所有点 并且每 ...
- mysql单表多timestamp报错#1293 - Incorrect table definition; there can be only one TIMESTAMP column with CURRENT_TIMESTAMP in DEFAULT or ON UPDATE clause
一个表中出现多个timestamp并设置其中一个为current_timestamp的时候经常会遇到#1293 - Incorrect table definition; there can be o ...
- html5+css3 h5页面生成的思路
<!DOCTYPE html><html style="height: 100%;"> <head> <meta charset=&quo ...
- Python入门2(Python与C语言语法的不同、Notepad++运行Python代码)
本篇博客主要介绍Python的基本语法与C语言不同的地方 [不同] 一.Python代码需要有严格的缩进,即C语言中所谓的良好的编码习惯.缩进不正确就会报错. 二.C语言需要圆括号 三.C语言每个语句 ...
- C++ 基础 杂类
1.set: 基本上跟map是相同(只有一个键),set是key-value 放在一起,map 是分开的,既然都加key ,所以set<> 的内容不可能有重复的情况出现 example: ...
- Extjs设置或获取cookie
设置cookie var myCookie = Ext.util.Cookie.set(‘YourCookieName’,'YourValue’); 读取cookie Ext.util.Cookie. ...
- UVALive - 6912 Prime Switch (状压DP)
题目链接:传送门 [题意]有n个灯,m个开关,灯的编号从1~n,每个开关上有一个质数,这个开关同时控制编号为这个质数的倍数的灯,问最多有多少灯打开. [分析]发现小于根号1000的质数有10个左右,然 ...
- Linux软件管理(rpm、yum、tar)
RPM软件包安装 YUM安装 源代码安装 TAR包管理:实现对文件的备份和压缩 rpm包管理 rpm命令是RPM软件包的管理工具. -a:查询所有套件:-b<完成阶段><套件档> ...
- 1025 PAT Ranking (25)(25 point(s))
problem Programming Ability Test (PAT) is organized by the College of Computer Science and Technolog ...